此文概述
- 通过 made Paxos Simple Basic Paxos 了解 Paxos 基本实现
- Mulit Paxos 的实现需要解决的问题
- Mulit Paxos -> Raft
复制状态机
相同初始状态 + 相同的输入 + 相同的状态转化条件 = 相同的最终状态
每台机器,运行相同的处理函数,按照顺序执行相同的输入那么最终的状态也就是一样滴。
如何保证输入相同,这就是分布式共识算法所做的事情。
basic paxos
通过 made paxos simple 论文来了解精心设计的两阶段

算法干了什么?
满足所谓的安全性需求: 1. 提出提案 2. 选定提出的提案 3.别人看到被选定提案(目标)
前提:信息不会损坏( 非拜占庭 )。
角色
Proposers 提出提案
Acceptors 通过提案
Learners 获取选定的提案
避免单点问题 故采用多个 Acceptors。
一个提案通过的流程
- Proposer 提出提案
- 多个 Acceptors 中足够多的Acceptor通过(accept) 即是选定
规定: 如果我们再规定一个Acceptor最多只能通过一个提案
问题: 为什大多数集
任意两个多数集( > n / 2)至少有一个公共成员, 而这个公共成员选定了提案根据规定,那么就能保证只有一个提案被选定。(抽屉原理)
需求1
在没有失败和消息丢失的情况下,如果我们希望即使在只有一个提案被提出的情况下,仍然可以选出一个提案来
如何实现?
P1. 一个Acceptor必须通过(accept)它收到的第一个提案。
带来的问题:
这可能会导致虽然每个Acceptor都通过了一个提案,但是没有一个提案是由多数人都通过的。即使是只有两个提案,如果每个都被差不多一半的Acceptors通过了,此时即使只有一个Acceptor出错都可能使得无法确定该选定哪个提案。
解释:
Acceptors = { a ,b ,c ,d ,e }
提案1 { a, b c }
提案2 { d, e }
挂掉 c => { a, b } { d, e }
learner 无法获取到大多数的提案
需求2
一个 Acceptor 通过多个提案。
重新定义提案结构 {id, value}
- 提案包含编号,每个提案有不同的编号即可。
- 获取通过的提案的value值 => 提案包含value值。
当一个具有某value值的提案被半数以上的Acceptor通过后,我们就认为该value被选定了。此时我们也认为该提案被选定了。
如何实现?
P2. 如果具有value值v的提案被选定(chosen)了,那么所有比它编号更高的被选定的提案的value值也必须是 v 。
因为编号有序( 也就是每个提案编号不唯一),并且 提案都是有 Acceptor通过的。
等价于
P2a. 如果具有value值 v 的提案被选定(chosen)了,那么所有比它编号更高的被Acceptor通过的提案的value值也必须是 v 。
问题:
一个提案可能会在某个Acceptor c 还未收到任何提案时就被选定了。假设一个新的Proposer苏醒了,然后产生了一个具有另一个value值的更高编号的提案,根据 P1 ,就需要 c 通过这个提案,但是这与 P2a 矛盾。因此如果要同时满足 P1 和 P2a
这个时候,value 值不一定是已经选定的value值,但是根据 P1 我们这个 Acceptor 还必须得通过(因为是第一个),所以矛盾。
解决
限制 提案端
必要条件
P2b. 如果具有value值v的提案被选定,那么所有比它编号更高的被Proposer提出的提案的value值也必须是 v 。
一个提案被Acceptor通过之前肯定要由某个Proposer提出,因此 P2b 就隐含了 P2a ,进而隐含了 P2 。
如何保证呢?
原文使用归纳法。
为了发现如何保证 P2b ,我们来看看如何证明它成立。我们假设某个具有编号m和value值v的提案被选定了,需要证明具有编号 n(n > m) 的提案都具有value值 v 。我们可以通过对 n 使用归纳法来简化证明,这样我们就可以在额外的假设下——即编号在 m..(n-1) 之间的提案具有value值 v ,来证明编号为n的提案具有value值 v 。因为编号为m的提案已经被选定了,这意味着肯定存在一个由半数以上的Acceptor组成的集合 C , C 中的每个Acceptor都通过了这个提案。再结合归纳假设, m 被选定意味着:
C 中的每个Acceptor都通过了一个编号在 m..n-1 之间的提案,每个编号在 m..(n-1) 之间的被Acceptor通过的提案都具有value值 v 。
问题转变
在 n (n > m) Proposer提出的提案的value值是 v 。
如何保证上述内容呢?
