1. Review:梯度下降法
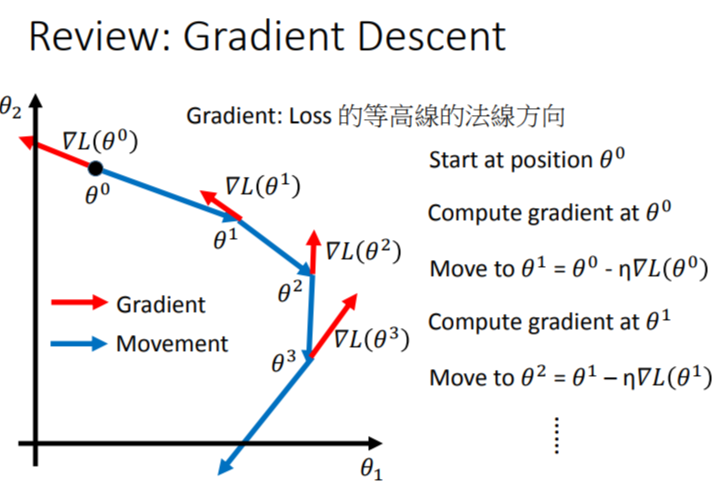
我们建立一个模型,需要为这个模型找到一组参数,这个参数可以最小化\(Loss\).我们使用梯度下降法来找到这个参数.注意,下图的\(▽L\)就是梯度.

梯度下降以可视化表现如下:
2. 梯度下降的tips
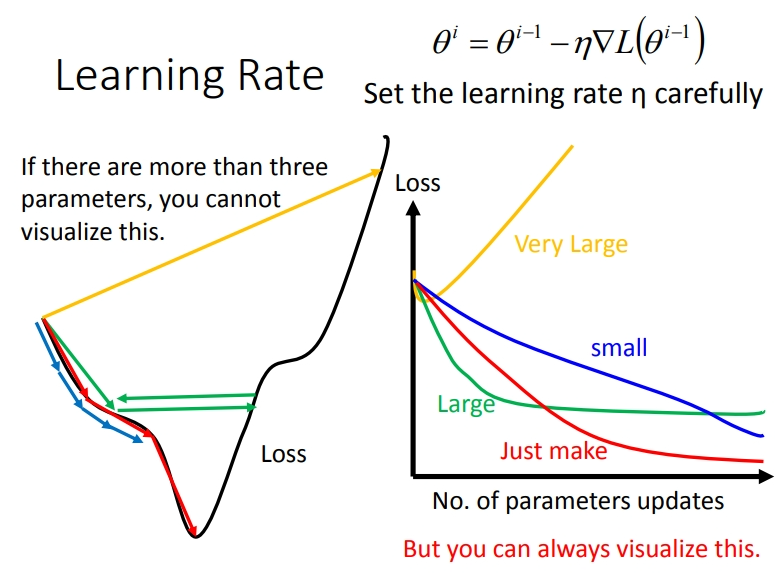
2.1 小心调整lr
学习率控制梯度下降速度.
2.2 自适应学习率
学习率的调整是很麻烦的,但也有一些\(ideas\),在初始的时候,离局部最小点比较远,此时的学习率会比较大,但随着\(epochs\)进行,学习率会逐渐减小.比如设置成\(\eta^t = \frac{\eta}{\sqrt{t+1}}\).但这只是一种情况,最好的情况是每个不同的参数都给予不同的学习率.

2.3 Adagrad
这个算法让每个参数的学习率都把它除上之前微分的均方根.
-
对于普通的梯度下降,我们要控制它的学习率,可能会这样做:

-
但Adagrad可以做得更好:

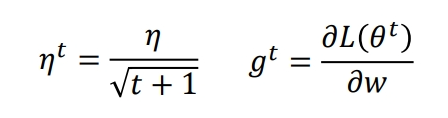
那么之前微分的均方根到底是什么意思呢?举个例子就明白了.请注意\(\eta\)的式子就是上面的式子,同理\(g\).

