Anomaly Detection with Score Distribution Discrimination
1 Introduction
如图1所示。Fig 1a~1c。这些方法基于学习到的输入数据的特征转换(如重构误差或embedding距离),生成异常分数。然而,在表示空间中的优化会导致数据效率低下的学习和次优异常评分。
Fig 1d~1e使用端到端的异常分数学习。然而,这样一个预定义的分数目标或边际会限制模型对不同数据集的适应性,并且考虑到实际AD场景中标记数据的稀缺性,进一步调整这些超参数以实现适应性通常是困难的。
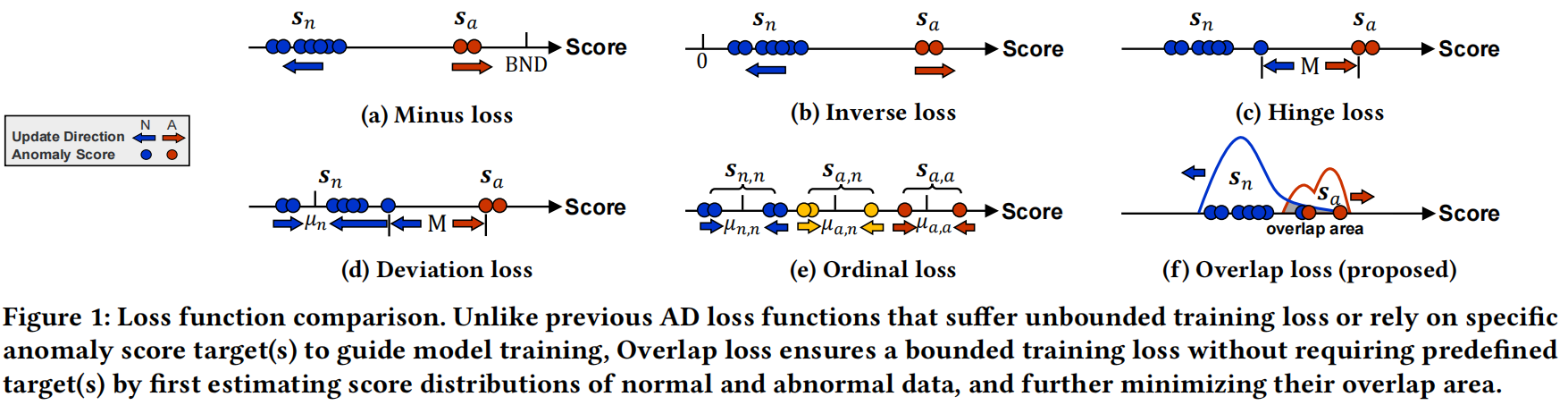
在本文中,我们的目标是涉及一种能够实现对不同数据场景的自适应异常评分判别的异常评分函数,从而解决以往异常信息损失函数中存在的上述问题。
我们设计了重叠损失,使正常样本和异常之间的分数分布重叠最小化,依赖于模型本身来决定输出异常分数的适当分布。这种适应性消除了对预定义异常分数目标的依赖。我们设计了一种简单有效的方法来估计任意分数分布的重叠区域,同时保证输出异常分数的正确顺序和训练损失的有界性,从而更好地实现模型训练的稳定性。
贡献
- 我们提出了重叠损失,它可以在输入数据中实现自适应分数分布判别,以端到端梯度更新的方式实现对异常分数的充分全局洞察。
- 我们在涵盖AD和分类任务的几个网络架构上验证了所提出的重叠损失的有效性。在25个数据集上的广泛结果表明,提出的重叠损失可以作为进一步开发AD任务的基础。
- 我们解耦了几种流行的AD算法的损失函数,并在一个统一的框架中分析了它们,包括嵌入变化和网络参数变化。此外,我们还研究了不同损失函数对不同类型异常的检测性能,从而进一步探讨了这些方法的优缺点。
2 RELATED WORK
AD Algorithms without Supervision
shallow unsupervised models:CBLOF、ECOD
ensemble method:IForest
deep learning:DeepSVDD、GAN-based MOGAAL
AD Algorithms with Supervision
-
AD方法仅在标记的正常样本上进行训练,并检测偏离训练过程中学习到的正常表示的异常
-
半监督和弱监督的AD方法。它们不仅从大量未标记数据中学习,还利用了有限数量的标记异常样本的信息。
基于表示学习的AD方法:Unlearning、DeepSAD、REPEN
异常分数的端到端学习:DevNet、FEAWAD 、PReNet
-
通常情况下,完全监督的方法并不特定于异常检测(AD)任务
以前的研究通常使用现有的二元分类器,如Random Forest和MLP,来进行异常检测。
上述一些基于异常信息的方法进行了异常分数的间接表示学习,而其他方法主要依赖于预定的训练目标,以实现正常和异常数据之间的分数差异。
我们提出的Overlap loss通过分布视角自适应地实现了分数差异,因此减轻了在模型训练中定义超参数作为异常分数目标的需求。这种方法的优势在于可以更灵活地适应不同数据分布,而无需事先确定目标分数。
Distribution Overlap
