A unified model for multi-class anomaly detection
1 Introduction
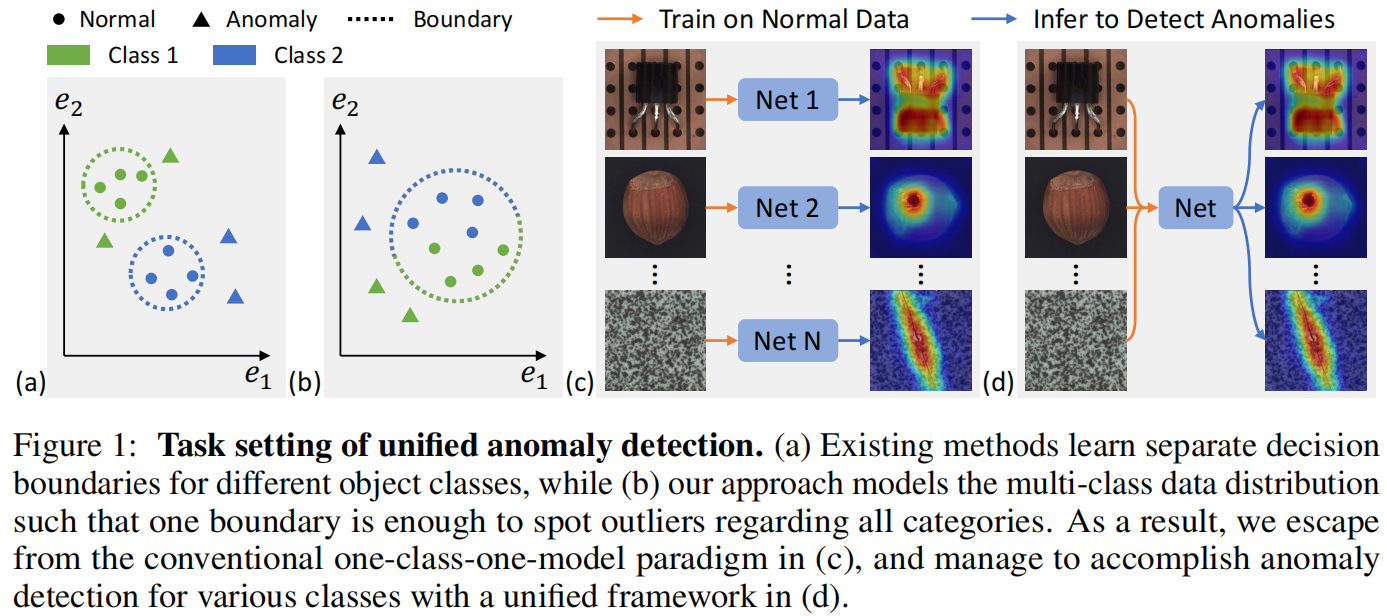
现有方法[6, 11, 25, 27, 48, 49, 52]建议为不同类别的对象训练单独的模型,就像图1c中的情况一样。然而,这种一类一模型的方案可能会消耗大量内存,尤其是随着类别数量的增加,并且不适用于正常样本表现出较大的类内多样性的场景(即一个对象包含多种类型)。
任务设置如图1d所示,训练数据涵盖了来自多个类别的正常样本,学习的模型被要求在不需要进行任何微调的情况下,对所有这些类别进行异常检测。值得注意的是,在训练和推断阶段都无法获取分类信息(即类别标签),这极大地减轻了数据准备的难度。
学习正常数据分布的一个广泛使用的方法是基于图像(或特征)重构[2, 5, 26, 39, 51],该方法假设一个训练良好的模型总是能够产生正常样本,而不考虑输入中的缺陷。这样,对于异常样本来说,会产生较大的重构误差,使它们能够与正常样本区分开来。然而,我们发现在这项研究中,流行的重构网络在这个具有挑战性的任务上表现不佳。它们通常陷入了“identity shortcut”,即无论输入内容如何,都会返回输入的直接副本。
contribution
- 重新审视了神经网络中使用的全连接层、卷积层以及注意力层的公式。提出了一个 layer-wise query decoder 来加强 query embedding 的使用
- 为了避免信息泄露,我们采用了一个neighbor masked attention模块,其中特征点既不与自身相关,也不与其邻居相关。
- 我们提出了一种feature jittering策略,要求模型即使在有噪声的输入情况下也能恢复源消息。
3 Method
3.1 Revisiting feature reconstruction for anomaly detection
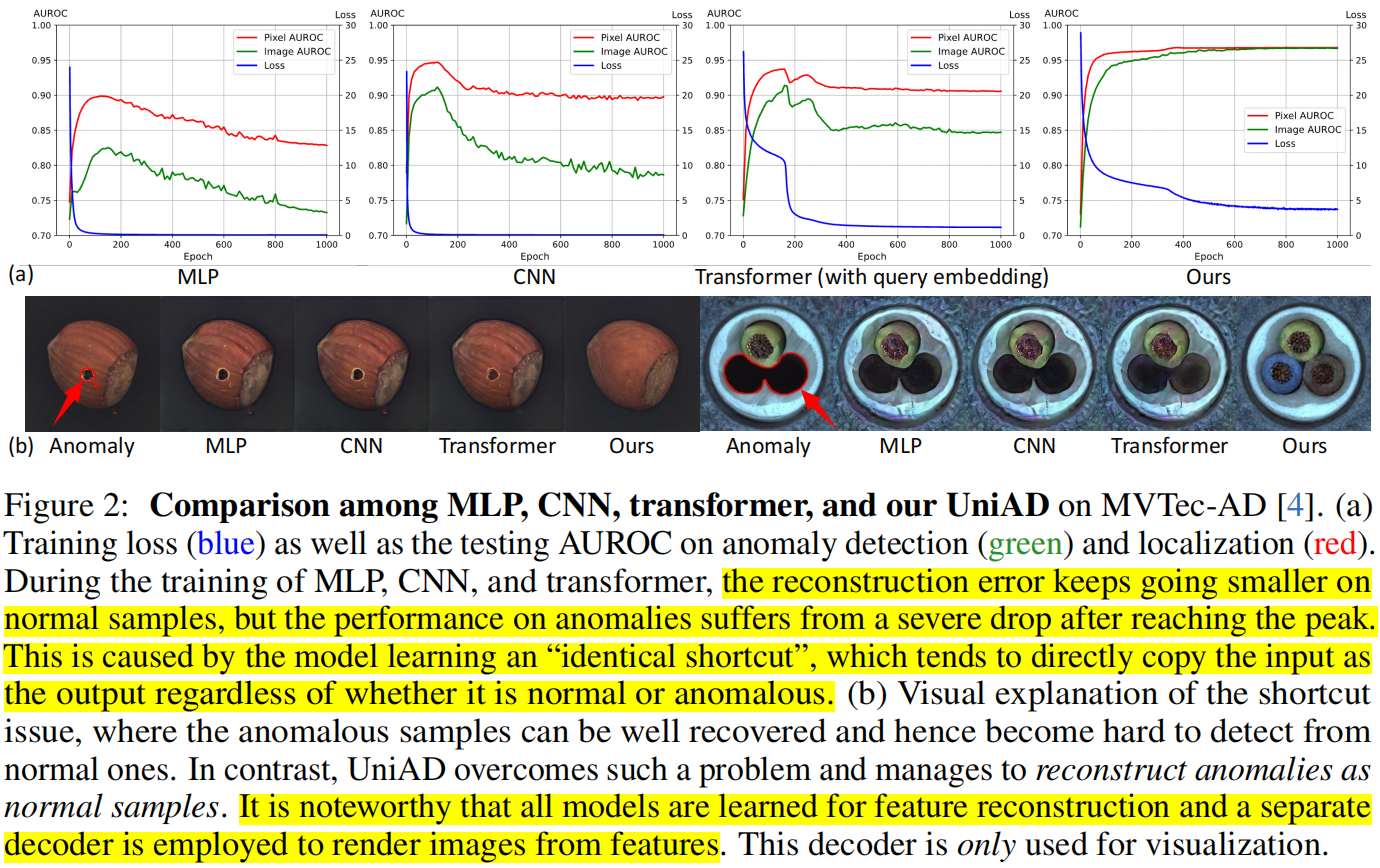
