概述增强式学习(Reinforcement Learning)
- Supervised Learning(自监督学习):告诉机器输入和输出,用有标注的训练资料训练出的Network
- Reinforcement Learning(增强式学习):给机器一个输入,我们不知道最佳输出是什么(适用于标注困难或者人也不知道答案是什么)

(机器需要知道什么是好,什么是不好)
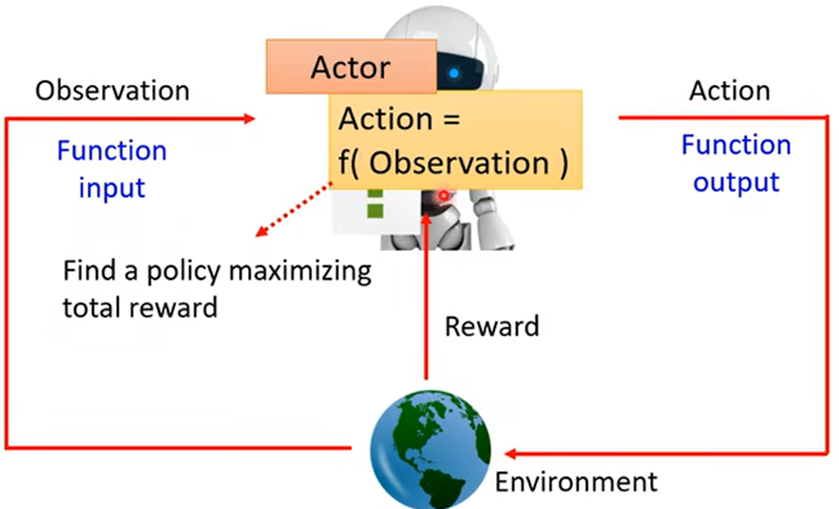
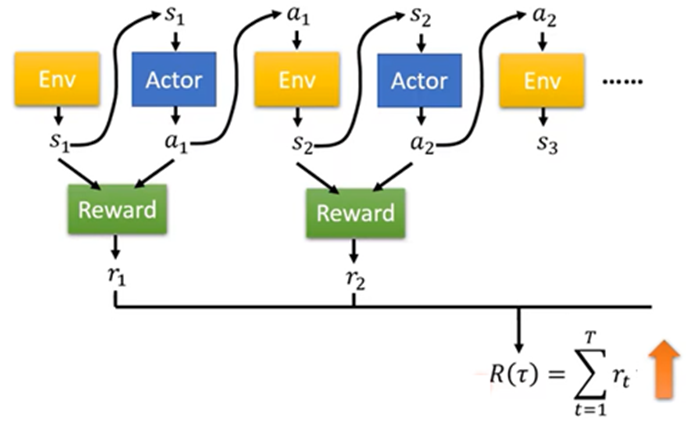
引入:增强式学习也是机器学习的一种,也在找一个函数,在增强式学习中,有一个Actor(参与者)和Environment(环境),Environment会给Actor一个Observation(观察),Actor会进行输出,给Environment一个Action,从而影响改变Environment,以此循环互动,Environment也会不断给Actor一些Reward(奖励),以此告诉Actor的Action好坏

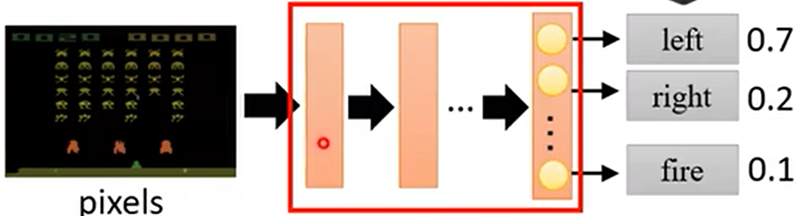
第一步:设置Actor的Network架构,输出为行为的分数
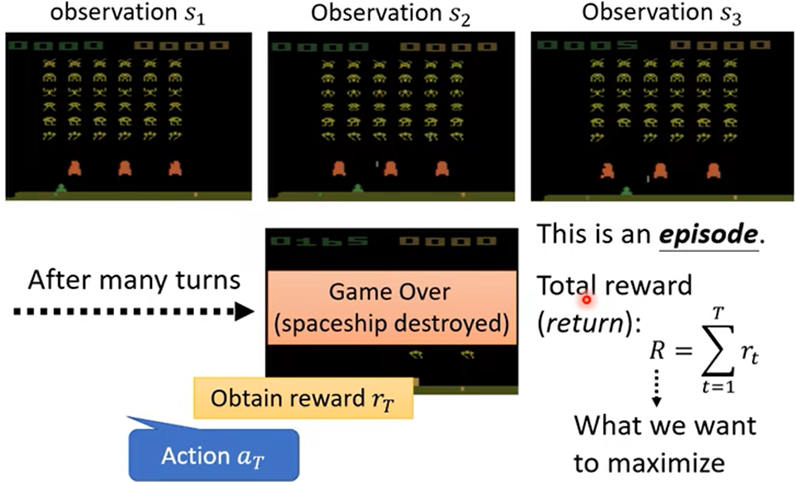
第二步:在一局游戏开始到结束整个过程中,机器的每个行为都可能得到Reward,把全部的Reward求和,即为Total Reward(总计分数),所以Loss可以为 -(Total Reward)
第三步:训练出Actor中参数是R(τ)越大越好(但训练中Actor的输出是有随机性;Env不是Network,而是黑盒子,Reward也不是Network,是规则;并且Env和Network可能也有随机性)
整个问题与GAN有相似之处:
- Actor就像Generator
- Env和Reward就像是Discriminator
- 在GAN中Discriminator也是Network
如何操控Actor的输出:可以当成分类问题处理,