计算机视觉领域最近关于离群分布(OOD)或多分类任务的一些研究通常将类别分布的重叠仅仅作为一种衡量数据集特征或评估模型质量的方式
Magnet loss 提出通过惩罚类别分布的重叠来实现局部区分,从而在表示空间中明确地建模不同类别的分布。基于熵最小化原理,MA-DNN在特征空间中最小化模型熵,并惩罚类别级别上网络预测的不一致性。然而,这两种方法主要设计用于距离度量学习(DML),其优化发生在表示空间中。
我们提出直接优化异常分数空间中的分布重叠,以实现对输入实例的自适应分数分布区分。
3 METHODOLOGY
3.1 Problem Statement
假设训练数据集 \(\mathcal{D}=\left\{x_1^n, \ldots, x_k^n,\left(x_{k+1}^a, y_{k+1}^a\right), \ldots\right.\), \(\left.\left(x_{k+m}^a, y_{k+m}^a\right)\right\}\) 收集了既包括未标记实例 \(\mathcal{D}_n=\left\{x_i^n\right\}_{i=1}^k\),又包括少量标记异常 \(\mathcal{D}_a=\left\{\left(x_j^a, y_j^a\right)\right\}_{j=1}^m\),其中 \(x \in \mathbb{R}^d\) 表示输入特征,\(y_j^a\) 是已识别异常的标签。通常情况下,\(m \ll k\),因为只有有限的异常先验知识可用。这种数据假设对于异常检测问题(AD)更为实际,并且在最近的研究中得到了研究。
在给定这样的数据集后,我们的目标是训练一个模型,有效地为异常数据分配更高的异常分数。也就是说,我们的目标是创建一个模型,它能够识别出标记的异常数据并为其分配较高的分数,以便在异常检测任务中更好地区分异常和正常数据。
3.2 Overview of the Proposed Overlap Loss
Overlap loss首先使用 Score Distribution Estimator 来估计神经网络中输出异常分数的未知概率密度函数(PDF),然后在未标记样本和标记异常的异常分数分布之间进行 Overlap Area Calculation 。最后,Overlap loss最小化计算得的分数分布重叠区域,以提供神经网络中的反向传播梯度。提出的Overlap loss具有以下属性:
- 为了更好地实现模型训练的收敛性,训练损失具有有界性。这有助于确保训练过程更加稳定。
- 消除了异常分数的显式训练目标(例如,常数或边界超参数),以增强模型对不同数据集的适应性。
- 优化整个异常分数分布,而不是仅仅针对估计的异常分数与其相应目标之间的单点优化。
3.3 Overlap Loss for Score Distribution Discrimination
在接下来的子章节中,我们将说明提出的Overlap loss的两个主要部分:Score Distribution Estimator 和 Overlap Area Calculation,以及它们的基本思想和挑战。
3.3.1 Score Distribution Estimator
