引子
DeepSpeed是由Microsoft提供的分布式训练工具,旨在支持更大规模的模型和提供更多的优化策略和工具。与其他框架相比,DeepSpeed支持更大规模的模型和提供更多的优化策略和工具。其中,主要优势在于支持更大规模的模型、提供了更多的优化策略和工具(例如 ZeRO 和 Offload 等)
- 在分布式计算环境中,需要理解几个非常基础的概念:节点编号、全局进程编号、局部进程编号、全局总进程数和主节点。其中,主节点负责协调所有其他节点和进程的工作,因此是整个系统的关键部分。
- DeepSpeed 还提供了 mpi、gloo 和 nccl 等通信策略,可以根据具体情况进行选择和配置。在使用 DeepSpeed 进行分布式训练时,可以根据具体情况选择合适的通信库,例如在 CPU 集群上进行分布式训练,可以选择 mpi 和 gloo;如果是在 GPU 上进行分布式训练,可以选择 nccl。
- ZeRO(Zero Redundancy Optimizer)是一种用于大规模训练优化的技术,主要是用来减少内存占用。ZeRO 将模型参数分成了三个部分:Optimizer States、Gradient 和 Model Parameter。在使用 ZeRO 进行分布式训练时,可以选择 ZeRO-Offload 和 ZeRO-Stage3 等不同的优化技术。
- 混合精度训练是指在训练过程中同时使用FP16(半精度浮点数)和FP32(单精度浮点数)两种精度的技术。使用FP16可以大大减少内存占用,从而可以训练更大规模的模型。在使用混合精度训练时,需要使用一些技术来解决可能出现的梯度消失和模型不稳定的问题,例如动态精度缩放和混合精度优化器等。
- 结合使用huggingface和deepspeed
Accelerate和deepspeed的联系
- Accelerate是PyTorch官方提供的分布式训练工具,而deepspeed是由Microsoft提供的分布式训练工具。
- 最主要的区别在于支持的模型规模不同,deepspeed支持更大规模的模型。
- deepspeed还提供了更多的优化策略和工具,例如ZeRO和Offload等。
- 但是Accelerate更加稳定和易于使用,适合中小规模的训练任务。
- Accelerate只支持nvlink,而T4,3090这类显卡是PIX ,检测方式:nvidia-smi topo -m
基本概念
在分布式计算环境中,有几个非常基础的概念需要理解:
- 节点编号(node_rank:):分配给系统中每个节点的唯一标识符,用于区分不同计算机之间的通信。
- 全局进程编号(rank):分配给整个系统中的每个进程的唯一标识符,用于区分不同进程之间的通信。
- 局部进程编号(local_rank):分配给单个节点内的每个进程的唯一标识符,用于区分同一节点内的不同进程之间的通信。
- 全局总进程数(word_size):在整个系统中运行的所有进程的总数,用于确定可以并行完成多少工作以及需要完成任务所需的资源数量。
- 主节点(master_ip+master_port):在分布式计算环境中,主节点负责协调所有其他节点和进程的工作,为了确定主节点,我们需要知道它的IP地址和端口号。主节点还负责监控系统状态、处理任务分配和结果汇总等任务,因此是整个系统的关键部分。
通信策略
deepspeed 还提供了 mpi、gloo 和 nccl 等通信策略,可以根据具体情况进行选择和配置。
- mpi 是一种跨节点通信库,常用于 CPU 集群上的分布式训练;
- gloo 是一种高性能的分布式训练框架,支持 CPU 和 GPU 上的分布式训练;
- nccl 是 NVIDIA 提供的 GPU 专用通信库,被广泛应用于 GPU 上的分布式训练。
在使用 DeepSpeed 进行分布式训练时,可以根据具体情况选择合适的通信库。通常情况下,如果是在 CPU 集群上进行分布式训练,可以选择 mpi 和 gloo;如果是在 GPU 上进行分布式训练,可以选择 nccl。
export CUDA_LAUNCH_BLOCKING=1
Zero(3D优化与卸载)
ZeRO(Zero Redundancy Optimizer)是一种用于大规模训练优化的技术,主要是用来减少内存占用。在大规模训练中,内存占用可以分为 Model States 和 Activation 两部分,而 ZeRO 主要是为了解决 Model States 的内存占用问题。
ZeRO 将模型参数分成了三个部分:Optimizer States、Gradient 和 Model Parameter。
- Optimizer States 是 Optimizer 在进行梯度更新时所需要用到的数据,例如 SGD 中的 Momentum。
- Gradient 是在反向传播后所产生的梯度信息,其决定了参数的更新方向。
- Model Parameter 则是模型参数,也就是我们在整个过程中通过数据“学习”的信息。