正如图2a所示,在一段训练期后,三个网络的性能明显下降,损失变得极小。我们将这归因于“identical shortcut”问题,即正常和异常区域都能被很好地恢复,因此无法发现异常。与多层感知器(MLP)和卷积神经网络(CNN)相比,Transformer 的性能下降更小,表明了更轻微的捷径问题。
我们用 \(\boldsymbol{x}^{+} \in \mathbb{R}^{K \times C}\) 表示正常图像中的特征,其中 \(K\) 是特征数量,\(C\) 是通道维度。为简单起见,批处理维度被省略。同样地,异常图像中的特征被表示为 \(\boldsymbol{x}^{-} \in \mathbb{R}^{K \times C}\)。重建损失选为均方误差损失。
我们使用一个简单的单层网络作为重建网络进行了初步分析,该网络使用 \(\boldsymbol{x}^{+}\) 进行训练,并测试以检测 \(\boldsymbol{x}^{-}\) 中的异常区域。
Fully-connected layer in MLP
将该层中的权重和偏置记为 \(\boldsymbol{w} \in \mathbb{R}^{C \times C}, \boldsymbol{b} \in \mathbb{R}^C\),该层可以表示为:
通过均方误差损失将 \(\boldsymbol{y}\) 推向 \(\boldsymbol{x}^{+}\),模型可能采用捷径回归 \(\boldsymbol{w} \rightarrow \boldsymbol{I}\)(单位矩阵),\(\boldsymbol{b} \rightarrow \mathbf{0}\)。最终,该模型也可能很好地重建 \(\boldsymbol{x}^{-}\),导致异常检测失败。
Convolutional layer in CNN
具有 \(1 \times 1\) 卷积核的卷积层等效于一个全连接层。此外,\(n \times n(n>1)\) 卷积核具有更多参数和更大的容量,可以完成 \(1 \times 1\) 卷积核能够完成的任务。因此,该层也有学习捷径的可能性。
Transformer with query embedding.