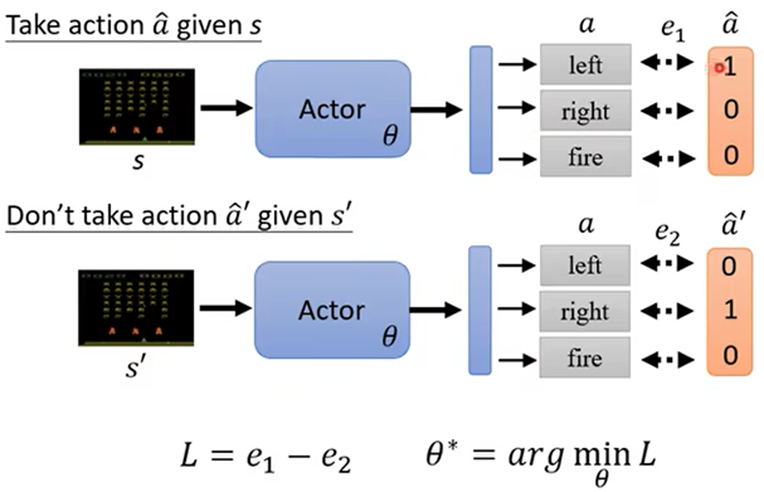
训练资料为某些输入的输出的分数(对于这个输入,这个输出有多好)
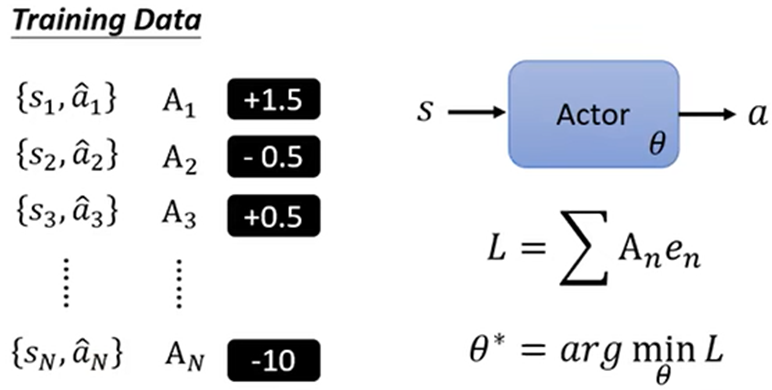
定义A(难点):
- 搜集训练资料,{s,a},a1行为有多好A1不仅取决于r1,而是取决于r1开始一直到结束的全部r,这样就可以避免所有移动的行为得分为0的情况(导致机器只专注于攻击)

- 当N比较大,游戏步伐多时,前边某步对后边的影响就会减弱,所以G’更合适:
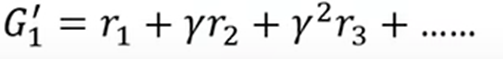
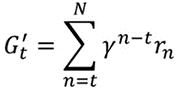
- 这样得出的Reward没有高低之分,不同的训练资料之间比较没有意义,所以需要标准化:使所有的G’都减一个Baseline(基线)

初始化参数后,进行跑T个数据去和环境做互动,记录{S,A},然后评价A,设置完A之后便可以定义Loss函数,Update模型中的参数
- On Policy:要被训练的Actor和用于和环境互动的Actor是同一个Actor
一批训练资料只能更新一次参数,更新完之后就需要重新搜集材料
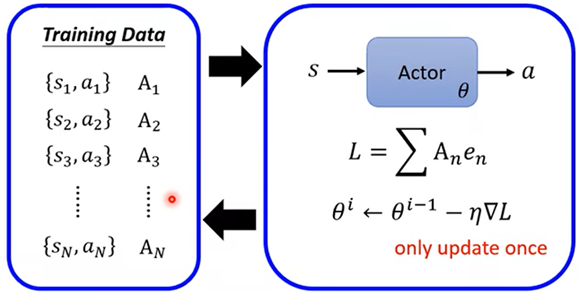
- Off policy:要被训练的Actor和用于和环境互动的Actor不是同一个Actor
通过一些方法可以让同一批资料重复训练,因为On Policy,每次训练之后Actor都会提升,之前的学习资料相对应现在的模型已经不适合了(自己与环境互动边玩边进步);Off Policy相当于看别人玩,自己学习而进步;同时Actor与环境互动时,做出的行为的随机性也应该大一些,这样才可以收集到更丰富的训练资料
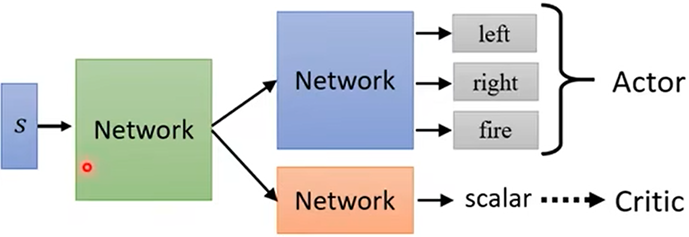
![]() :Critic估测某个Actor,用已经看到的游戏画面,估测这个Actor将得到多少奖励
:Critic估测某个Actor,用已经看到的游戏画面,估测这个Actor将得到多少奖励

- Reinforcement Learningreinforcement learning noise reinforcement exploration learning reinforcement transformer learning trainer reinforcement learning chapter reinforcement distillation teachable learning reinforcement transformer decision learning reinforcement exploration off-policy learning reinforcement modelling learning feedback reinforcement adversarial learning through learning reinforcement q-learning python