SHM can provide a large amount of data that can reveal the variation in the structure condition
什么是压缩传感,数据重构,研究背景与意义,怎么用
基于模型的方法不可避免的缺点是模型的不确定性,因为很难创建能够模拟真实物理情况的可靠的结构模型。为了克服基于模型的方法的缺点,许多研究人员提出了基于数据驱动的损伤检测方法,如直接基于结构振动特征变化的异常检测,时间序列方法,如自回归(AR)模型,自回归外部输入(ARX)模型,和自回归滑动平均(ARMA)模型。
传统的主成分分析方法在实际应用中存在一定的局限性。首先,监测数据中涉及的相当大的噪声和残差分量中包含的显著不确定性通常被忽略。因此,由于不确定程度在确定阈值中起着重要作用,因此影响了孤立点检测的准确性。其次,特征值分析需要一个完整的数据矩阵,这阻碍了传统的主成分分析处理数据缺失的能力。
PPCA有两个优点:(1)可以用不完整的测量数据构造PC矩阵,并且可以恢复丢失的数据;(2)可以估计噪声水平,以便更合理地确定阈值。
一,基本原理(主轴?)
1.PCA
主轴Pj由样本协方差矩阵S的第一个q个主导特征向量(即具有第一个q个最大关联特征值λj的特征向量)给出?
样本协方差矩阵
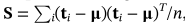

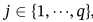
其中μ是数据样本平均值
观测数据ti在主轴上的投影可以得到如下所示
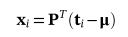 。
。
Xi(主轴上的投影)的变量是不相关的,其协方差阵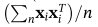 与特征值λj对角
与特征值λj对角
几何上,向量xi也称为主成分分析值,提供了由主轴组成的q维非物理子空间中观测数据的新表示。由于投影到主轴上的方差最大,因此它具有最高的潜力来展示观测数据的特征。
Xi的分数也可以投影回原来的d维空间。然后,可以得到ti的重构^ti为
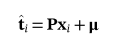 (3)
(3)
对于具有d0维观测部分和dm维缺失部分的数据集,(d=d0+dm),PC矩阵P可分离为P(O)和P(M)。那么具有不完全测量的新数据的得分xi可以近似为
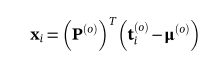
其中μ(O)是完整测量数据集中观察部分的数据平均值。
丢失的数据可以恢复为:
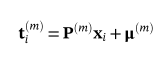 其中μ(M)是对应于缺失部分的数据平均值。
其中μ(M)是对应于缺失部分的数据平均值。
2.PPCA
D维观测向量ti,i{1,n}与对应的q维潜变量xi之间的关系可用线性形式表示为

εi被定义为残差;W是需要估计的;假设潜在变量xi是独立的且具有单位方差的高斯xi~N(0,i),其中i表示q维恒等矩阵。剩余εi也被假定为独立且具有各向同性方差的高斯εi~N(0,σ**2i)
在给定的潜变量xi下,观测ti的条件概率分布为:
 (7)
(7)
在潜变量为先验高斯分布的情况下,观测数据ti的边际分布(the marginal distribution ?)也是高斯分布:

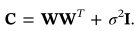
Xi在给定观测值ti后的后验分布可以由贝叶斯定理得到,该定理也是高斯分布
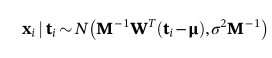 (9)
(9)