ZeRO-Offload和ZeRO-Stage3是DeepSpeed中的不同的Zero-Redundancy Optimization技术,用于加速分布式训练,主要区别在资源占用和通信开销方面。
- ZeRO-Offload将模型参数分片到不同的GPU上,通过交换节点间通信来降低显存占用,但需要进行额外的通信操作,因此可能会导致训练速度的下降。
- ZeRO-Stage3将模型参数分布在CPU和GPU上,通过CPU去计算一部分梯度,从而减少显存占用,但也会带来一定的计算开销。
三个级别
ZeRO-0:禁用所有类型的分片,仅使用 DeepSpeed 作为 DDP (Distributed Data Parallel)
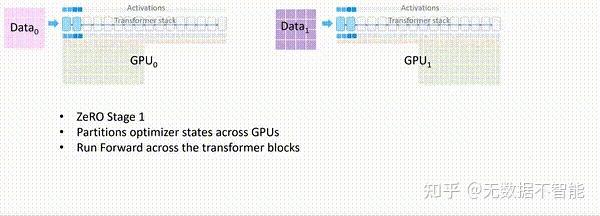
ZeRO-1:分割Optimizer States
ZeRO-2:分割Optimizer States与Gradients
ZeRO-3:分割Optimizer States、Gradients与Parameters

ZeRO-Infinity是ZeRO-3的拓展。允许通过使用 NVMe 固态硬盘扩展 GPU 和 CPU 内存来训练大型模型。ZeRO-Infinity 需要启用 ZeRO-3。
在deepspeed中通过zero_optimization.stage=0/1/2/3 设置,卸载通过zero_optimization.offload_optimizer.device设置
混合精度
混合精度训练是指在训练过程中同时使用FP16(半精度浮点数)和FP32(单精度浮点数)两种精度的技术。使用FP16可以大大减少内存占用,从而可以训练更大规模的模型。但是,由于FP16的精度较低,训练过程中可能会出现梯度消失和模型不稳定的问题。因此,需要使用一些技术来解决这些问题,例如动态精度缩放(Dynamic Loss Scaling)和混合精度优化器(Mixed Precision Optimizer)等。
deepspeed提供了混合精度训练的支持,可以通过在配置文件中设置"fp16.enabled": true来启用混合精度训练。在训练过程中,deepspeed会自动将一部分操作转换为FP16格式,并根据需要动态调整精度缩放因子,从而保证训练的稳定性和精度。
在使用混合精度训练时,需要注意一些问题,例如梯度裁剪(Gradient Clipping)和学习率调整(Learning Rate Schedule)等。梯度裁剪可以防止梯度爆炸,学习率调整可以帮助模型更好地收敛。因此,在设置混合精度训练时,需要根据具体情况进行选择和配置。
BF16
BF16和FP16都是混合精度训练中使用的浮点数表示格式。
BF16是一种Brain Floating Point格式,由英特尔提出,可以提供更好的数值稳定性和更高的精度,但需要更多的存储空间。在混合精度训练中,BF16可以作为一种精度更高的替代品,用于一些关键的计算操作,例如梯度累加和权重更新等。使用BF16可以提高模型的训练速度和精度,并减少内存占用。
在 DeepSpeed 中,可以通过在配置文件中设置 "bf16.enabled": true 来启用 BF16 混合精度训练。这将会将一部分操作转换为 BF16 格式,并根据需要动态调整精度缩放因子,从而提高模型的训练速度和精度,并减少内存占用。
NVIDIA Tesla V100 不支持BF16
与huggingface结合
- 安装 DeepSpeed:
pip install deepspeed
- 在训练脚本中导入 DeepSpeed 模块:
import deepspeed
- 在训练脚本中导入 Trainer 模块:
from transformers import Trainer
- 创建 Trainer 对象,将模型、训练数据集、优化器等参数传入:
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=data_collator,
optimizer=optimizer,
)
trainer.train()
- 使用 DeepSpeed 命令行工具运行训练脚本(单机):
deepspeed --num_gpus=8 train.py
其中,--num_gpus 表示使用的 GPU 数量。
多节点:
deepspeed --hostfile=hostfile --master_port 60000 --include="node1:0,1,2,3@node2:0,1,2,3" run.py \
--deepspeed ds_config.json
hostfile
node1_ip slots=4
node2_ip slots=4
其中,slot 表示该节点的GPU数量
ds_config.json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e6,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}