在这样的模型中,有一个带有可学习查询嵌入的注意力层,\(\boldsymbol{q} \in \mathbb{R}^{K \times C}\)。当将该层用作重建模型时,表示为:
为了将 \(\boldsymbol{y}\) 推向 \(\boldsymbol{x}^{+}\),注意力图 softmax \(\left(\boldsymbol{q}\left(\boldsymbol{x}^{+}\right)^T / \sqrt{C}\right)\) 应近似于 \(\boldsymbol{I}\)(单位矩阵),因此 \(\boldsymbol{q}\) 必须与 \(\boldsymbol{x}^{+}\) 高度相关。考虑到训练模型中的 \(\boldsymbol{q}\) 与正常样本相关联,该模型可能无法很好地重建 \(\boldsymbol{x}^{-}\)。第4.6节中的消融研究显示,在没有查询嵌入的情况下,Transformer 的性能分别下降了 \(18.1 \%\) 和 \(13.4 \%\),在异常检测和定位方面。因此,查询嵌入对于建模正常分布至关重要。
然而,Transformer 仍然存在捷径问题,这启发了我们的三个改进点。
- 根据查询嵌入可以防止重建异常的观察,我们设计了一个Layer wise Query Decoder(LQD),通过在每个解码器层中添加查询嵌入,而不仅仅是在原始 Transformer 的第一层中添加。
- 我们怀疑全注意力增加了捷径的可能性。由于一个token可以看到自身和其相邻区域,简单地复制即可进行重建。因此,在计算注意力图时,我们屏蔽了相邻标记,称为Neighbor Masked Attention (NMA)。
- 我们采用 Feature Jittering(FJ)策略扰乱输入特征,使模型从去噪中学习正常分布。得益于这些设计,我们的 UniAD 实现了令人满意的性能,如图2所示。
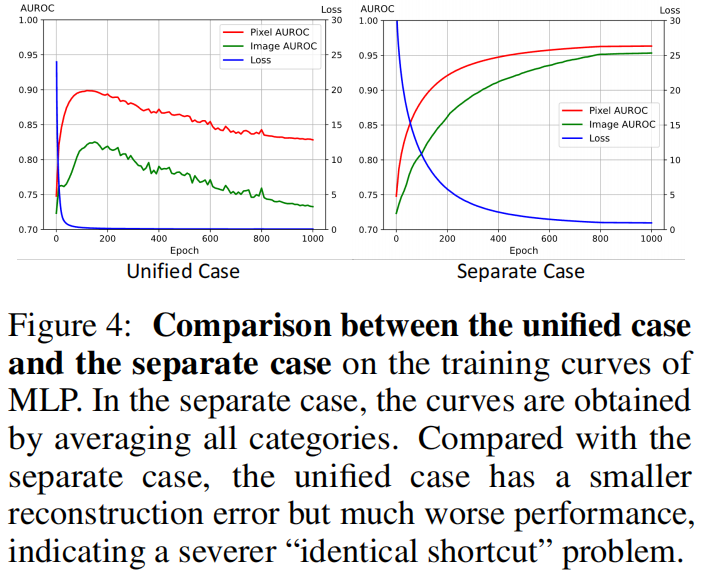
“相同捷径”问题与统一情况之间的关系。在图2a中,我们旨在可视化“相同捷径”问题,即损失变小但性能下降。
3.2 Improving feature reconstruction for unified anomaly detection
Overview
如图3所示,我们的UniAD由一个Neighbor Masked Encoder(NME)和一个Layer-wise Query Decoder(LQD)组成。首先,通过一个固定的预训练主干提取的特征标记被NME进一步整合,以得到编码器嵌入。然后,在LQD的每一层中,一个可学习的查询嵌入依次与编码器嵌入和前一层的输出进行融合(对于第一层进行自融合)。特征融合由Neighbor Masked Attention(NMA)完成。LQD的最终输出被视为重建的特征。此外,我们提出了一个Feature Jittering(FJ)策略,向输入特征添加扰动,使模型能够从去噪任务中学习正常分布。最后,通过重建差异获得异常定位和检测的结果。
