hadoop hdfs
Windows 配置 Hadoop and Spark
一 JDK环境配置 由于项目用的JDK17,所以单独给Hadoop配了JDK11,建议直接配置JAVA_HOME环境变量为JDK11,因为后面Spark需要用到JAVA_HOME 下载JDK11 链接:https://www.oracle.com/java/technologies/javase/j ......
Hudi表创建时HDFS上的变化
SparkSQL 建 Hudi 表语句: ```sql CREATE TABLE t71 ( ds BIGINT, ut STRING, pk BIGINT, f0 BIGINT, f1 BIGINT, f2 BIGINT, f3 BIGINT, f4 BIGINT ) USING hudi PAR ......
关于Hadoop集群无法正常关闭的问题
### 原生命令 正常情况我们是通过以下命令来停止和开启集群的 ```sh sbin/stop-all.sh sbin/start-all.sh ``` 但有时候不生效,通过ps还能查看到,但jps命令查看不到 ### 自定义停止命令 ```sh #!/bin/bash # 停止hadoop进程 h ......
Hadoop之YARN详解
### YARN的由来 从Hadoop2开始,官方把资源管理单独剥离出来,主要是为了考虑后期作为一个公共的资源管理平台,任何满足规则的计算引擎都可以在它上面执行。所以YARN可以实现HADOOP集群的资源共享,不仅仅可以跑MapRedcue,还可以跑Spark、Flink。 ### YARN架构分析 ......
Hadoop - hadoop介绍
Hadoop是什么 Hadoop的发展历史 Hadoop的优势 Hadoop是什么 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决海量数据的存储和海量数据的分析计算问题。广义上讲,Hadoop通常是指一个更广泛的概念 —— Hadoop生态圈。 Hadoop的发展历史 L ......
hadoop3.x-ec
一、EC原理 二、常用命令与对应解释 1.查看当前支持的EC策略 hdfs ec -listPolicies 2023-05-30 10:10:43,251 WARN util.NativeCodeLoader: Unable to load native-hadoop library for yo ......
Hadoop之MapReduce性能优化
现在大家已经掌握了MapReduce程序的开发步骤,注意了,针对MapReduce的案例我们并没有讲太多,主要是因为在实际工作中真正需要我们去写MapReduce代码的场景已经是凤毛麟角了,因为后面我们会学习一个大数据框架Hive,Hive支持SQL,这个Hive底层会把SQL转化为MapReduc ......
Hadoop之MapReduce详解
### 前言 前面我们学习了Hadoop中的HDFS,HDFS主要是负责存储海量数据的,如果只是把数据存储起来,除了浪费磁盘空间,是没有任何意义的,我们把数据存储起来之后是希望能从这些海量数据中分析出来一些有价值的内容,这个时候就需要有一个比较厉害的计算框架,来快速计算这一批海量数据,所以MapRe ......
hadoop安装使用
# hadoop相关介绍 ## 1.什么是hadoop? Hadoop是一个开源的分布式计算框架,它可以让我们在大规模集群中存储和处理海量数据。Hadoop基于Google的MapReduce和Google文件系统(GFS)的思想而设计。它的目标是能够在成百上千台普通计算机上并行处理大数据,提供高可 ......
hadoop序列化相关问题
**什么时候需要使用序列化?** *需要在不同服务器传递内存数据时,用序列化。* **序列化后的所有属性需要再反序列化,那么有先后顺序反序列化吗?** *有的,比如序列化的属性有a b c* *则反序列化的属性必须是 ca b c* **数据切片一般为数据块的倍数,为什么?** *一般一个数据切片对 ......
Hadoop全分布部署
安装包下载(百度网盘)链接: https://pan.baidu.com/s/1XrnbpNNqcG20QG_hL4RJoQ?pwd=aec9 提取码: aec9 ## 基础配置(所有节点) ### 关闭防火墙,selinux安全子系统 ````bash #关闭防火墙,设置开机自动关闭 [root@ ......
centos7上Hadoop2.7.2完全分布式部署
1.规划 node1 node2 node3datanode datanode datanodenamenode resourcemanager secondarynamenodenodemanager nodemanager nodemanager 2.设置环境 2.1 修改hostname主机名 ......
centos7.9上hadoop-2.7.2伪分布式部署
1.安装jdk 1.1 在Oracle官网上现在jdk1.8 ,然后上传到Linux服务器中 1.2 安装jdk rpm -ivh jdk-8u371-linux-x64.rpm 2 创建部署用户 hadoop useradd -d /hadoop hadoop echo 123 |passwd - ......