与点对点优化输出异常分数不同,我们考虑从分布视角优化异常分数。假设 \(Q \in \mathbb{R}^M\) 是隐空间,端到端的异常评分网络 \(\phi(\cdot ; \Theta): x \mapsto \mathbb{R}\) 可以定义为特征表示学习器 \(\psi\left(\cdot ; \Theta_t\right): x \mapsto Q\) 和异常评分函数 \(\eta\left(\cdot ; \Theta_s\right): Q \mapsto \mathbb{R}\) 的组合,其中 \(\Theta=\left\{\Theta_t, \Theta_s\right\}\)。如果我们将正常数据的异常分数表示为 \(\phi\left(x^n ; \Theta\right)=s_n\),将异常数据的异常分数表示为 \(\phi\left(x^a ; \Theta\right)=s_a\),则在训练批次中应用密度估计器 \(f(\cdot)\) 来估计 \(s_n\) 和 \(s_a\) 的概率密度函数(PDF)。
一个直接的想法是使用先验分布,例如高斯分布,作为分数分布估计器。高斯分布具有一些良好的性质。例如,在图2a中用于估计分数分布重叠的交点 \(c\) 可以通过以下公式 [25] 计算:
其中,\(\mu\) 和 \(\sigma\) 分别是它们对应的分数分布的均值和方差。这个基本思想的主要挑战是,通常情况下,标记的异常数量太少,无法满足根据中心极限定理 [8] 对高斯分布的假设。同时,强制异常分数遵循这种高斯先验会限制神经网络的表示能力,进一步扭曲异常评分空间,导致性能次优。这意味着高斯分布并不适合用于表示异常分数的真实分布情况。

为了应对上述挑战,我们采用了一种能够估计输出异常分数任意分布的得分分布估计器。在本文中,我们使用非参数的核密度估计(KDE)方法来估计可能由于标记数据稀缺或未标记数据中的异常污染而引起的任意异常分数分布。实际上,其他可微分的密度估计器也可以应用到我们提出的Overlap loss中。
如果我们将输出的异常分数表示为 \(\phi(x ; \Theta)=s\),那么经验累积分布函数(ECDF)可以定义为 \(\hat{F}_N(s)=\frac{1}{N} \sum_{i=1}^N \mathbf{1}_{s_i \leq s}\),其中 \(\mathbf{1}\) 是指示函数,\(N\) 是分区的数量。\(\hat{F}_N(s)\) 是累积分布函数(CDF)\(F(s)\) 的无偏估计器 [12],可以进一步用于通过以下方程估计PDF:
其中 \(h\) 是带宽(bandwidth)。如果我们将核函数表示为 \(K(s)=\frac{1}{2} 1(s \leq 1)\),则估计的PDF可以重写为:
其中\(K(\cdot)\)是对称的。
在Kernel Density Estimation(KDE)中,我们使用了高斯核函数,即 \(K(s ; h) \propto \exp \left(-\frac{s^2}{2 h^2}\right)\),来估计异常分数的未知PDF。PDFs 进一步用于计算分数分布的重叠区域,如下面的子节中所述。