然后将观测数据的xi投影到q主轴上,即可得到
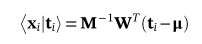 (10)
(10)
其中<>是期望运算符。公式10中的xi也被称为PPCAscore。在这个具有σ**2>0的概率模型中,由于xi的高斯边缘分布,投影向原点倾斜。因此,公式3中的重建不是最优的。从PPCAscore对观测数据的最优重建可以获得
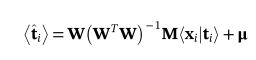 (11)
(11)
二,具有缺失数据的PPCA的EM算法
虽然PPCA模型的参数W和σ2没有闭合形式的解析解,但可以通过极大似然(ML)估计来估计它们。具体地说,可以通过最大化观测向量的对数似然函数来估计这些模型参数。
对于PPCA,由于潜在向量和缺失数据的存在,最大似然估计的结果是隐含的。因此,使用期望最大化(EM)算法。E-M方法是由E步(期望步)和M步(最大化步)组成的迭代算法。
1,在E步中,基于当前参数对缺失数据和潜在变量进行期望,并利用期望结果得到新的对数似然函数。在M步中,通过最大化新的对数似然函数来更新参数。
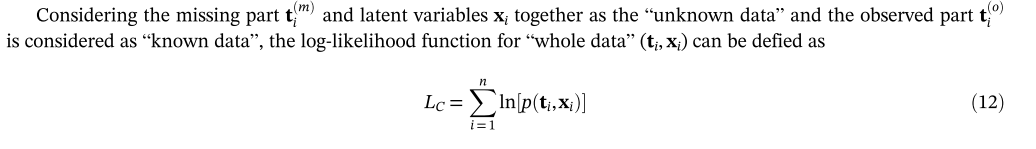
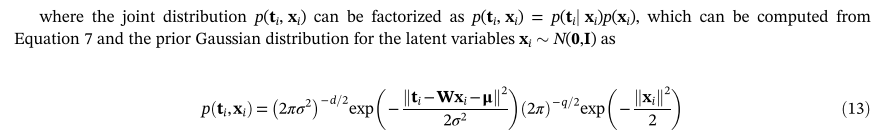
在E-Step中,根据观测部分和当前模型参数估计缺失部分和潜在变量。首先,使用在最后迭代步骤中估计的模型参数Wold和σ**2old来恢复丢失的数据。Wold可以按行分为两部分:与观测到的和缺失的部分向量相对应的W(o)old和W(m)old。可以通过公式(11)中的数据重构来更新缺失部分的期望
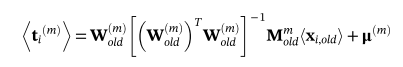 (14)
(14)
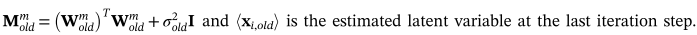
然后,可以通过公式10和新恢复的数据来估计新的潜变量
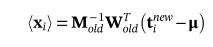 (15)
(15)
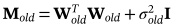 ,tinew是新恢复的观测向量(怎么恢复过来的??),包括由公式14估计的缺失部分<ti(M)>。
,tinew是新恢复的观测向量(怎么恢复过来的??),包括由公式14估计的缺失部分<ti(M)>。
通过使用公式14和15中所示的估计的缺失数据和潜在变量,可以如下获得新的对数似然函数:
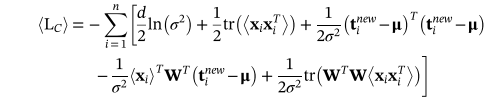
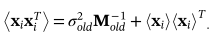
2,在M步骤中,最大化<LC>以获得模型参数W和σ**2的新估计为

其中n是观测次数;d是观测向量的维度。E步和M步按顺序迭代,直到结果收敛。
步骤:
1.初始化参数W和σ2。在本研究中,初始W由包含从标准正态分布中提取的伪随机值的d×q矩阵获得。初始σ**2是基于初始W的残差的方差。
2.E步骤:通过公式14使用估计的模型参数和最后迭代步骤中的潜在变量恢复观测<ti(m)>的缺失部分;
3.E步骤:通过公式15估计潜在变量<Xi>。
4.M步骤:通过公式17和18获得对模型参数W和σ2的新估计,从而使公式16中的<Lc>最大化。
5.重复步骤2-4,直到估计收敛。在本研究中,假设当<Lc>与上一迭代步相比变化小于0.01%时,即可实现收敛。
三,通过PPCA可以得到Q统计量和T2统计量的概率分布,从而可以通过考虑噪声水平来更合理地确定这两种统计量的阈值
1,PCA模型的T2统计量可以写为