P2c. 对于任意的 n 和 v ,如果编号为 n 和value值为 v 的提案被提出,那么肯定存在一个由半数以上的Acceptor组成的集合 S ,可以满足条件 a) 或者 b) 中的一个:
- S 中不存在任何的Acceptor通过过编号小于 n 的提案 ( 维护P1 )
- v 是 S 中所有Acceptor通过的编号小于 n 的具有最大编号的提案的value值。( 维护P2b , 既然通过了编号为m的提案,那么 距离 n 通过的最大编号的提案就是 编号为 m 的提案,那么其value值也就是v。 )
通过维护,就可以保证 在 n (n > m) Proposer提出的提案的value值是 v .
怎么实现?
为了维护 P2c 的不变性,一个Proposer在产生编号为 n 的提案时,必须要知道某一个将要或已经被半数以上Acceptor通过的编号小于 n 的最大编号的提案。
问题:
Proposer准备提出编号为n的提案,通过Acceptors获取已经通过的编号为m的提案,Acceptors又通过了一个编号 < n 的提案 ( 违反了 P2c.2 )
解决:
避免让Proposer去预测未来,限制 Acceptors。也就是 Proposer 告诉 Acceptors 不要再通过任何编号小于 n 的提案。
实现
prepare 请求
Proposer选择一个新的提案编号 n ,然后向某个Acceptors集合的成员发送请求,要求Acceptor做出如下回应。
- 保证不再通过任何编号小于 n 的提案 ( 防止预测未来 )
- 返回 当前它已经通过的编号小于 n 的最大编号的提案,如果存在的话。( 后面有用到这个值 )
我们把这样的一个请求称为编号为 n 的prepare请求
Proposer接受响应之后
如果Proposer收到了来自半数以上的Acceptor的响应结果,那么它就可以产生编号为 n ,value值为 v 的提案,这里 v 是所有响应中编号最大的提案的value值,如果响应中不包含任何的提案那么这个值就可以由Proposer任意选择。
acceptor 端的困扰
它可能会收到来自Proposer端的两种请求:prepare请求和accept请求。Acceptor可以忽略任何请求而不用担心破坏其算法的安全性。因此我们只需要说明它在什么情况下可以对一个请求做出响应。它可以在任何时候响应一个prepare请求,对于一个accept请求,只要在它未违反现有承诺的情况下才能响应一个accept请求(通过对应的提案).
实现
P1a. 一个Acceptor可以接受一个编号为 n 的提案,只要它还未响应任何编号大于 n 的 prepare 请求。( 防止预测未来)
P1a 蕴含了 P1
所以 acceptor 端 需要记录一个通过的最大编号的提案(编号+value),并且已经做出prepare请求响应的最大编号的提案的编号(P1a)。因为必须在出错的情况下保证 P2c ,Acceptor必须记住这些信息即使是在出错或者重启的情况下(也就是持久化)。Proposer可以总是可以丢弃提案以及它所有的信息—只要它可以保证不会产生具有相同编号的提案即可。
守得云开见月明
两阶段就是 prepare + accept
**Phase 1. **
- Proposer选择一个提案编号 n ,然后向Acceptors的某个majority集合的成员发送编号为 n 的 prepare请求。
- 如果一个Acceptor收到一个编号为 n 的 prepare请求,且 n 大于它已经响应的所有prepare请求的编号,那么它就会保证不会再通过(accept)任何编号小于 n 的提案,同时将它已经通过的最大编号的提案(如果存在的话)作为响应。
Phase 2.
- 如果Proposer收到来自半数以上的Acceptor对于它的prepare请求(编号为 n) 的响应,那么它就会发送一个针对编号为 n ,value值为 v 的提案的accept请求给Acceptors,在这里 v 是收到的响应中编号最大的提案的值,如果响应中不包含提案,那么它就是任意值。
- 如果Acceptor收到一个针对编号 n 的提案的accept请求,只要它还未对编号大于 n 的prepare请求作出响应,它就可以通过这个提案。
弊端
- basic paxos 只是在同意 一个值 或者说 一条日志,它允许日志空洞,而我们的目标是相同的输入,为了获取相同的输入,我们还需要做一些其他的约定。
- 每次请求都需要请过两次 rpc,并且有活锁的风险(类似 a.phase1 , b.phase1, a.phase2, b.phase2 重复这个序列)
Mutli Paxos
利用 Basic Paxos 就达成一连串的 log
这里主要是为了实现 复制状态机, 相同的输入内容(类似流)。
那么如何去状态机应用的顺序,我们将日志规定为
type LogEntry struct{
Index int // 代表他在整个输入流的位置
Data []byte
}
那么什么时候这条日志可以被
需要解决的问题
- 日志与 client 请求 之间的映射关系
- 选取leader 减少 proposal 的冲突,以及消除第一阶段的请求。
- 确保其他人 完全的复制 当前的日志,并知道哪些日志已经被选定
- 客户端协议以及配置变化
解决方法
对于第一个,我们需要向每一个请求带上一个对应的Index
日志
Basic Paxos日志是不连续的,容忍日志空洞,当前选择的日志条目可能已经达成共识,但是该instance 没有该日志条目,所以我们需要进行 日志追赶 , 当然,如果当前日志已经达成共识,那么我们需要同步给其他人或者跳过。
我们开始会维护一个 CommitIndex 代表该 LogIndex 之前的所有 entry 都已经被提交( 连续性),那当获取该请求对应的Index 时,我们就不用检查 Logindex 之前的了,
那么如何追赶呢?