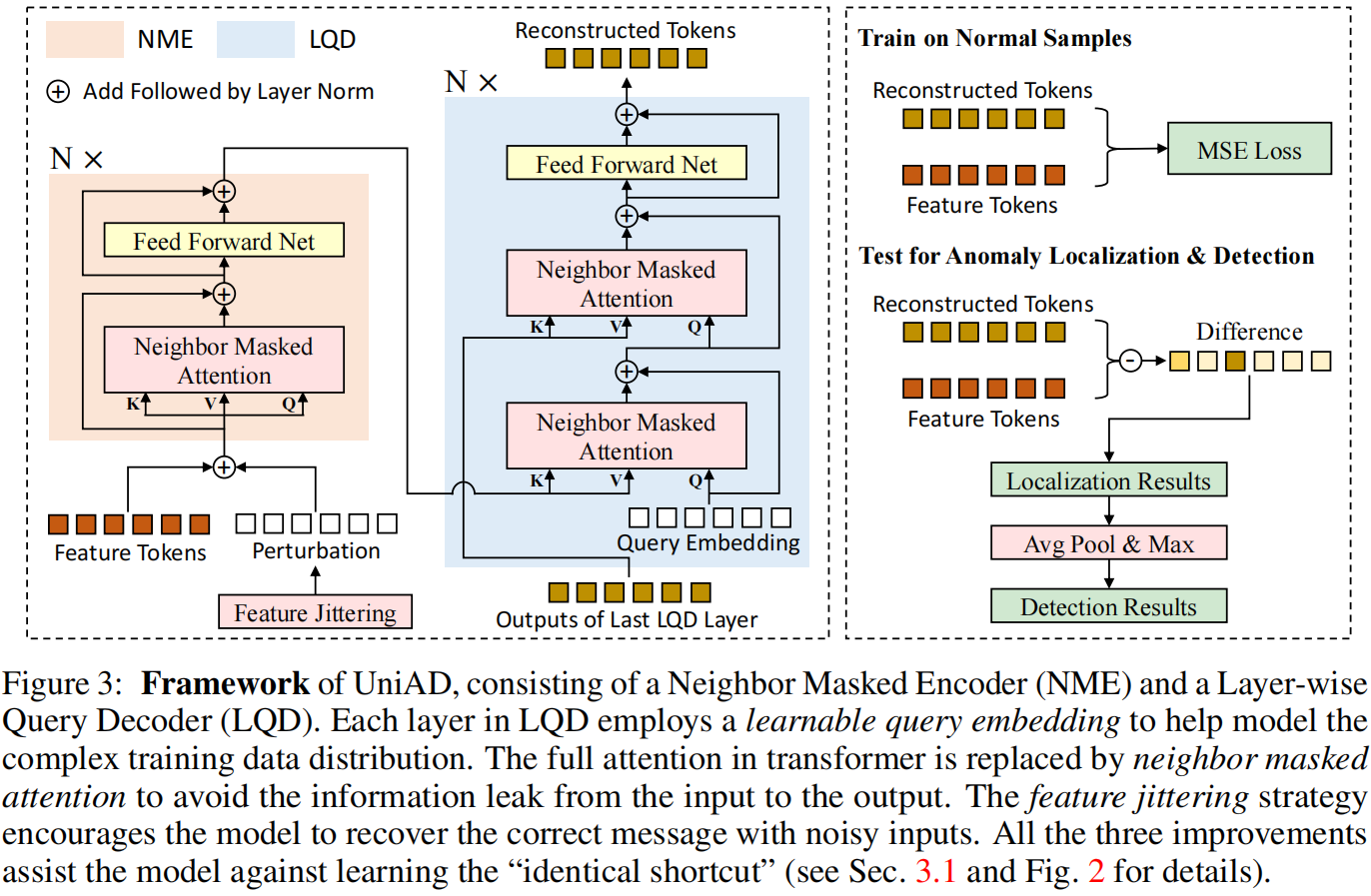
Neighbor masked attention
我们怀疑原始 Transformer 中的全注意力[42]导致了“相同捷径”的问题。在全注意力中,一个标记可以看到自身,因此通过简单复制就可以轻松重建。此外,考虑到特征tokens是由 CNN 主干提取的,相邻标记必然具有许多相似之处。因此,我们提出在计算注意力图时屏蔽相邻标记,称为Neighbor Masked Attention(NMA)。请注意,相邻区域在二维空间中被定义,如图5所示。
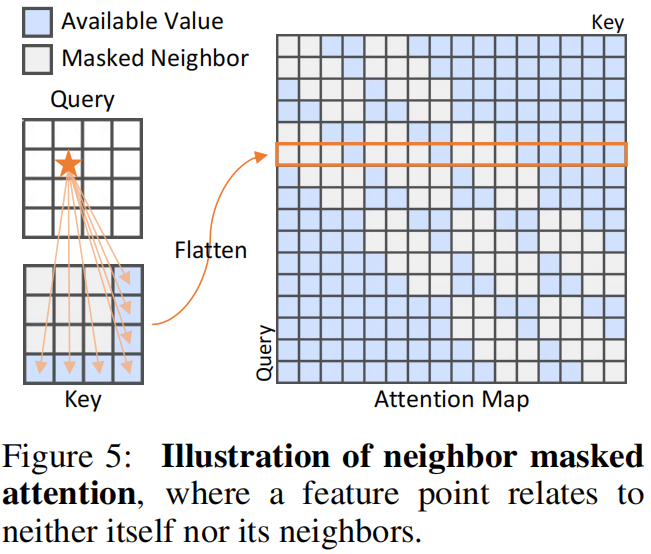
Neighbor masked encoder
编码器遵循原始Transformer中的标准架构。每个层包括一个注意力模块和一个前馈网络(FFN)。然而,全注意力被我们提出的NMA替换,以防止信息泄漏。
Layer-wise query decoder
在LQD的每一层中,一个可学习的查询嵌入首先与编码器嵌入进行融合,然后与前一层的输出进行整合(对于第一层进行自整合)。特征融合由NMA实现。遵循原始的Transformer,我们应用了一个两层的前馈网络(FFN)来处理这些融合的标记,并利用残差连接来促进训练。LQD的最终输出用作重建的特征。
Feature jittering.
受到去噪自编码器(DAE)\([3,43]\) 的启发,我们向特征标记添加扰动,引导模型通过去噪任务学习正常样本的知识。具体来说,对于一个特征标记 \(\boldsymbol{f}_{\text {tok }} \in \mathbb{R}^C\),我们从高斯分布中采样扰动 \(D\),
其中 \(\alpha\) 是抖动尺度,用于控制噪声程度。此外,采样的扰动以固定的抖动概率 \(p\) 添加到 \(f_{t o k}\) 中。
3.3 Implementation details
Feature extraction
我们采用在ImageNet [14] 上预训练的固定 EfficientNet-b4 [40] 作为特征提取器。从第一阶段到第四阶段的特征被选取出来。这里的阶段指的是拥有相同大小特征图的区块组合。然后这些特征被调整到相同的大小,并沿着通道维度连接起来形成一个特征图,\(\boldsymbol{f}_{\text {org }} \in \mathbb{R}^{C_{\text {org }} \times H \times W}\)。
Feature reconstruction.