尚硅谷Hadoop的WordCount案例实操练习出现的bug
这个错误是由于WordCount程序在Windows系统上运行时,尝试调用了Hadoop的NativeIO类的access0方法,但无法找到正确的JNI库导致的UnsatisfiedLinkError异常。
NativeIO类是Hadoop用来执行一些本地文件操作的类,它依赖于JNI来调用Windo... ......
hdfs文件上传打包及bug汇总
#### 1、错误: 找不到或无法加载主类 删除META-INFO下的 .DSA和 .SF文件即可 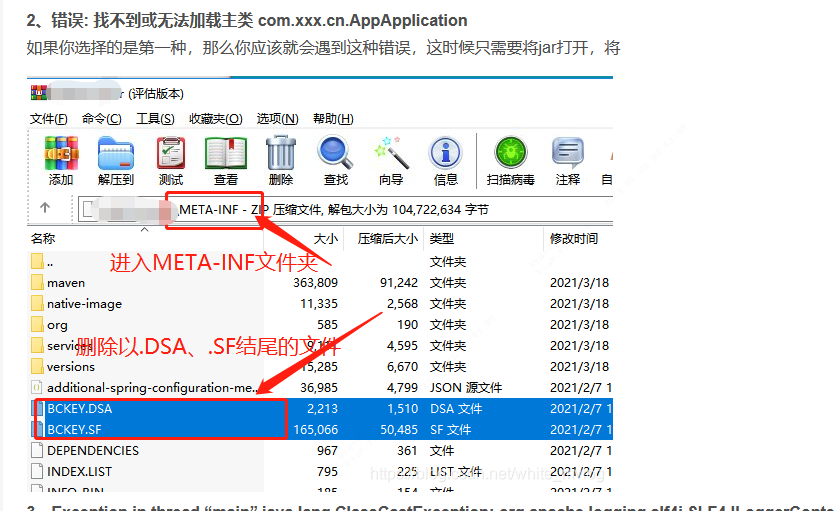 来源 [csdn ......
hdfs开启回收站(废纸篓)
# 1、背景 我们知道,在`mac`系统上删除文件,一般情况下是可以进入 `废纸篓`里的,如果此时我们误删除了,还可以从 废纸篓中恢复过来。那么在`hdfs`中是否存在类似mac上的`废纸篓`这个功能呢?答案是存在的。 ** [atguigu@hadoop102 hadoop-3.3.4]$ hadoop fs -appendToFile liubei.txt /sa 点击查看代码 ``` [atguigu@ ......
HDFS学习进阶
一、HDFS元数据管理 HDFS是一个分布式文件存储系统,文件分布式存储在多个DataNode节点上。一个文件存储在哪些DataNode节点的哪些位置的元数据信息(metadata)由NameNode节点来处理。随着存储文件的增多,NameNode上存储的信息也会越来越多。在HDFS中主要是通过两个 ......
HDFS学习基础
一、HDFS基础知识 HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大 ......
HDFS架构与原理浅析
当需要存储的数据集的大小超过了一台独立的物理计算机的存储能力时,就需要对数据进行分区并存储到若干台计算机上去。管理网络中跨多台计算机存储的文件系统统称为分布式文件系统(distributed fileSystem)。 分布式文件系统由于其跨计算机的特性,所以依赖于网络的传输,势必会比普通的本地文件系 ......
hadoop集群搭建后,启动集群后网络畅通,却无法访问web页面的解决办法
# hadoop集群搭建后,启动集群后网络畅通,却无法访问web页面的解决办法 > 问题引入:在学习hadoop搭建完全分布式集群时,已经集群配置了4个核心文件,并且启动所有相关进程,在使用jps命令检查进程,该集群启动完整正常,但是无法访问hdfsweb页面和yarnweb页面,我尝试了ping通 ......
hadoop 2.7.7 ERROR datanode.DataNode: BlockSender.sendChunks() exception: java.io.IOException: 你的主机中的软件中止了一个已建立的连接。
最近在测试Hbase在windows上的单机版的功能。 版本:hadoop 2.7.7 hbase 2.0.0 错误: ERROR datanode.DataNode: BlockSender.sendChunks() exception: java.io.IOException: 你的主机中的软件 ......
Hadoop-3.3.5单机版安装步骤
1.下载JDK和Hadoop[略] 2.解压[略] 3.创建hadoop数据存储的目录 mkdir -p /home/hadoop/tmp /home/hadoop/hdfs/data /home/hadoop/hdfs/name 4.配置JAVA环境和HADOOP_HOME vim /etc/pr ......
hadoop多节点,单词数计算,java代码
1、pom.xml代码 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-inst ......
hadoop distcp 参数详解
distcp 是一个用于数据复制的工具,它可以将数据从一个 Hadoop 集群复制到另一个 Hadoop 集群。 Usage: hadoop distcp [OPTIONS] <srcurl> <desturl> OPTIONS: -p[rbugpcax] Preserve status (rbug ......
hadoop中distcp的mapreduce任务中的task0详解及优化
distcp 是 Hadoop 中一个用于数据复制的工具,可用于大规模数据复制场景。在 distcp 执行过程中,会运行多个 MapReduce 任务,其中第一个任务通常被称为 "task0" 或 "main task"。 task0 主要负责以下操作: 解析命令行参数并生成 distcp 配置。 ......
Hadoop API使用 大坑
这几天一直在困扰我 pycurl 版本和本机的版本不符合 他连接又连接的自己自带的版本 与系统不相同 低级也会报错 https://blog.csdn.net/u010910682/article/details/89496550/?ops_request_misc=&request_id=&biz ......
hadoop基础
大数据的5v特征 一、Volume:数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。 二、Variety:种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类 ......
hadoop启动脚本
if (($# < 1)); then echo no args input, exit. exit 1 fi case $1 in start) echo [INFO] starting dfs ... start-dfs.sh echo [INFO] done. echo [INFO] star ......