scrapy ja3 tls ja
【网络】【TCP】HTTPS 中 TLS 和 TCP 能同时握手吗?
1 前言 这节我们来看个问题,就是 HTTPS 中 TLS 和 TCP 能同时握手吗? 通常情况下,HTTPS 建立连接的过程,先进行 TCP 三次握手,再进行 TLS 四次握手,比如,下面这个 TLSv1.2 的 基于 RSA 算法的四次握手过程: 不过 TLS 握手过程的次数还得看版本。 TLS ......
scrapy架构
## 1 selenium爬取京东商品信息 ```python import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common. ......
TLS原理与实践(三)tls1.3
## 主页 - 个人微信公众号:密码应用技术实战 - 个人博客园首页:https://www.cnblogs.com/informatics/ ## 引言 tls1.2作为主流的网路安全协议,被广泛应用,但tls1.2仍存在一些安全隐患和性能问题,如: - MD5、SHA-1算法已被破解,不再安全 ......
Scrapy框架爬取cnblog实例
Scrapy框架爬取cnblog下一页简单实例 **犯了一个错误:直接拿浏览器点出来第二页链接去做拼接,导致一直爬不到下一页** : name = 'blogspider' start_urls = ['https://www.zyte.com/blog/'] def parse(self, response): for title in ......
【慢慢买嗅探神器】基于scrapy+pyqt的电商数据爬虫系统
### 项目预览 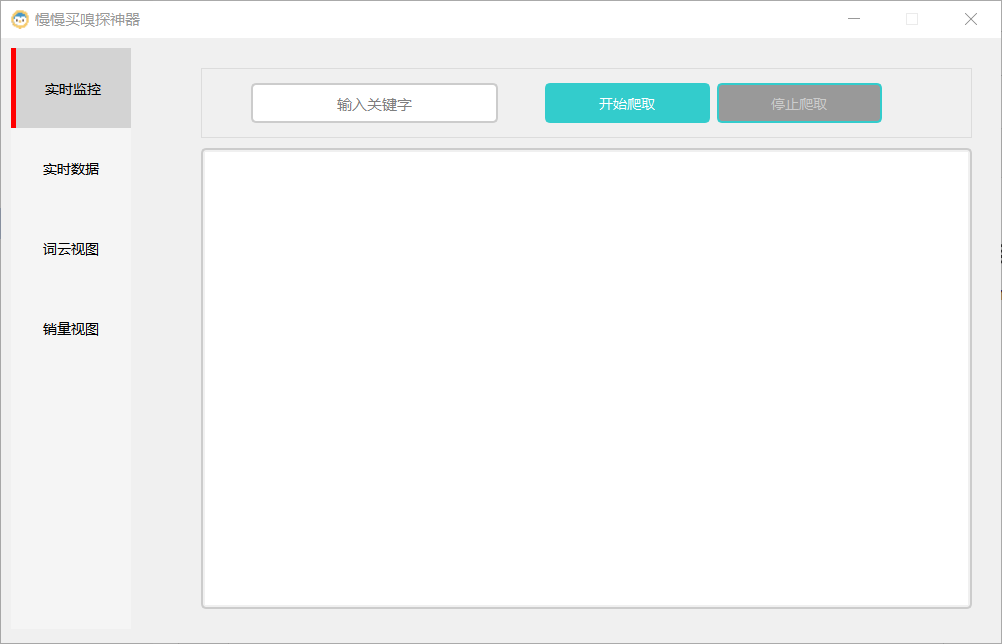  http://www.cwl.gov.cn/ygkj/wqkjgg/ 代码 class MongoPipeline: def open_spider(self, spider): self ......
爬虫-Scrapy框架安装使用2
Scrapy 框架其他方法功能集合笔记 ### 使用LinkExtractor提取链接 - 使用Selector ``` import scrapy from bs4 import BeautifulSoup class BookSpider(scrapy.Spider): name = "book ......
scrapy 2.x相关配置
使用pip安装scrapy之后可能并不能直接运行,会遇到各种报错,可能是依赖库的版本不兼容导致的,可能需要安装或更新以下依赖: cryptography==38.0.4pyopenssl==22.0.0certifi==2023.5.7 在windows python3.8+下的scrapy框架 ......
Python 自建 IP 代理池 - Scrapy 重构
### 1 重构说明 这是项目 [Python 自建 IP 代理池](https://www.cnblogs.com/zishu/p/17316593.html) 的重构版本,学习了 scrapy 框架的使用,并用该框架对之前项目进行了重构,得益于 scrapy 框架本身的优秀设计,之前手撸的小框架 ......
[scrapy]一个简单的scrapy爬虫demo
# 一个简单的scrapy爬虫demo ## 爬取豆瓣top250的电影名称+电影口号 使用到持久化流程: * 爬虫文件爬取到数据后,需要将数据封装到items对象中。 * 使用yield关键字将items对象提交给pipelines管道进行持久化操作。 * settings.py配置文件中开启管道 ......
爬虫:爬到的数据存到mysql中、爬虫和下载中间件、加代理,cookie、header、加入selenium、集成selenium、==去重规则源码分析(布隆过滤器)、布隆过滤器、scrapy-redis实现分布式爬虫
[toc] ### 爬到的数据存到mysql中 ```python class FirstscrapyMySqlPipeline: def open_spider(self, spider): print('我开了') self.conn = pymysql.connect( user='root' ......