3.3.2 Overlap Area Calculation
一旦我们获得了估计的分数分布(即PDFs),分数分布的重叠可以被计算为正常样本和异常样本之间PDFs的重叠面积。
一种可选的方法是直接使用积分来近似分数分布的重叠,如方程4所示。\(s_n\) 和 \(s_a\) 的PDFs之间的重叠面积被公式化为具有较小概率密度的PDF的积分:
上述基本思想的主要挑战是,这种方法不一定能够保证异常分数的正确梯度更新方向,如图2b所示。神经网络可能会最小化分数分布的重叠面积,同时错误地将异常的分数分配给异常数据(例如,图2b中异常分布的左侧),而不是正常数据。通过将方程4与ranking loss term 结合成多任务学习形式,可以解决这个问题,如方程5所示。然而,尽管它确保了异常分数的顺序,即异常数据的异常分数应该更高地排在正常数据之前,但这种方法可能会在多任务学习中面临困难的优化问题,有时导致与单独学习任务相比性能较差和数据效率低下 。
我们提出的Overlap loss 旨在计算任意分数分布的重叠区域,同时确保异常分数的正确顺序。我们设法获取这些任意分数分布的交点 \(c\)(参见图2c),在训练批次中,\(s_n\) 和 \(s_a\) 之间的分数分布重叠可以进一步公式化为方程6,其中 \(\hat{F}_{s_n}(\cdot)\) 和 \(\hat{F}_{s_a}(\cdot)\) 分别是正常数据和异常数据的估计CDF。
如图2c所示,公式6中的Overlap loss确保了输出异常分数的顺序。具有正确顺序的小重叠区域意味着 \(O\left(s_n, s_a\right)\) 接近零损失。如果异常数据的异常分数小于正常数据的异常分数,\(O\left(s_n, s_a\right)\) 将对这种不一致进行惩罚,并接近2,因为 \(P\left(s_n>c\right)\) 和 \(P\left(s_a<c\right)\) 分别接近1。此外,由于PDF的属性,\(O\left(s_n, s_a\right)\) 在 \([0,2]\) 范围内自然有界。
然而,对于两个任意的分数分布,我们不能直接使用公式1适用于高斯分布的公式来计算交点 \(c\)。相反,对于任意分数分布情况,我们通过公式7中的非零元素 \(d_k^s\) 的相应 \(\mathrm{x}\) 值来获得交点 \(c\),其中 \(s_k\) 由算术序列生成 \(s_k=\min \left(s_n, s_a\right)+(k-1) \frac{\max \left(s_n, s_a\right)-\min \left(s_n, s_a\right)}{N}\),\(k=1, \ldots, N\)。换句话说,我们比较了分数分布 \(s_a\) 和 \(s_n\) 之间的相邻点的PDF差,如图3所示。
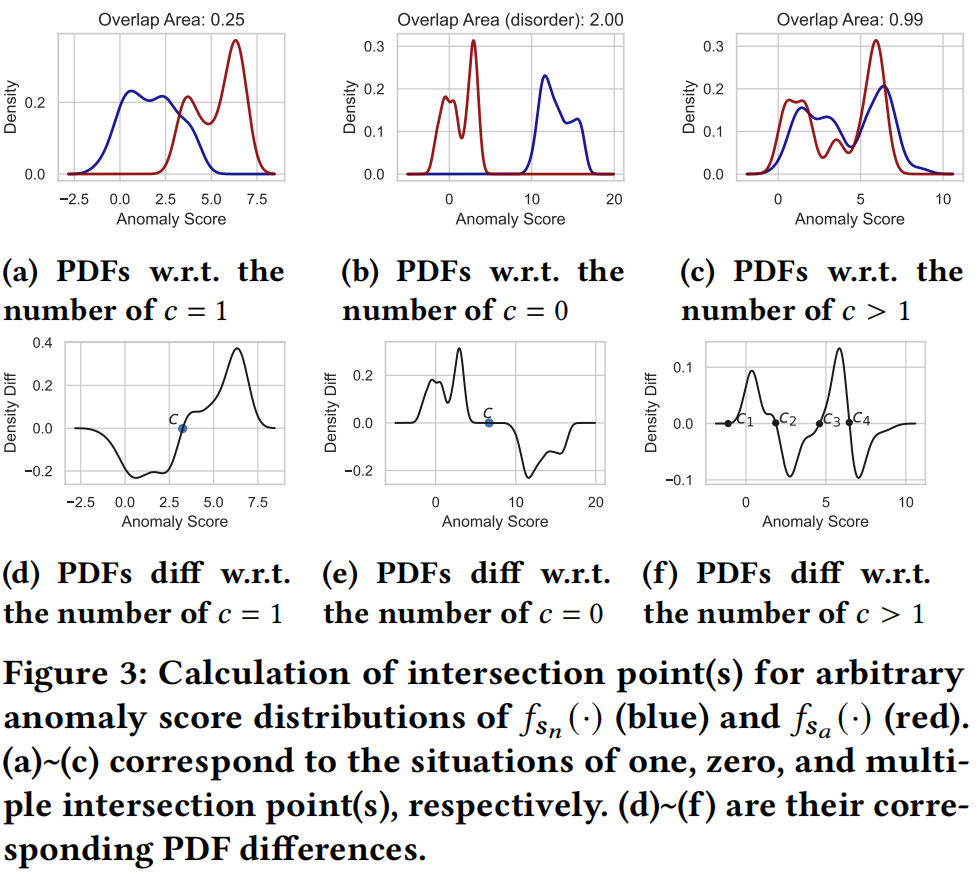