特征图 \(\boldsymbol{f}*{\text {org }}\) 首先被分解成 \(H \times W\) 个特征标记,接着进行线性投影将 \(C*{\text {org }}\) 降维到一个更小的通道数 \(C\)。然后这些标记经过 NME 和 LQD 处理。可学习的位置嵌入 \([15,16]\) 被添加到注意力模块中以传递空间信息。随后,另一个线性投影被用于从 \(C\) 恢复到 \(C_{\text {org }}\)。经过重塑,最终得到重建的特征图 \(\boldsymbol{f}_{\text {rec }} \in \mathbb{R}^{C_{\text {org }} \times H \times W}\)。
Objective function.
目标函数。我们的模型使用均方误差(MSE)损失进行训练,即
异常定位推理。异常定位的结果是一个异常分数图,为每个像素分配一个异常分数。具体来说,异常分数图 \(s\) 计算为重建差异的L2范数,即
然后使用双线性插值将 \(s\) 上采样到图像尺寸以获得定位结果。
Inference for anomaly detection
异常检测旨在检测图像是否包含异常区域。我们将异常分数图 \(s\) 转换为图像的异常分数,通过取平均池化后的 \(s\) 的最大值来完成。
4 Experiment
4.1 Datasets and metrics
4.2 Anomaly detection on MVTec-AD
Baselines
US [6], PSVDD [48], PaDiM [11], CutPaste [25], MKD [37], and DRAEM [52]
Under the unified case, US, PSVDD, PaDiM, CutPaste, MKD, and DRAEM are run with the publicly available implementations
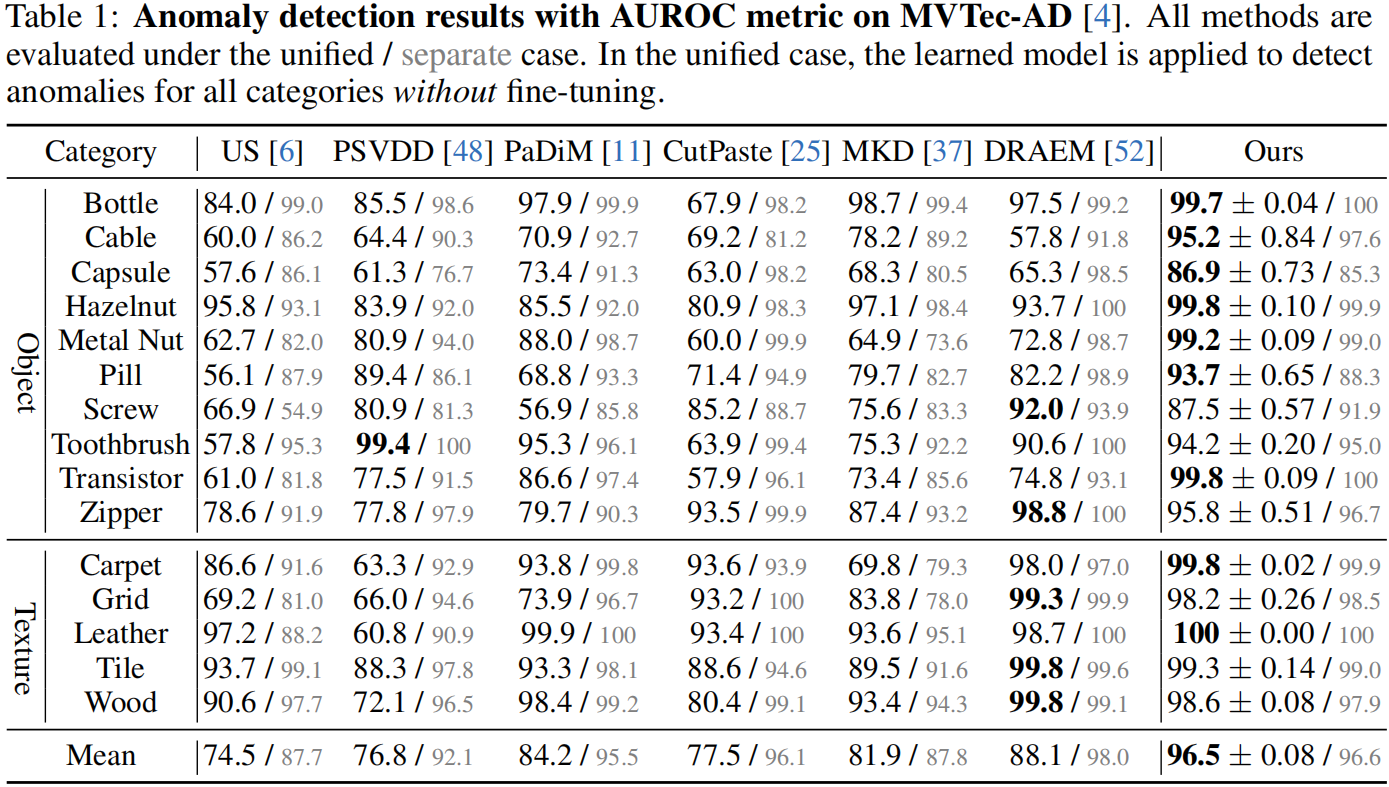
Quantitative results of anomaly detection on MVTec-AD
