hadoop3 hadoop hive3 hive
8.7-8.13学习总结博客五:Hive进阶与复杂查询
博客题目:学习总结五:Hive进阶与复杂查询实践内容概要:学习Hive进阶的使用方法,包括复杂查询、数据转换和性能优化等方面的知识。学习资源:推荐的Hive进阶教程、实践案例和性能优化技巧。实践内容:通过编写复杂的Hive查询语句,探索Hive的高级功能和性能优化方法,并分享实践中的挑战和解决方案。 ......
假期总结之Hive基础架构
Apache Hive其2大主要组件就是:SQL解析器以及元数据存储, 如下图。 元数据存储 通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 -- Hive提供了 Metastore 服务进 ......
Hadoop----hdfs dfs常用命令的使用
-mkdir 创建目录 hdfs dfs -mkdir [-p] < paths> -ls 查看目录下内容,包括文件名,权限,所有者,大小和修改时间 hdfs dfs -ls [-R] < args> -put 将本地文件或目录上传到HDFS中的路径 hdfs dfs -put < localsrc ......
hive处理字符串化数组
大数据在进行ETL过程中,为了避免因为源、目标表字段因为数据类型不一致造成抽数失败,所以在目标表一般都会将字段设置成string类型,后续数据同步过来后再进行类型转换。 以ARRAY类型字段举例: 通过正则将字符串左右两边的中括号[]进行去除 explode(split(REGEXP_REPLACE ......
hive 的order by ,sort by,distribute by,cluster by
order by order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间,在生产环境中遇到数据量较大的情况,一般无法成功。 sort by sort by不是全局排序,其在数据进入r ......
大数据-hive 添加分区
1、静态分区1> 添加一个alter table t2 add partition (city=‘shanghai’);2> 添加多个alter table t2 add partition (city=‘chengdu’) partition(city=‘tianjin’);3> 添加分区指定位置 ......
Hadoop初体验
# 1、HDFS初体验 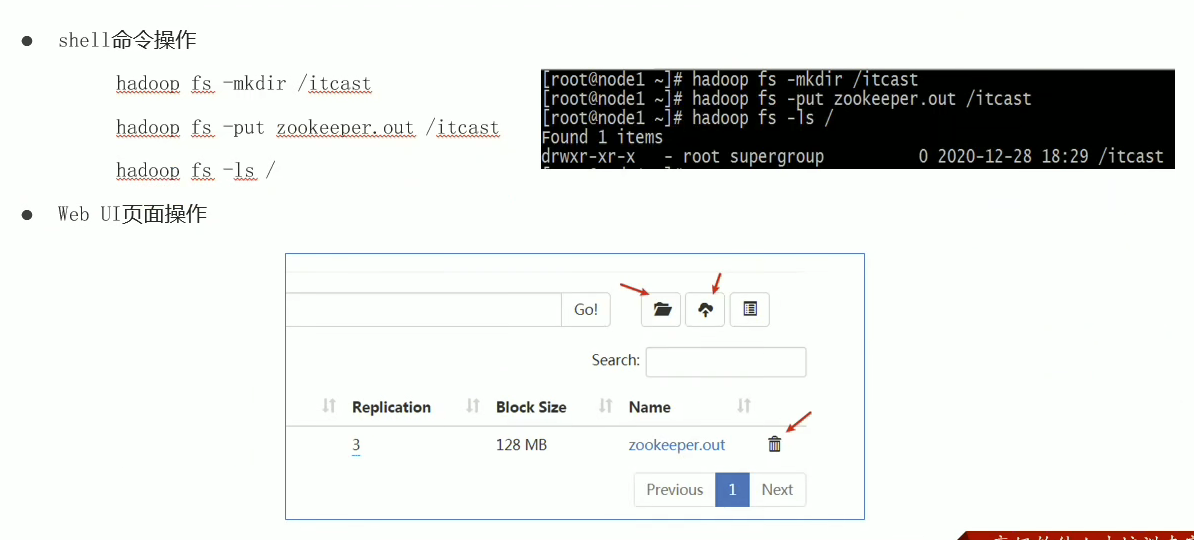 既能够通过后台的终端命令进行文件的管理,也可以通过Web UI界面进行相关的操作; 可以知 ......
Hadoop集群启停命令以及Web UI界面的相关介绍
# 1、Hadoop集群的启停命令(我是将文件都配置好了,直接使用最方便的启停命令就能进行使用) ``` start-all.sh stop-all.sh ``` # 2、HDFS集群的Web UI界面  ``` cd ../.. ```  ......
Linux系统下安装Hadoop环境
# 安装Hadoop的话,是在安装好JDK和MYSQL之后的环境下进行的;还没有安装的话,可以跳转到安装jdk环境(https://www.cnblogs.com/liuzijin/p/17591188.html) # 和安装mysql环境(https://www.cnblogs.com/liuzi ......
Hive之分区表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了 同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。 如图,一个典型的按月份分 ......
Hadoop:哪个数据节点是最近的数据节点来检索数据以及节点如何实现容错性
# Q1 who can decide which Data Node is the closest datanode to retrieve the data? 当客户端要读一个文件的某个数据块时,它就需要向NameNode节点询问这个数据块存储在哪些DataNode节点上,这个过程如下图:![i ......
【Windows】Windows10系统下Hadoop和Hive环境搭建
环境准备 软件 版本 备注 Windows 10 操作系统 JDK 8 暂时不要选用大于等于JDK9的版本,因为启动虚拟机会发生未知异常 MySQL 8.x 用于管理Hive的元数据 Apache Hadoop 3.3.1 - Apache Hive 3.1.2 - Apache Hive src ......
hive之内部表与外部表
hive之内部表与外部表 内部表&外部表定义:未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);区别: 内部表数据由Hive自身管理,外部表数据由HDFS管理;内部表数据存储的位置是hive.metastore.war ......
数仓 Hive HA 介绍与实战操作
[TOC] ## 一、概述 在数据仓库中,`Hive HA(High Availability)` 是指为 `Apache Hive` 这个数据仓库查询和分析工具提供高可用性的架构和解决方案。Hive是建立在Hadoop生态系统之上的一种数据仓库解决方案,用于处理大规模数据的查询和分析。为了确保Hi ......
Hadoop完全分布式集群安装
# Hadoop完全分布式集群安装 >使用版本: hadoop-3.2.0 ## 安装VMware 看一下这张图,图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。 不同节点上面启动的进程默认是不一样的。  ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEP ......
hive同时使用where,group by,having,order by的执行顺序
###hive中分组排序过滤使用顺序。 ``` where,group by,having,order by同时使用,执行顺序为 (1)where过滤数据 (2)对筛选结果集group by分组 (3)对每个分组进行select查询,提取对应的列,有几组就执行几次 (4)再进行having筛选每组数 ......
RDBMS与Hbase对比 HDFS与HBase对比 Hive与HBase对比
RDBMS: HBASE: HDFS与HBase对比: Hive与HBase对比: Hive与HBase总结 ......
Hadoop集群相关理解
# Hadoop集群简介  # Hadoop集群模式安装 # 安装包获得 ## Hadoop安装包、源码包下载地址: ......