搜索结果
【GUI软件】抖音搜索结果批量采集,支持多个关键词、排序方式、发布时间筛选等!
目录一、背景介绍1.1 爬取目标1.2 演示视频1.3 软件说明二、代码讲解2.1 爬虫采集模块2.2 软件界面模块2.3 日志模块三、获取源码及软件 一、背景介绍 1.1 爬取目标 您好!我是@马哥python说,一名10年程序猿。 我用python开发了一个爬虫采集软件,可自动按关键词抓取抖音视 ......
一种可以实现搜索结果按照相似度排序的sql写法,核心是 分词和order by like 的使用
常规的搜索一般使用like执行模糊搜索,这种搜索有个缺陷,一旦搜索内容里面有一个错的就会导致搜索失败。 有没有一种实现可以容错的且按照相似度排序的方法呢?类似百度 google那样的。 经过自己的测试发现使用分词结合排序的order by like 可以实现。 我直接给出例子sql的吧 比如搜索内容 ......
【GUI软件】小红书搜索结果批量采集,支持多个关键词同时抓取!
目录一、背景介绍1.1 爬取目标1.2 演示视频1.3 软件说明二、代码讲解2.1 爬虫采集模块2.2 软件界面模块2.3 日志模块三、获取源码及软件 一、背景介绍 1.1 爬取目标 您好!我是@马哥python说 ,一名10年程序猿。 我用python开发了一个爬虫采集软件,可自动按关键词抓取小红 ......
mysql 搜索多个结果
SELECT (select vlu from dept_1 d where dname='n' and loc='n') AS res1, (select vlu from dept_1 d where dname='y' and loc='y') AS res2; ......
【教你写爬虫】用Java爬虫爬取百度搜索结果!可爬10w+条!
一、爬取目标 大家好,我是盆子。今天这篇文章来讲解一下:使用Java爬虫爬取百度搜索结果。 首先,展示爬取的数据,如下图。 爬取结果1: 爬取结果2: 代码爬取展示: 可以看到,上面爬取了五个字段,包括 标题,原文链接地址,链接来源,简介信息,发布时间。 二、爬取分析 用到的技术栈,主要有这些 Pu ......
爬取behance搜索结果图片背后详情页的链接
目的:我需要搜索多个behance结果,如“washing machine","refrigerator"等,把结果下详情页高清大图都下载到本地。这样我就获得了“冰箱”的大量高清图。程序作用:爬取多个搜索结果下的详情页链接,并新建文件后保存在桌面txt文件中,如“washing machine.tx ......
Python爬虫-爬取百度搜索结果页的网页标题及其真实网址
共两个依赖的需提前安装的第三方库:requests和bs4库 cmd命令行输入安装requests库:pip3 install -i https://pypi.douban.com/simple requests 安装bs4库:pip3 install -i https://pypi.douban. ......
GoodBye CSDN!使用油猴脚本在搜索框中添加条件,以过滤掉csdn的搜索结果
直接上脚本 // ==UserScript== // @name GoodbyeCSDN // @namespace isakovsky // @version 1.0 // @description 在搜索引擎上自动添加文本到搜索关键词后面 // @include *://*.bing.com/* ......
6. Q_ 如果你有一个搜索结果页面,你想高亮搜索的关键词。什么HTML 标签可以使用_
6. Q: 如果你有一个搜索结果页面,你想高亮搜索的关键词。什么HTML 标签可以使用? A:`` 标签表现高亮文本。 > The HTML `` Element represents highlighted text, i.e., a run of text marked for referenc ......
sql中的子查询返回的搜索结果不止一条应该如果处理
在使用有子查询的查询语句时,遇到子查询的返回条数不止一条,就可以使用 in 这个条件进行解决,同时使用 distinct 这个条件对 left join查询出现多个重复内容进行去重操作 select distinct * FROM A left join B on A.Aid= B.Bid wher ......