如表1所示。虽然所有基线方法在单独情况下都表现出色,但它们在统一情况下的表现急剧下降。先前的最优方法 DRAEM,一个基于重建训练的伪异常方法,遭受了近10%的性能下降。对于另一个强大的基线方法 CutPaste,一个伪异常方法,其性能下降高达18.6%。然而,我们的 UniAD 从单独情况(96.6%)到统一情况(96.5%)几乎没有性能下降。此外,我们以极大的优势击败了最佳竞争者 DRAEM(8.4%),显示出我们的优越性。
4.3 Anomaly localization on MVTec-AD
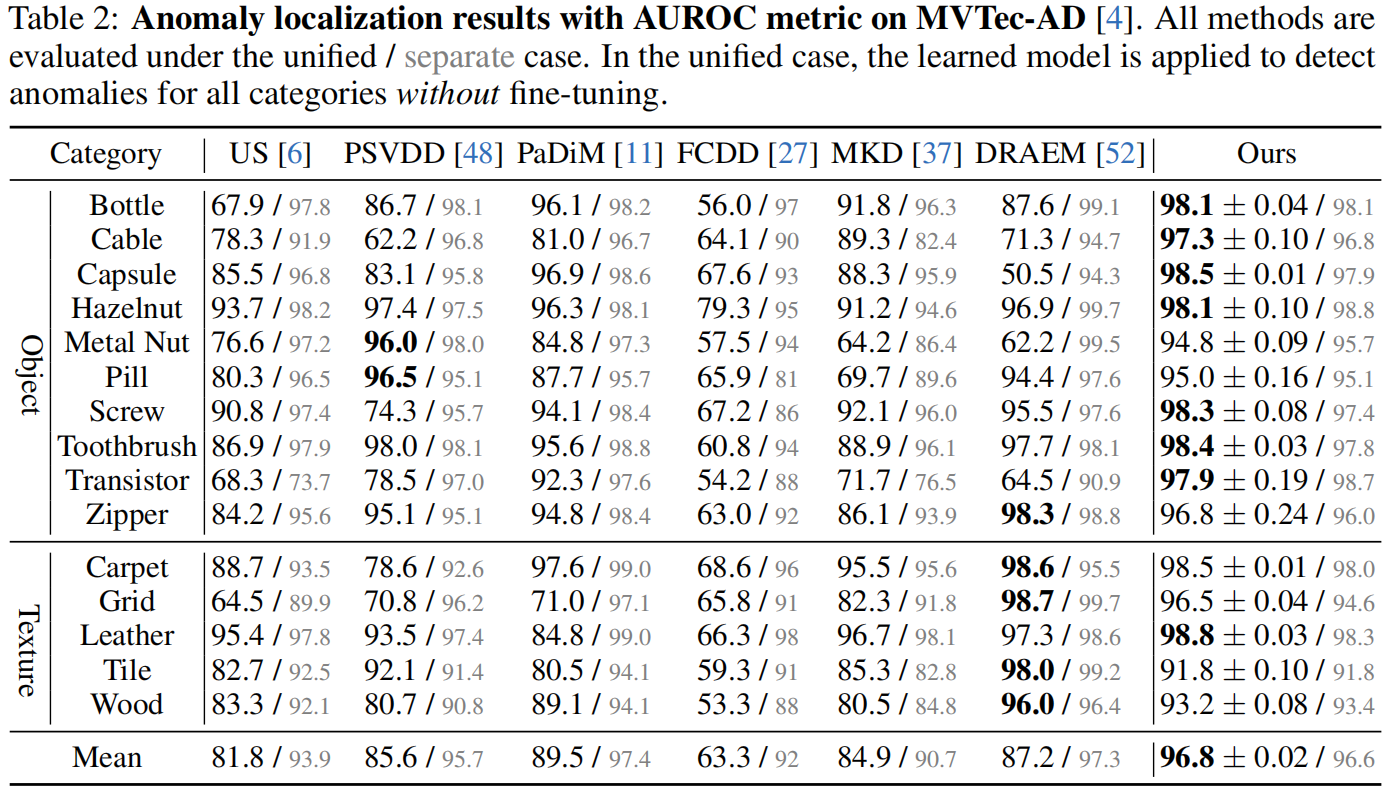
Quantitative results of anomaly localization on MVTec-AD
如表2所示。与第4.2节类似,从单独情况切换到统一情况,所有竞争方法的性能都显著下降。例如,重要的基于蒸馏的基线方法 US 的性能下降了12.1%。伪异常方法 FCDD 遭受了28.7%的显著下降,反映出伪异常不适用于统一情况。然而,我们的 UniAD 甚至在从单独情况(96.6%)到统一情况(96.8%)转变时稍微改善了一点,证明了我们的 UniAD 适用于统一情况。此外,我们显著超越了最强基线方法 PaDiM,超出了7.3%。这种显著改进反映了我们模型的有效性。
Qualitative results for anomaly localization on MVTec-AD
如图6所示。对于全局(图6a)和局部(图6b)结构异常,以及分散的纹理扰动(图6c)和多个纹理划痕(图6d),我们的方法能够成功地将异常重建为其对应的正常样本,然后通过重建差异精确地定位异常区域。附录中提供了更多的定性结果。

4.4 Anomaly detection on CIFAR-10
Setup
为了进一步验证我们的 UniAD 的有效性,我们将 CIFAR-10 [23] 扩展到统一情况,其中包括四种组合。对于每种组合,五个类别一起作为正常样本,而其他类别被视为异常。四种组合的类索引分别是 {01234}、{56789}、{02468}、{13579}。这里的 {01234} 意味着正常样本包括来自类别 0、1、2、3、4 的图像,其他组合类似。注意,类索引是通过对10个类别的类名进行排序得到的。
Baselines.