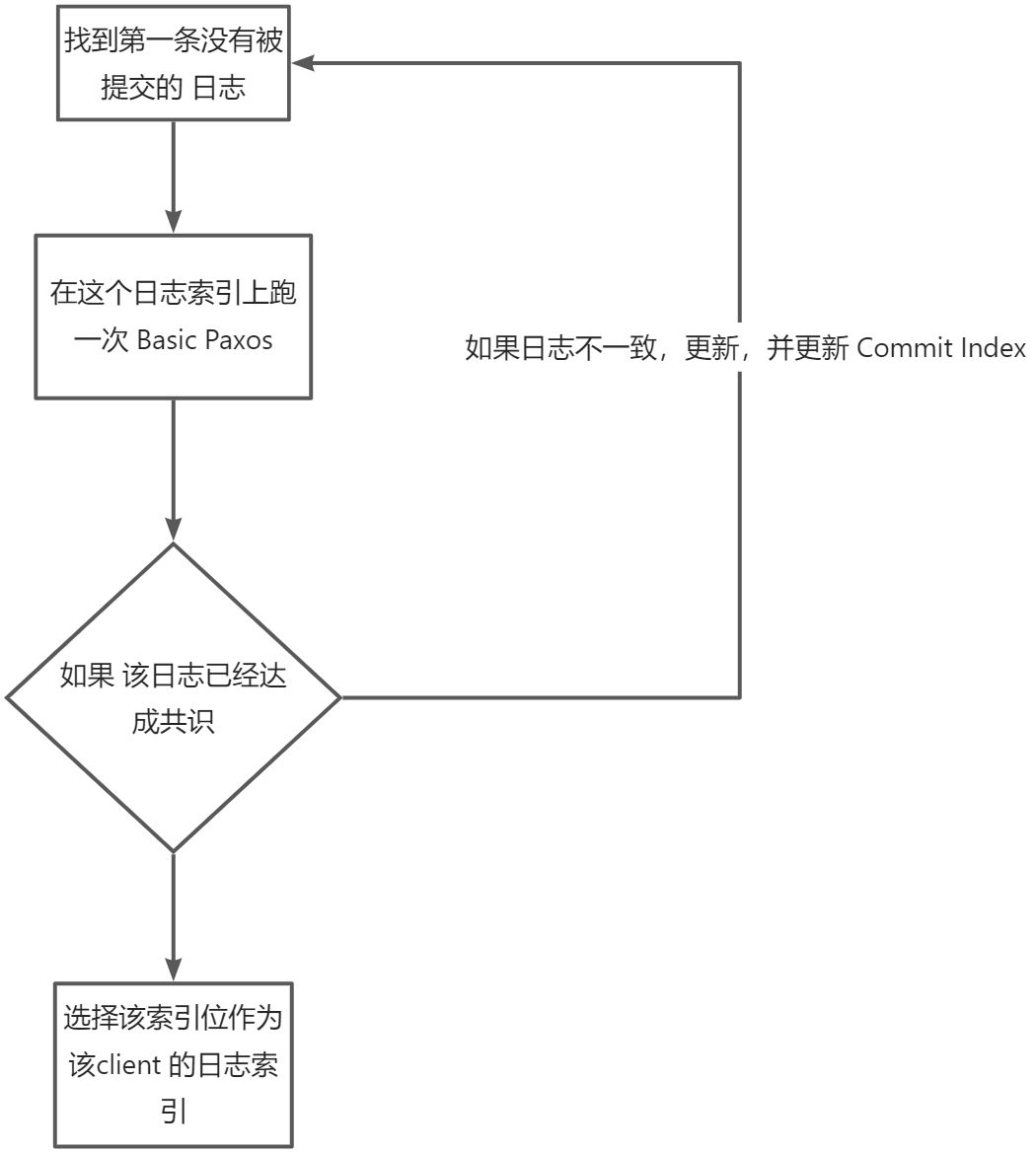
这样我们也做到了日志追赶。
选代表
如果有多个 instance 接受 client Request,那么我们就像 Basic Paxos一样,产生冲突,效率降低。
我们是一阶段请求 目的是
- 防止旧Leader (提案id 小不予通过)
- 知道当前通过的值
我们让一个人接受请求,然后减少后续 prepare 请求。
怎么做?