【python爬虫案例】用python爬取百度的搜索结果!2023.3发布
[toc] # 一、爬取目标 本次爬取目标是,百度搜索结果数据。以搜索”马哥python说“为例: 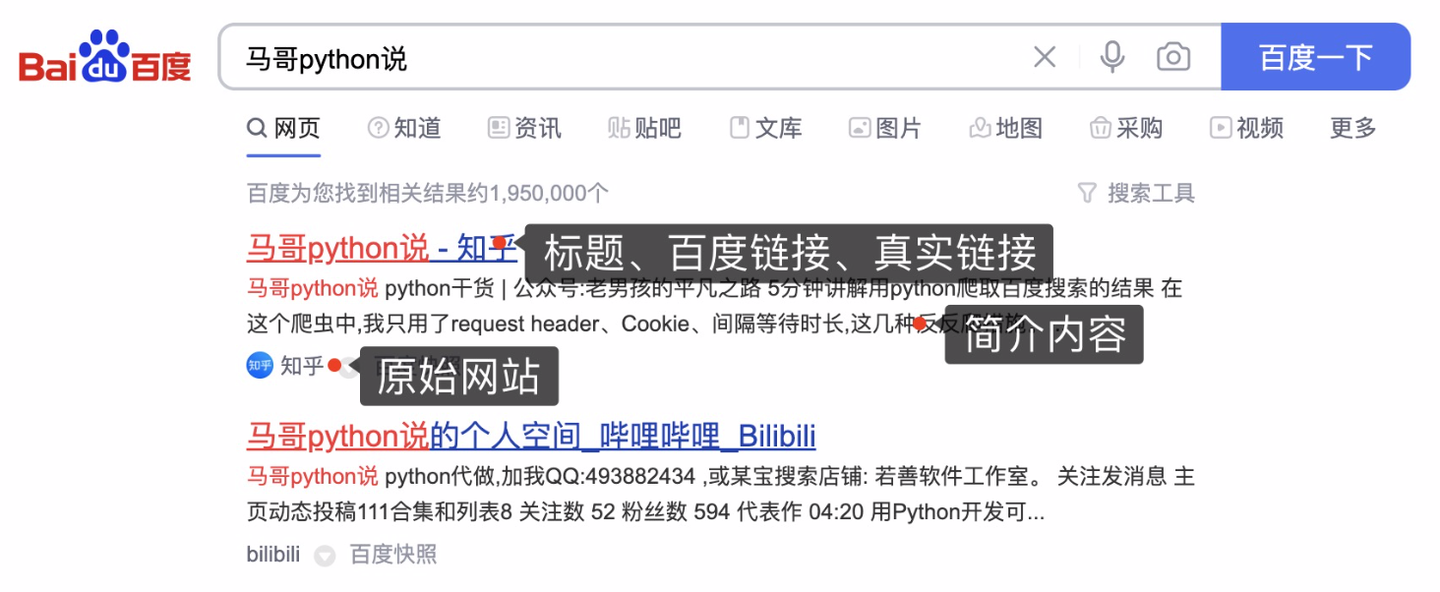 爬取字 ......
17-搜索结果处理-分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。 elasticsearch中通过修改from、size参数来控制要返回的分页结果: from:从第几个文档开始 size:总共查询几个文档 类似于mysql中的limit ?, ? 基本的分页 ......
16-搜索结果处理-排序
搜索的结果可以按照用户指定的方式去处理或展示。 排序 elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。 普通字段排序 keyword、数值、日期类型排序的语法基本一致 ......
djangoadmin后台搜索结果筛选自定义模版
django-admin对搜索结果进行自定义统计,可参考代码如下: def changelist_view(self, request, extra_context=None): #cur1_time = datetime.now() data_dict = {} value = request.G ......
使用 volatility 发现内存中的恶意软件——malfind的核心是找到可疑的可执行的内存区域,然后反汇编结果给你让你排查,yarascan是搜索特征码
如果是vol3的话,我没有找到合适的命令行可以等价输出(感觉是vol3这块还没有足够成熟),因此:本文使用的是vol2,下载地址:http://downloads.volatilityfoundation.org/releases/2.6/volatility_2.6_win64_standalon ......
调用百度云api人脸库搜索代码及结果展示
# encoding:utf-8 import base64 import requests def getToken(): ak='B7E2OqVuDAyDs7OsuGPuKa4y' sk='idObOz6jqA2GdU49L2VG4VPVhgmiidvD' host = f'https://ai ......
从百度搜索结果列表里点击 CSDN 博客时 url 参数的含义
我在百度里根据某关键字搜索后,在结果列表里找到 CSDN 某篇博客,点击之后,进入博客页面,注意到地址栏里的 url 很长: https://blog.csdn.net/i042416/article/details/117606987?ops_request_misc=%257B%2522requ ......
高德地图搜索结果如何导出成excel里?
地图搜索左边查询的商家如何导出到EXCEL里?解决销售人员一个一个从地图上翻找复制客户信息的低下效率、 销售人员就应该专心去做他们擅长的业务营销! 经过一段时间的琢磨,经过长时间的反复测试,做出了导出地图商家电话到EXCEL里的系统 操作步骤: 1. 选择你要采集的省份, 城市列表里就会有相应的省份 ......