US [6], FCDD [27], FCDD+OE [27], PANDA [33], and MKD [37] serve as competitors. US, FCDD, FCDD+OE, PANDA, and MKD are run with the publicly available implementations.
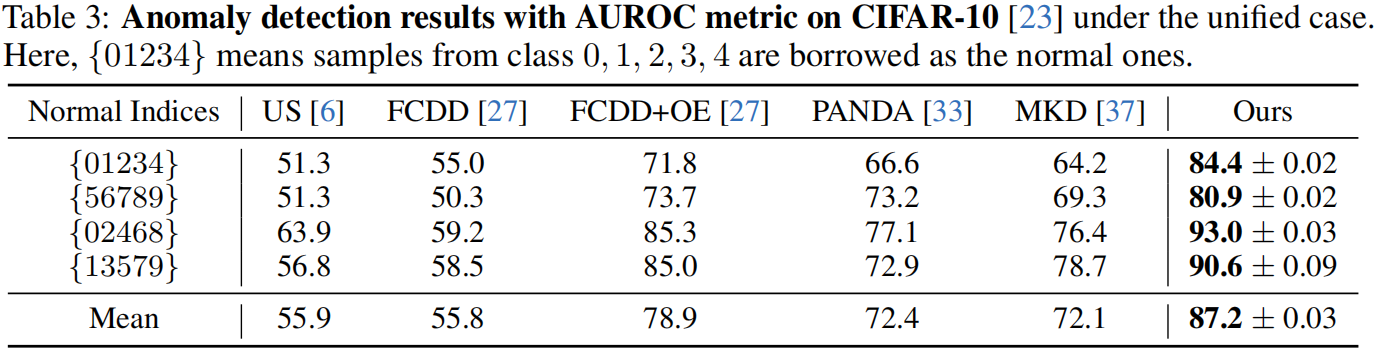
Quantitative results of anomaly detection on CIFAR-10
如表3所示,当五个类别一起作为正常样本时,两个最近的基线方法 US 和 FCDD 几乎失去了检测异常的能力。当利用从 CIFAR-100 [23] 中采样的 10000 张图像作为辅助异常曝光(OE)时,FCDD+OE 大幅提高了性能。即使在没有 OE 的情况下,我们仍然稳定地比 FCDD+OE 提高了 8.3%,表明我们的方法
4.5 Comparison with transformer-based competitors
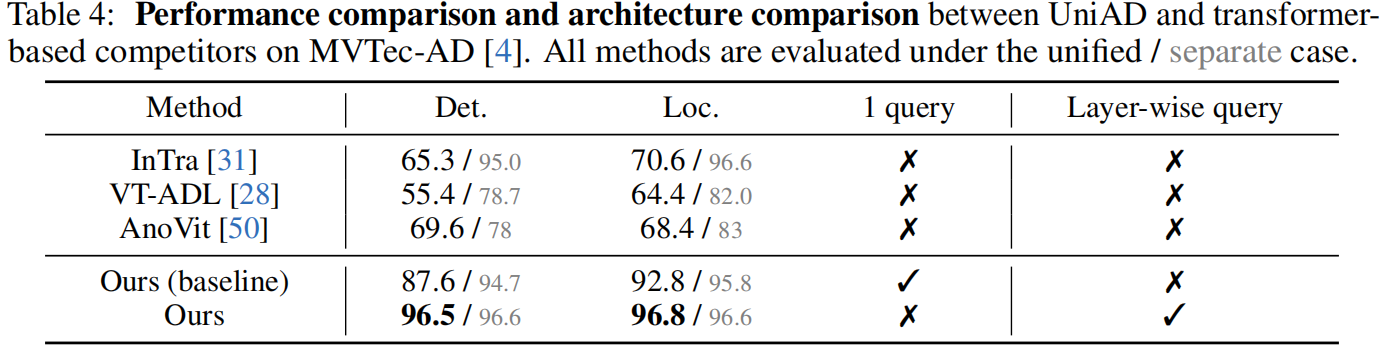
正如第2节所述,一些尝试 [31, 28, 50] 也尝试利用Transformer进行异常检测。在这里,我们将我们的UniAD与现有基于Transformer的竞争对手在MVTec-AD [4]上进行比较。回顾一下,我们选择Transformer作为重建模型,考虑到它在防止模型学习“相同快捷方式”方面的巨大潜力(参见第3.1节)。具体来说,我们发现learnable query embedding 对于避免这种快捷方式至关重要,但在现有基于Transformer的方法中很少被探索。如表4所示,在引入了仅一个查询嵌入后,我们的基线在统一设置下已经以相当大的优势超过了现有的替代方法。我们提出的三个组件进一步改进了我们的强基线。请注意,这三个组件都是为了避免模型直接输出输入而提出的。
4.6 Ablation studies
Layer-wise query
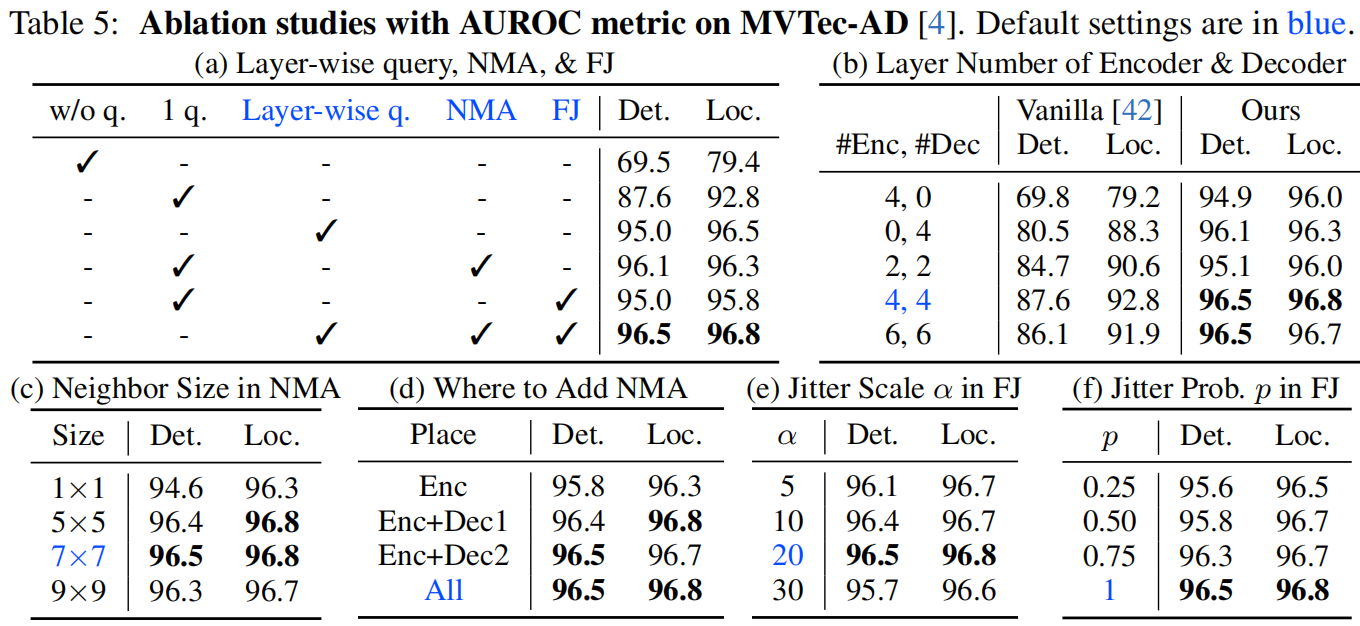
如表5a所示,验证了我们的断言:查询嵌入至关重要。
- 没有查询嵌入,意味着编码器嵌入直接输入解码器,性能最差。
- 仅在第一个解码器层添加一个查询嵌入(即普通Transformer [42]),在检测和定位方面性能分别大幅提升了18.1%和13.4%。