图3展示了计算交点 \(c\) 的示例。对于大多数情况,\(\hat{f}_{s_n}(\cdot)\) 和 \(\hat{f}_{s_a}(\cdot)\) 之间只有一个交点时,\(c\) 被视为PDF差的符号变化点的 \(\mathrm{x}\) 值,如图3a和3d所示。即使两个分数分布相距较远(见图3b),我们仍然可以扩展它们的PDF的 \(\mathrm{x}\) 范围并获得 \(c\),如图3e所示。值得注意的是,对于图3b中的情况,Overlap loss 将达到其上界,重叠区域为2,以惩罚估计的异常分数的不一致性,如公式6所示。对于存在多个交点的情况(如图3c和3f所示),我们随机选择其中一个作为 \(c\)。在附录中,我们展示了这种策略的检测性能非常接近于合并不同交点的性能,同时提高了模型训练的效率。
然后,可以通过梯形法则 [10] 近似计算 \(\mathrm{CDF}\ F_s(c)\) 的积分,如公式8所示,其中 \(\Delta s_k\) 根据交点调整为 \(\Delta s_k=\left[c-\min \left(s_n, s_a\right)\right] / N\)。
综上所述,Overlap loss 定义如下:
3.4 Network Architecture
Overlap loss被实例化为一个端到端的神经网络,该网络包括一个特征表示层 \(\psi\left(\cdot ; \Theta_t\right)\) 和一个评分层 \(\eta\left(\cdot ; \Theta_s\right)\)。在评分层之后应用了BatchNorm层以对输出的异常分数进行标准化。之后,通过KDE估计器估计正常数据和异常数据的分数分布,进一步通过提出的Overlap loss来计算它们的分数分布重叠,如图4所示。
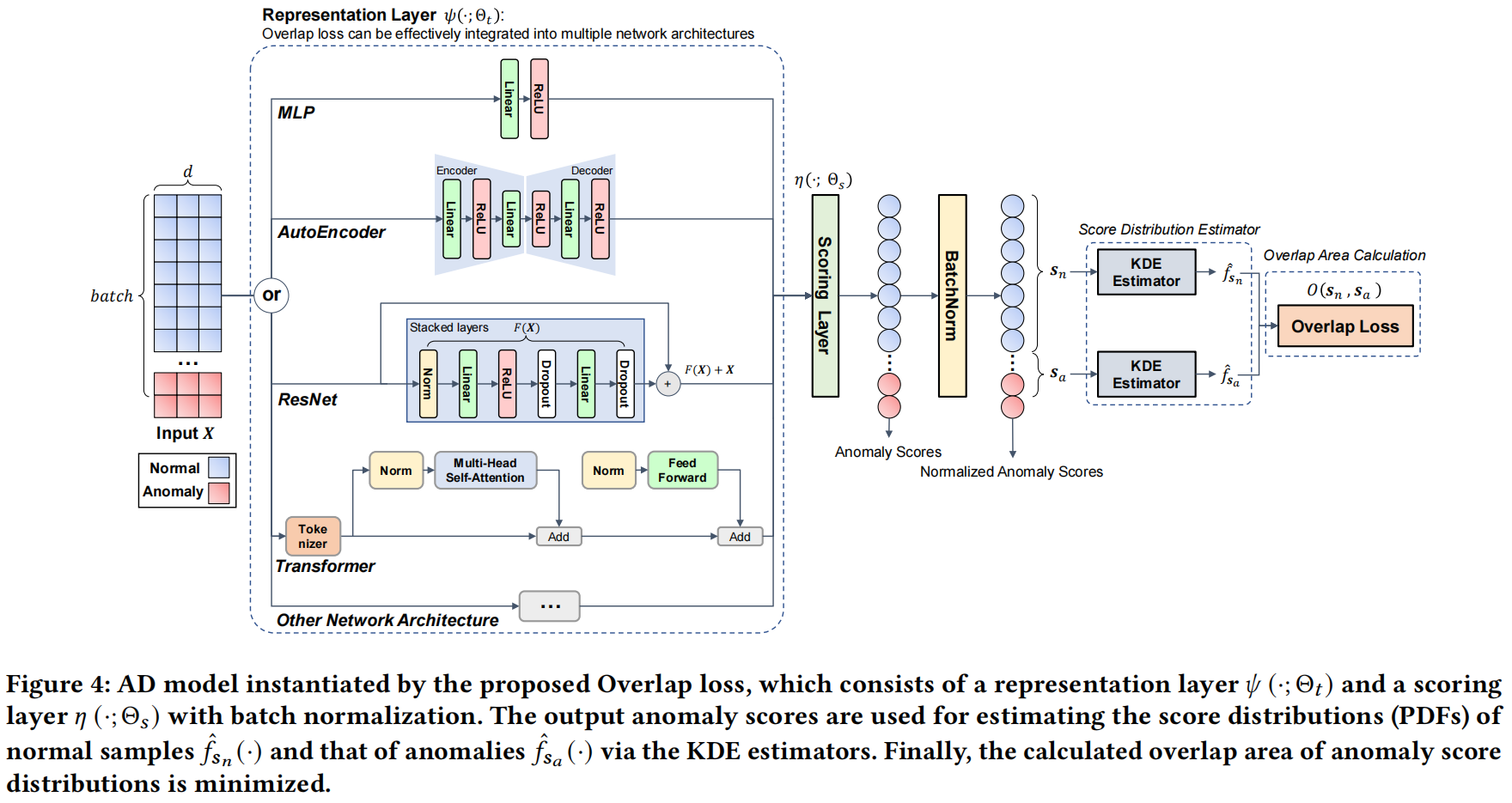
我们指出,提出的Overlap loss可以有效地集成到多种常用的网络架构中,包括广泛使用的MLP和AutoEncoder在AD任务中,以及一些前沿的架构,如ResNet和Transformer在分类任务中。算法1提供了基于我们提出的Overlap loss的实例化模型的详细步骤。

4 EXPERIMENTS
4.1 Experiment Setting
Datasets
我们使用了25个公开可用的真实世界数据集来评估模型。这些数据集涵盖了各种领域,如疾病诊断、语音识别和图像识别。每个数据集中,将70%的数据作为训练集,剩余的30%作为测试集,通过分层抽样来保持相同比例的异常数据。在第4.2.1节中,我们将讨论 在不同比例的有标签异常数据与所有真实异常数据 \({\gamma}_l=m/(k+m)\) 的训练集中 模型的性能,其中 \(m\) 个有标签的异常数据是从整个异常数据中抽样的,而其余的 \(k\) 个实例保持未标记。
Baselines
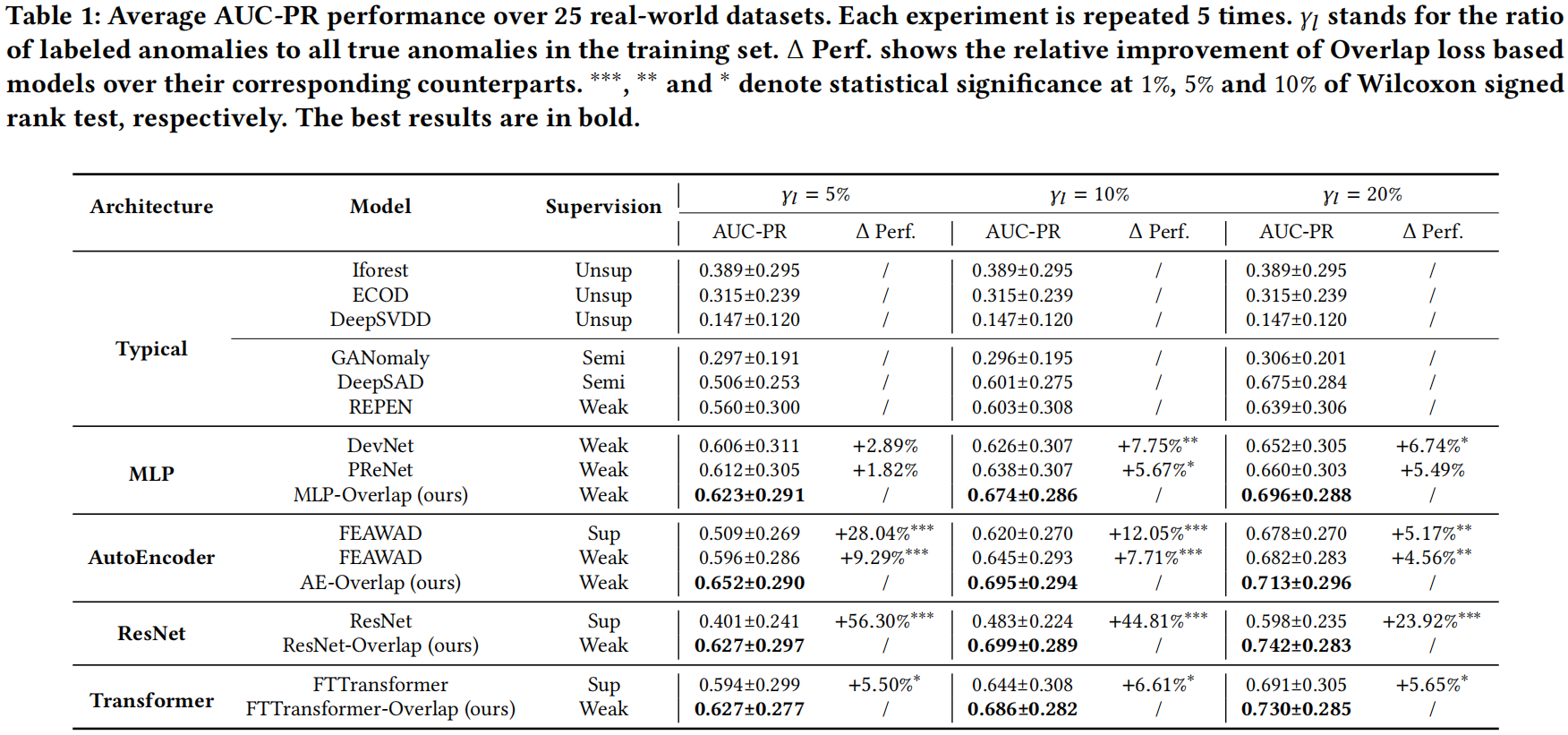
我们将提出的方法与以下基线方法1进行了比较,并根据它们的网络架构和监督级别进行了总结,如表1所示。
Metrics
AUCROC (Area Under Receiver Operating Characteristic Curve) 和 AUC-PR (Area Under Precision-Recall Curve) values.