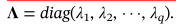
根据公式10,<xi>也服从高斯分布,
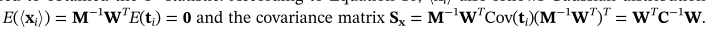
然后,PPCA模型的T2统计量可以写为29
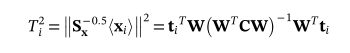
阈值:
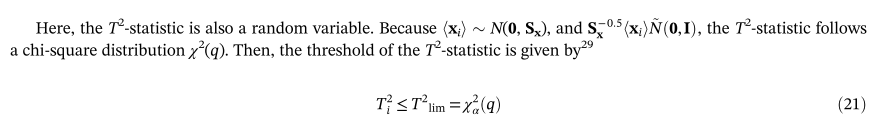
其中,α是significance level,Q是选定的PC数量。对于本例中的应力数据,得分向量(投影)实际上反映了环境和操作负荷的变化。因此,较大的T2统计量意味着与基本模型的平均值相比,环境和运行负荷的变化较大。
2,Q-残差变量统计量它是对ti的剩余εi的量度。
对于PCA,Q统计量定义为
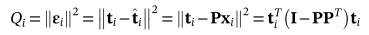
对于PPCA,Q统计量定义为
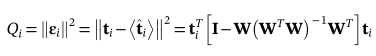
阈值:

因此,Q统计量揭示了构造异常的严重性。此外,εi中残差最大的传感器是受结构异常影响最大的传感器。因此,残差εI可用于异常定位。
异常局部化的阈值为:
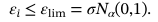
3,基于结构健康监测数据的基于概率主成分分析(PPCA)的异常检测流程图。EM,期望最大化

四,总结
在数据完整的情况下,PPCA和基于Q统计量的PPCA方法能够消除环境的影响,成功地检测出结构的损伤的原理总结
1.在各种数据缺失情况下,PPCA模型均能较准确地估计出主轴。此外,还可以正确估计相关参数的概率分布,如Q和T2统计量,从而可以合理地确定异常检测的阈值。PPCA对模拟和实际SHM数据缺失数据恢复的相对误差(RRMSE)在3.0%-4.8%之间,而PCA对缺失数据的恢复在4.5%-8.0%之间。基于PPCA模型得到的PC,可以在残差和Q统计量中消除温度和观众效应,从而成功地检测和定位真实的结构损伤。PPCA算法的误警率和漏损率远小于PCA算法
2.仿真分析结果表明,在均方根噪声水平为20%的情况下,利用有限相邻构件的静应力测量结果,PPCA模型能够成功地检测出较少冗余度构件的面积减小20%等小损伤和高冗余度构件面积减小40%的大损伤。然而,由于高冗余构件损伤对结构系统的影响有限,只有在较小的噪声条件下(RMS为5%-10%),才能合理地检测出高冗余构件面积减少20%的损伤。对在多个应力测量中引入异常的实际SHM数据进行了日变化一个标准差水平的人工数据偏移,结果表明,PPCA的损伤缺失率在16%~32%之间,而PCA的损伤缺失率在69%~86%之间。
3.PPCA重建的应力数据与实测值之间的残差可以成功地用于异常定位。仿真和实际监测数据的分析表明,PPCA模型对异常的定位效果更好,定位成功率在92%-98%之间,而PCA模型的定位成功率在40%-93%之间,数据缺失情况下的定位成功率为20%。
- analysis-based Probabilistic 概率 structures principalanalysis-based probabilistic概率structures probabilistic概率progressive transform analysis-based principal user示例developer principal probabilistic principal主体factory service 算法principal component analysis probabilistic perspective geometric detecting probabilistic efficient framework embraces