爬虫:scrapy架构介绍、scrapy解析数据、settings相关配置,提高爬取效率、持久化方案、全站爬取cnblogs文章
[toc] ### scrapy架构介绍 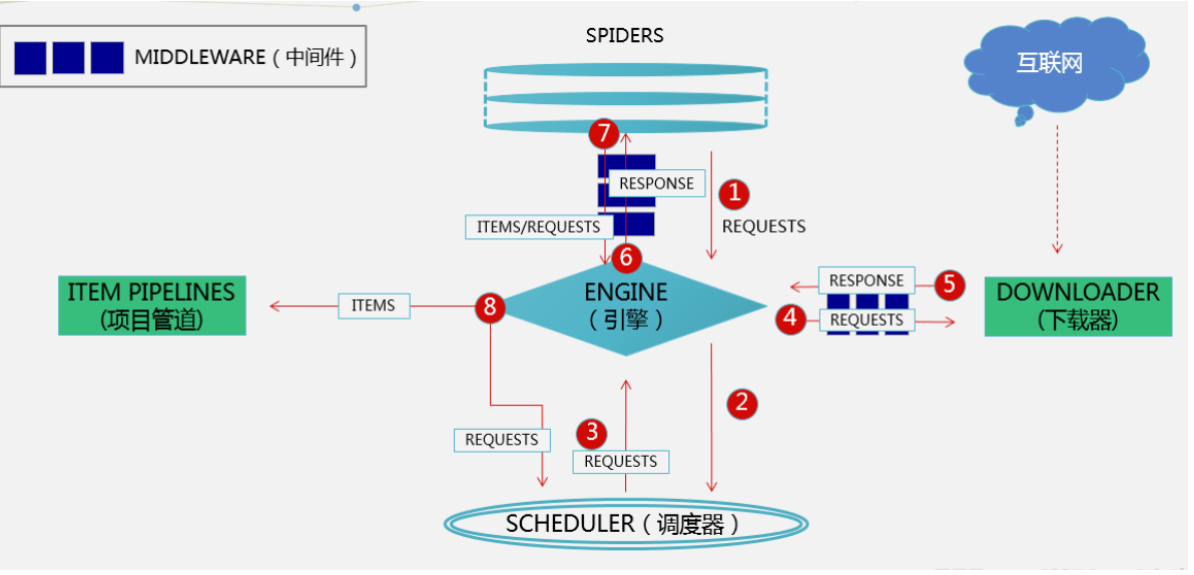 ```python # 引擎(EGINE) 引擎负责控制系统所 ......
如何将TLS的安全证书和密钥保存到k8s的secret中?以及在ingress中使用secret中的证书?
如果要ingress的域名增加TLS的证书,该怎么办? 那如何将证书和密钥保存到k8s的secret中呢? 如果使用自签名的证书,使用下面的命令创建密钥和证书 [root@nccztsjb-node-23 secrets]# openssl req -x509 \ > -newkey \ > rsa ......
下载中间件实战-Scrapy与Selenium结合
下载中间件实战-Scrapy与Selenium结合 有的页面反爬技术比较高端,一时破解不了,这时我们就是可以考虑使用selenium来降低爬取的难度。 问题来了,如何将Scrapy与Selenium结合使用呢? 思考的思路: 只是用Selenium来帮助下载数据。因此可以考虑通过下载中间件来处理这块 ......
Scrapy 中 Downloader 设置代理
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware class MyProxyMiddleware: def process_request(self, request, spider): # request. ......
Scrapy_下载中间件设置UserAgent
Scrapy 中 Downloader 设置UA 下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。 通过可下载中间件,可以处理请求之前和请求之后的数据。 如果使用下载中间件需要在Scrapy中的setting.py的配置DOWNLOADER_MIDDLEWARES才可以使 ......
Scrapy中下载中间件
Scrapy中下载中间件 下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。 通过可下载中间件,可以处理请求之前和请求之后的数据。 每个中间件组件都是一个Python类,它定义了一个或多个以下方法,我们可能需要使用方法如下: process_request() proces ......
Scrapy_FormRequest对象的使用
FormRequest是Request的扩展类,具体常用的功能如下: 请求时,携带参数,如表单数据 从Response中获取表单的数据 FormRequest类可以携带参数主要原因是:增加了新的构造函数的参数formdata。其余的参数与Request类相同. formdata参数类型为:dict ......
Scrapy_Request对象Cookie的演示
Cookie的使用 import scrapy class CookieSpider(scrapy.Spider): name = "爬虫名" allowed_domains = ["域名.com"] start_urls = ["url地址"] def start_requests(self): ......
Scrapy_Request对象dont_filter演示
import scrapy class BaiduSpider(scrapy.Spider): name = "baidu" allowed_domains = ["baidu.com"] start_urls = ["https://baidu.com"] def parse(self, resp ......
Scrapy_Request对象meta演示
request里面的meta 的使用 import scrapy class Xs2Spider(scrapy.Spider): name = "爬虫名" allowed_domains = ["域名"] start_urls = ["url地址"] def parse(self, response ......
Scrapy 中 Request 的使用
爬虫中请求与响应是最常见的操作,Request对象在爬虫程序中生成并传递到下载器中,后者执行请求并返回一个Response对象 一个Request对象表示一个HTTP请求,它通常是在爬虫生成,并由下载执行,从而生成Response 参数 url(string) - 此请求的网址 callback(c ......
Scrapy 中 CrawlSpider 使用(二)
LinkExtractor提取链接 创建爬虫 scrapy genspider 爬虫名 域名 -t crawl spider from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, ......
Scrapy 中 CrawlSpider 使用(一)
创建CrawlSpider scrapy genspider -t crawl 爬虫名 (allowed_url) Rule对象 Rule类与CrawlSpider类都位于scrapy.contrib.spiders模块中 class scrapy.contrib.spiders.Rule( lin ......