我们还应用了成对的Wilcoxon符号秩检验 [62] 来检验所提出的方法与竞争对手之间的显著性差异。
4.2 Experimental Results
4.2.1 Model Performance.
4.2.2 Runtime Analysis
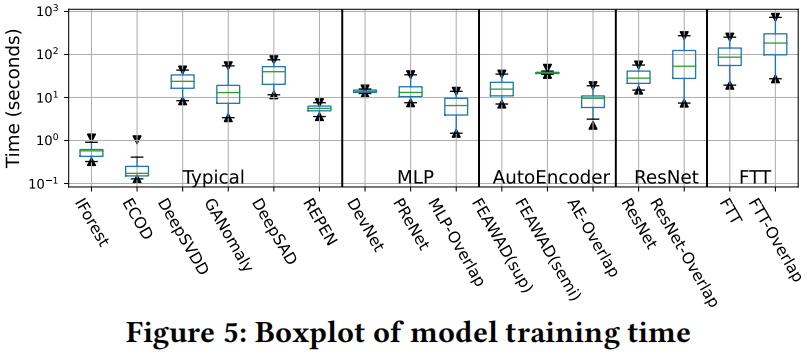
4.2.3 Ablation Study
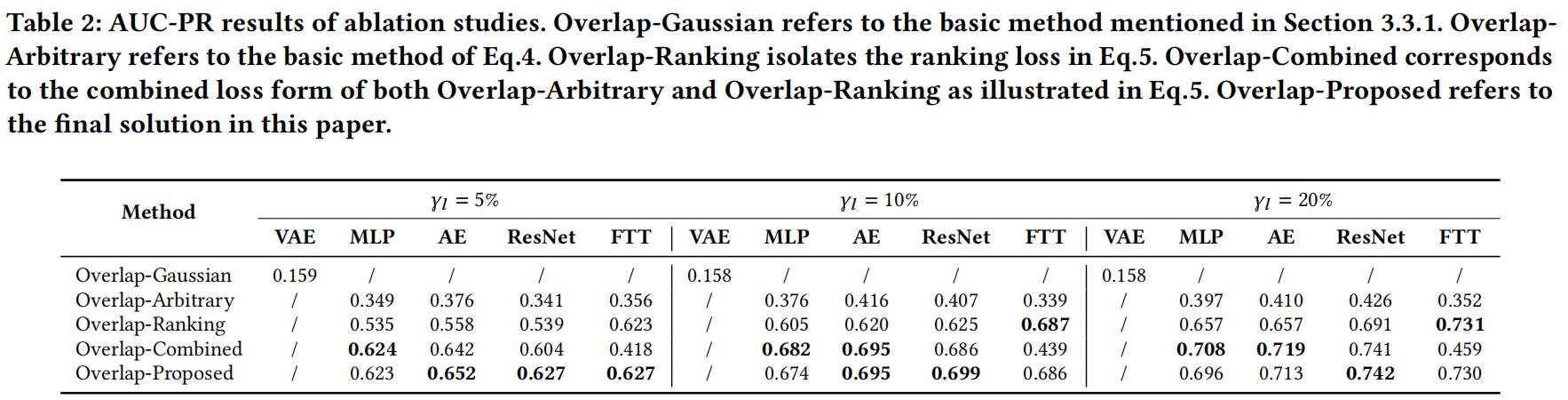
在表2中,我们报告了第3节中提到的几种基本方法的AUC-PR结果。
Overlap-Gaussian是第3.3.1节中提到的基本方法。OverlapArbitrary是指Eq.4的基本方法。Overlap-Ranking为了Eq.5中的排名损失。Overlap-Combined对应于Eq.5中Overlap-Arbitrary和Overlap-Ranking的组合损失形式。Overlap-Proposed是指本文的最终解决方案。
首先,我们观察到Overlap-Gaussian的性能最差。这是因为标记异常的稀缺性使得其得分分布通常呈现出一定的随意性,而高斯假设对得分函数的表示是有害的。
其次,异常得分的无序导致了Overlap-Arbitrary中的性能下降。排名损失项可以作为一种有效的方式来保证异常得分的顺序,因为Overlap-Combined方法显着提高了AUC-PR性能。
第三,提出的Overlap loss在大多数情况下优于所有基本方法,因为它可以有效地估计输出异常得分的任意得分分布,同时避免了在Overlap-Arbitrary方法中出现的得分无序问题。与Overlap-Combined方法相比,Overlap-Proposed取得了更好的性能,可能是因为它实现了一个统一的损失函数形式,而不是两个不同损失部分的组合。此外,我们观察到在FTTransformer等更复杂的网络骨干中,Overlap-Combined方法中的多任务损失形式失败了。
4.3 Further Exploration into AD Loss Functions
尽管大多数现有的研究侧重于提出和评估特定的异常检测方法模型或架构设计[63],但我们设法更进一步,直接比较同一网络架构中的不同损失函数。我们首先研究了不同的损失函数在25个真实世界数据集上的表现,然后报告了它们在检测各种类型的异常方面的性能。

4.3.1 Exploration of AD Loss Functions on Real-world Datasets