- 在每个解码器层中使用层级查询嵌入,图像级和像素级的AUROC分别进一步提高了7.4%和3.7%。
Layer number
我们进行了实验以研究层数的影响,如表5b所示。
- 无论采用哪种组合,我们的模型都远远优于普通Transformer,反映了我们设计的有效性。
- 最佳性能是在适度的层数下获得的:4Enc+4Dec。更大的层数,比如6Enc+6Dec,并没有带来更多的提升,这可能是因为更多的层更难训练。
Neighbor masked attention
- 表5a证明了NMA的有效性。在只有一个查询嵌入的情况下,添加NMA对检测提升了8.5%,对定位提升了3.5%。
- NMA的邻居大小选择见表5c。1×1的邻居大小效果最差,因为1×1太小以防止信息泄漏,因此可以通过复制邻居区域来完成恢复。更大的邻居大小(≥ 5×5)明显好得多,最佳选择是7×7。
- 表5d还研究了添加NMA的位置。仅在编码器(Enc)中添加NMA是不够的。当进一步在解码器的第一或第二个注意力层(Enc+Dec1,Enc+Dec2)或两者(All)中添加NMA时,性能稳定提升。这反映了解码器的完全注意力也会导致信息泄漏。
Feature jittering
- 表5a证实了FJ的有效性。在一个查询嵌入作为基线的情况下,引入FJ可以分别使检测和定位提高7.4%和3.0%。
- 根据表5e,选择抖动尺度α为20。更大的α(例如30)会对特征干扰太大,降低结果。
- 在表5f中,研究了抖动概率p。实质上,带有特征抖动的任务是一个去噪任务,而不带有特征抖动的任务是一个重建任务。结果表明,完全去噪任务(即p = 1)是最佳选择。
- multi-class detection unified anomaly 论文multi-class detection unified anomaly distribution detection anomaly论文 detection机器anomaly mean-shifted contrastive detection anomaly isolation detection anomaly forest discrimination distribution detection anomaly detection learning anomaly survey detection real-time holmes论文 multi-class anomaly