- 复用 第一次 prepare 请求的id
- 提案编号是由 一个唯一的提案 id(serverId + incNum)+ value 值(P2),我们改下 id 的组成,变为当前整个日志条目。
这个 id 的意思是这样。
- prepare < 123 + 1 , a> -> success
- prepare < 123 + 1, b> -> success
- prepare < 123 + 1, c > -> fail
- prepare < 123 + 2, c > -> fail
- 如果 当前 没有比之个 id 更大的提案,返回 NoMoreAccept,那么说明我们后续的日志槽位我们是空的。
如果 一个 proposal 收到了多数的 NoMoreAccept, 成为 Leader,如果一个Accept收到了拒绝,那么就重新开始该次选举。
如果 有一般人 发挥 NoMoreAccept ,成为 Leader,后续只发送 accept 请求。
我们现在将 这个 id 改为 (serverId + 某个固定的值),
所以我们让一个人接受请求,进行 prepare 请求,如果成功,之后所有的 prepare 请求就延用这个id。


确保其他人 完全复制 当前的日志,并知道哪些日志已经被选定
现在只有 Leader 有最全的日志,并且只有 proposer 知道哪些值被选定。
现在的目标
-
大多数人都有全的日志
-
所有人都需要知道当前被选定的日志条目
-
重试法
一直进行 accept ,直到该 Acceptor 都已经接受
- 标记已经提交的
如果已经提交,该日志条目的 proposeId = ∞, 并且所有人维护一个 最小的没提交的日志索引 [FirstUnChosenIndex](快速判断)
- leader 包含当前已经提交日志条目的信息 ,也就是 将 FirstUnChosenIndex 加入 Accept 请求中
接受者:1. 当前 index < FirstUnChosenIndex 2. log[index].ProposeId = Accept.ProposeId
标记为已提交, 说明,处于 Index 位置上的这条日志是当前是这个 Leader 发送的,并且 Leader 发送给每一个人的 Index 都已一样的,并且现在已经被大多数人接受了。
这里主要就是因为 Basic Paxos 只是知道某个日志槽选定了哪个值,但是并不知道这个值是否和其他人一样。
- 日志追赶,Acceptor 添加 FirstUnChosenIndex 在 Accept 响应中。
如果 proposer.FirstUnChosenIndex > Acceptor.FirstUnChosenIndex
发送 Success(Acceptor.FirstUnChosenIndex, v)
Accept 收到 Success 请求之后
- 更改 日志索引位置为 Index 上的值为 v
- 标记为已提交
- 更新 FirstUnChosenIndex, 并返回最新的值
解释: 当一个 Proposal 选定为一个 Leader 时,代表他拥有最新的日志,并且他(参考上面的 选代表),
Raft
强调了什么
- Leader 合法性
- 日志连续性
日志连续性
日志的结构和上面的 Multi Paxos 没有变化
type LogEntry struct{
Index int
ProposalId int
Data []byte
}
那么如何保证一个这个连续性,我们在追赶日志的时候去保证,在追赶日志时 包含上一个日志条目的信息。
前提:
- 一个term(也可以成为ProposalId,只不过这个ProposalId 不包含 服务器的唯一Id了,只是一个IncNum)只有一个Leader。
- 一个合法Leader在一个Index只会有一条日志。
这样我们就保证了用一个二元组(term,index)来确定上一个日志是否一致,如果一致,我们就追加,当然需要与这个合法Leader的日志同步,覆盖掉不一致的,因为我们可能后面有旧Leader同步过来的未提交的日志。
这样就保证了日志的连续性(数学归纳法)。
再想想 FirstUnChosenIndex, 可以结合这个连续性。
FirstUnChosenIndex之前的所有日志都已经被大多数人提交,之后虽然没有被提交,但是是合法Leader接受的日志也需要同步。
日志同步
和 上面的 Multi Paxos 一致,只进行 追加即可(Accept),如果发生冲突,进行日志追赶。
日志追赶
如果需要追赶日志,直接发送 Acceptor.FirstUnChosenIndex 之后的所有日志即可,Acceptor 接受之后,因为包含没有提交的日志,所以不能直接标记为已提交,先追加,等下一次 Accept 请求过来之后,进行同步
这里可能有个小问题, 是我刚开始时候学遇到的。
冲突的日志是否是能是已经提交的?
这个需要参考 Leader 选举,合法 Leader 一定具有全部已经提交的日志,如果它没有但却成为了Leader,那么说明有一个具有全部已经提交的日志的人投票给他,但是我们投票的时候会比较日志的新旧,所以矛盾。
Leader 选举
因为 Paxos 没有考虑 Log 是否最新,导致新Leader可能上来无法直接执行 client Request。
但 Raft 在选取Leader 时借助 日志连续性,将日志是否是最新的也加入的考量范围
- 共有的 比较 term (ProposalId)
- 比较 Index
这样我们选出来的Leader就时最有最新的日志(相较于大多数),所以它必然有已提交的所有日志。