Embedding Transformation during Model Training
输入特征的转换嵌入可以看作是实现训练目标的表示层变化的可视化
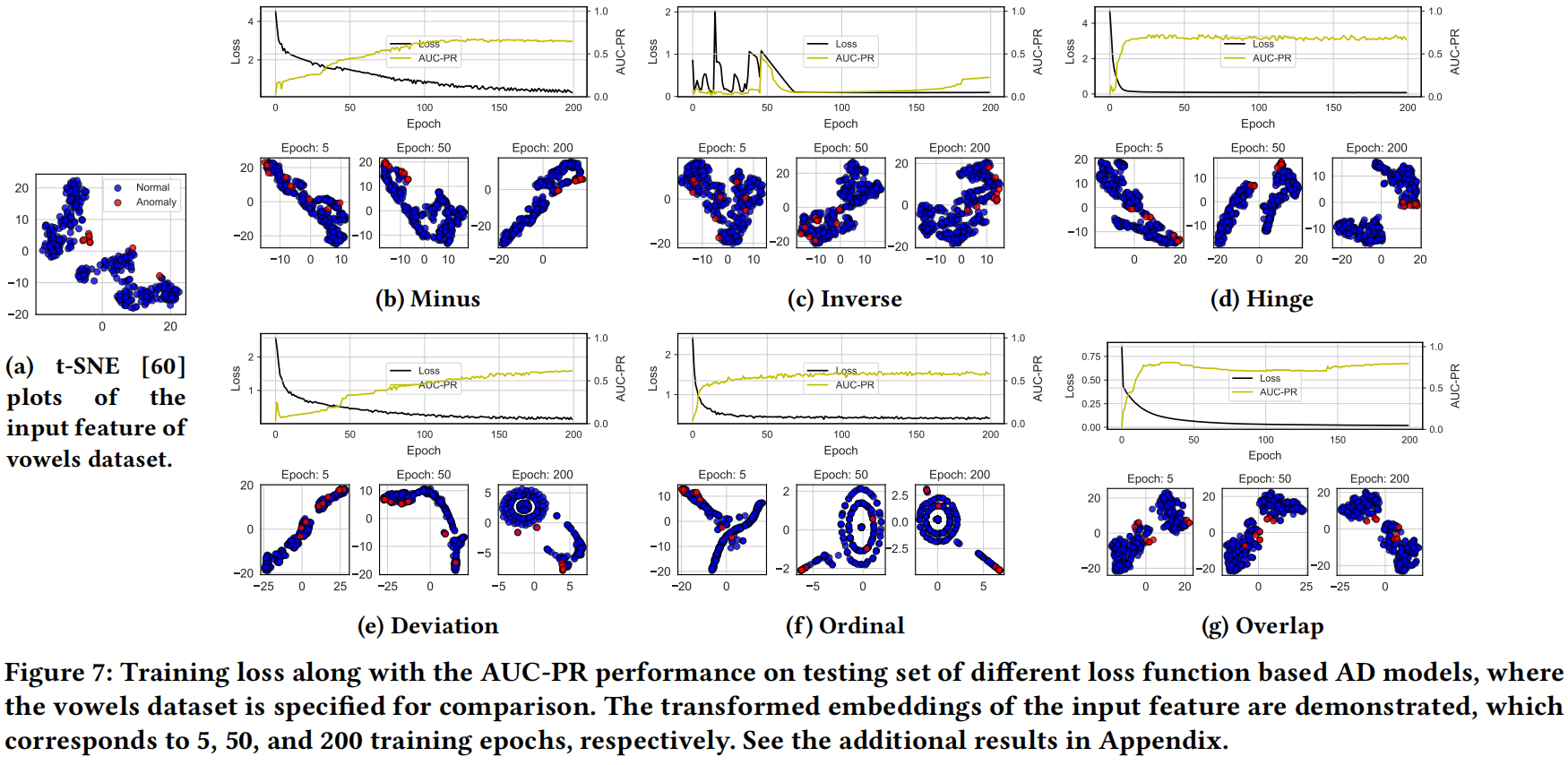
我们以 vowels 数据集为例,展示了在训练过程中特征表示层中的嵌入变换,如图7所示。类似的实验结果在其他真实世界数据集中也可以观察到,我们在补充材料的附录中提供了这些结果。图7表明,Deviation loss 和 Ordinal loss 往往会在几个训练周期后严重扭曲原始输入数据的嵌入。这是因为这两种损失函数明确引导网络将每个实例或对的异常分数映射到一个或多个固定的分数常数或分数边距,从而阻碍了学到的特征表示的多样性。此外,未标记的正常样本受到未标记的异常的污染,为这两种数据类型定义相同的训练目标将限制学习模型的表示能力。
我们提出的Overlap损失对输入特征生成了相对温和的变换。如前所述,基于Overlap损失的AD模型可以实现更高的检测性能,因此我们推测,良好的检测性能并不总是需要在表示空间中进行过度的转换,模型只需转换对分数分布鉴别具有最大影响力的嵌入,并保留更精细的输入数据信息。
Network Parameter Changes
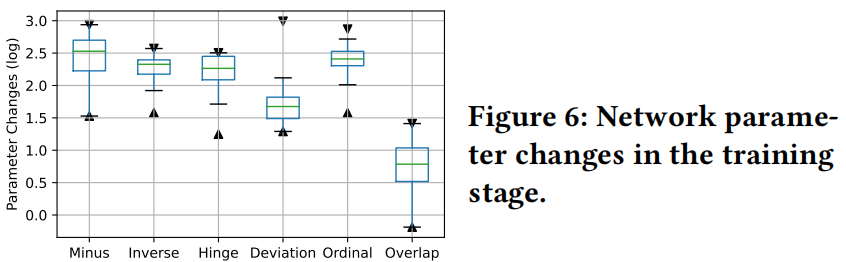
当实现它们的相应训练目标时,我们研究了基于不同损失函数的AD模型的网络参数变化
我们在图6中展示了在25个真实世界的数据集上的网络参数变化结果,其中计算了每一层的参数差异之和,即初始化模型和其更新版本之间的参数差异的二范数。结果表明,与其他损失函数相比,基于我们提出的Overlap损失的AD模型具有更小的网络参数变化。这个结果对应于Overlap损失的良好性质,其中
- Overlap损失是自然有界的,避免了异常分数(和网络参数)的急剧更新。
- Overlap损失不需要异常分数的先验目标,因此减少了训练阶段不必要的评分函数更新,并能够在最少调整分数分布的情况下适应不同的数据集。
4.3.2 Exploration of AD Loss Functions on Different Types of Anomalies
虽然广泛的异常检测方法已被证明在真实世界的数据集上有效,但以前的研究往往忽略了关于特定类型的异常的AD方法的优缺点[17,58]。事实上,公共数据集通常由不同类型的异常混合而成。我们按照[21,58]的方法,在上述25个数据集的基础上,注入了四种类型(即local, global, clustered, and dependency)的异常,以评估不同的损失函数。附录.5提供了生成的合成异常的详细信息。