总结一下,就是下面这个式子:

这只是Adagrad算法的其中之一的方法,还有很多属于Adagrad的算法,比如大名鼎鼎的\(Adam\)算法.
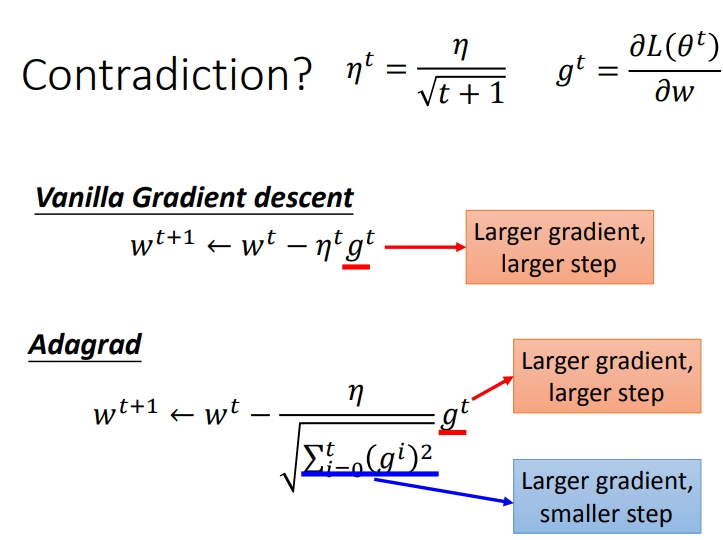
2.3.1 Adagrad存在的矛盾
在\(Adagrad\)中,当梯度越大时,步伐应该越大,但是分母又导致当梯度越大的时候,步伐越小.
有\(paper\)给了直观解释,我个人有点理解不了为什么给予这种反差,这是一位\(po\)主的笔记.


李宏毅老师也给了自己的解释.下面是其他博主对李老师观点的总结,最好的步伐与该点的梯度成正比,当梯度越大,说明这个点与最低点也越远:

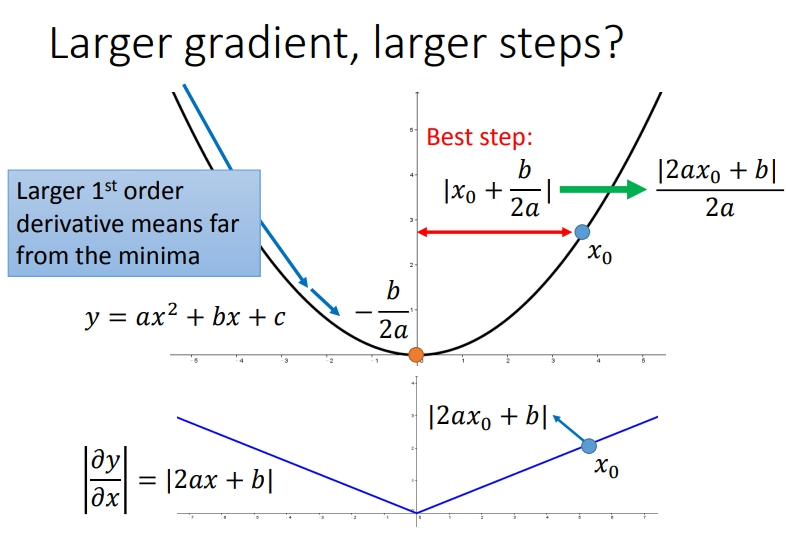
考虑多个参数的时候,情况又是不同的.从下图是两个参数与Loss之间的关系图.
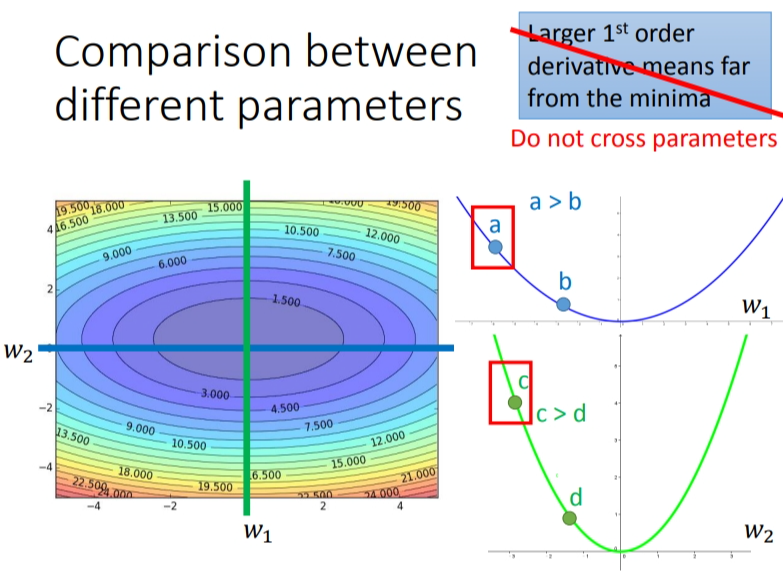
如果我们只考虑\(w_1\),也就是只看蓝色那条线,那么\(a\)的梯度大于\(b\)的梯度,\(a\)离最低点越远.同理绿色那条线.但如果我们对比\(a\)对\(w_1\)的微分,\(c\)对\(w_2\)的微分,这个结论又不成立了.但如果我要考虑多个参数,到底应该怎么想呢?