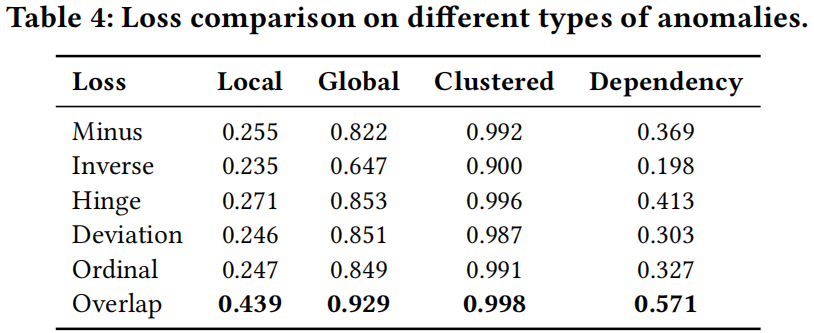
表4显示了不同类型异常的损失函数比较的AUC-PR结果。这些结果与[21]中的研究结果一致,即针对半监督或弱监督的AD算法设计的其他损失函数在local和dependency异常上表现相对较差。与clustered anomalies不同,local 和 dependency 异常的部分标记异常不能很好地捕获特定类型异常的所有特征,并且学习用于分离正常数据和异常数据的决策边界通常具有挑战性(参见附录中的图A2g~A2k)。因此,不完整的标签信息可能会偏向于这些损失函数的学习过程,这解释了它们相对较差的性能与Overlap损失相比。
相反,Overlap损失在local、global 和 dependency 异常上表现出色,对clustered异常也取得了令人满意的结果。例如,Overlap损失在局部异常的平均AUC-PR为0.439,而第二好的Hinge损失为0.271。类似的结果也可以在dependency异常中观察到,其中Overlap损失的AUC-PR为0.571,而第二好的Hinge损失为0.413。
这些结果验证了Overlap损失可以有效利用部分标签和异常类型的先验知识。也就是说,在训练阶段只有有限数量的标记异常可用时,基于Overlap损失的AD模型(例如,ResNet-Overlap)可以实现更好的性能。此外,如果能够获得有关异常类型的宝贵先验知识[21],Overlap损失可以作为学习此特定类型(例如,dependency)异常模式的有效解决方案。
- Discrimination Distribution Detection Anomaly 论文discrimination distribution detection anomaly distribution detection anomaly论文 detection机器anomaly mean-shifted contrastive detection anomaly isolation detection anomaly forest detection learning anomaly survey multi-class detection unified anomaly distribution unsupervised cumulative detection detection real-time holmes论文 discrimination