SR Algorithm Analysis(1)——ZSSR
CVPR 2017
《“Zero-Shot” Super-Resolution using Deep Internal Learning》

Innovations:
- 第一个基于CNN的zero shot SR算法。基于照片内部的循环信息。
- 能够处理不同种类的照片,不需要完美条件的照片。根据“小信息片段(例如小图像块)在单个图像的不同尺度上的循环被证明是自然图像的一个非常强大的特性[5, 24]”的假设。
- 无需训练,基于内部的自我监督,只需要少量计算资源。
- 适用于任何分辨率。
Background:
The Power of Internal Image Statistics
方法的基础是自然图像具有强烈的内部数据重复性:
小图像块(例如5×5、7×7)在单个图像内部多次重复出现,无论是在相同尺度内,还是在不同图像尺度之间.
举例:
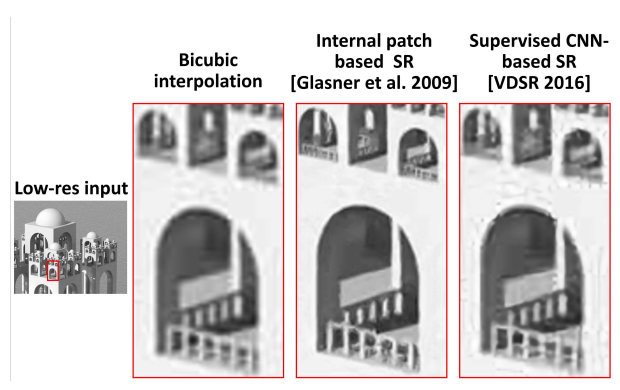
论文中的模型能够恢复小阳台上的小扶手,因为有关它们存在的证据(分形几何的重复模式)可以在此图像的其他位置找到,例如在一个较大的阳台上。有关这些小扶手存在的唯一证据存在于这个图像的内部,位于不同的位置和不同的尺度上。无论外部示例数据库有多大,都无法找到这些素材!
这种模式在不断增加的不确定性和图像退化条件下表现得尤为强烈 ( [24, 17] )
why?
论文中的模型训练一个CNN来从其较低分辨率版本中恢复LR(Low Resolution)测试图像中的扶手,即使在其感受野内没有其他扶手出现。然后,当这个CNN应用于测试图像本身时,它可以通过使用相同的Image-Specific method在其他位置恢复新的扶手。
受监督的卷积神经网络(Supervised CNNs)通过训练大规模和多样化的外部LR-HR图像示例集来学习,必须在其学习权重中捕获所有可能的LR-HR关系的大量多样性。因此,这些网络往往非常深,并且非常复杂。相比之下,单个图像内部的LR-HR关系的多样性要小得多,因此可以通过一个更小、更简单的图像特定网络来编码。
这部分实际上并不准确,参见汇报过的one-shot diffusion。
Methods:
Image-Specific CNN SP
将Image-Specific CNN(构建了一个专门用于解决该特定图像的SR任务的Image-Specific CNN)训练成能够从其较低分辨率版本\(I ↓ s\)(下图(b)的顶部部分)中重建测试图像I的模型。
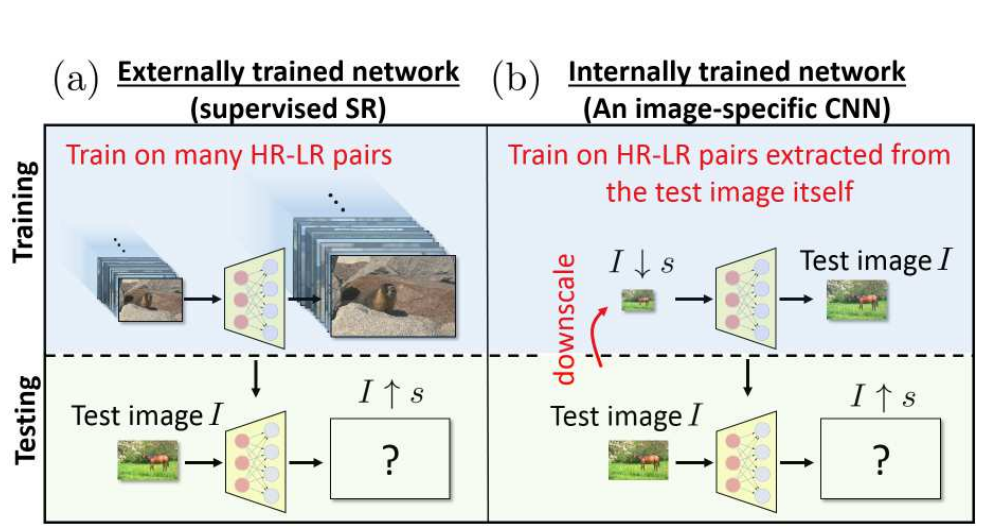
然后,我们将经过训练的CNN应用于测试图像I,现在将I用作网络的\(LR\)输入,以生成所需的HR输出\(I ↑ s\)(上图(b)的底部部分。因为网络是完全卷积的,所以可以适应不同大小的图像。
How to build the I ↓ s?
上文阐述了网络训练是由很多\(I ↓ s\)来构成,现在来说明一下如何构成\(I ↓ s\),所有的\(I ↓ s\)都是将LR图像I进行降采样来获得的,以生成其自身的较低分辨率版本\(I ↓ s\)。
\(I ↓ s\)由一系列图像构成,通过将测试图像I降采样为其自身的许多较小版本\((I = I_0, I_1, I_2, ..., I_n)\)来完成的。这些较小版本充当了HR(High Resolution)监督的角色,被称为“HR父代”(HR fathers),然后每个HR父代根据所需的SR比例因子s进行降采样,生成“LR子代”(LR sons)。
Augmentation
首先,基于传统图形处理的常规方法。该方法涉及进行四次旋转(0°、90°、180°、270°),并在垂直和水平方向上进行镜像反射。这个过程会使图像特定的训练示例数量增加8倍。
其次,为增强模型的稳健性,特别是增强对于大尺度超分辨率(SR)因子\(s'\)的效果(从非常小的低分辨率(LR)图像开始)他们采用了一个包含不同尺度因子\((s1、s2、...、sm = s)\)的出队机制,按降序排列出队。逐步提高模型的效果。
在每个中间尺度\(s_i\)处,他们将生成的SR图像\(HR_i\)及其缩小/旋转版本逐渐添加到他们不断扩展的训练集中,作为新的HR示例。他们还通过下一个渐进尺度因子\(s_{i+1}\)将这些图像,包括以前较小的HR示例,下采样,以生成新的LR-HR训练示例对。这个过程重复进行,直到达到所需的完整分辨率增加\(s\)。
以下内容展示了,整个训练和推理流程:
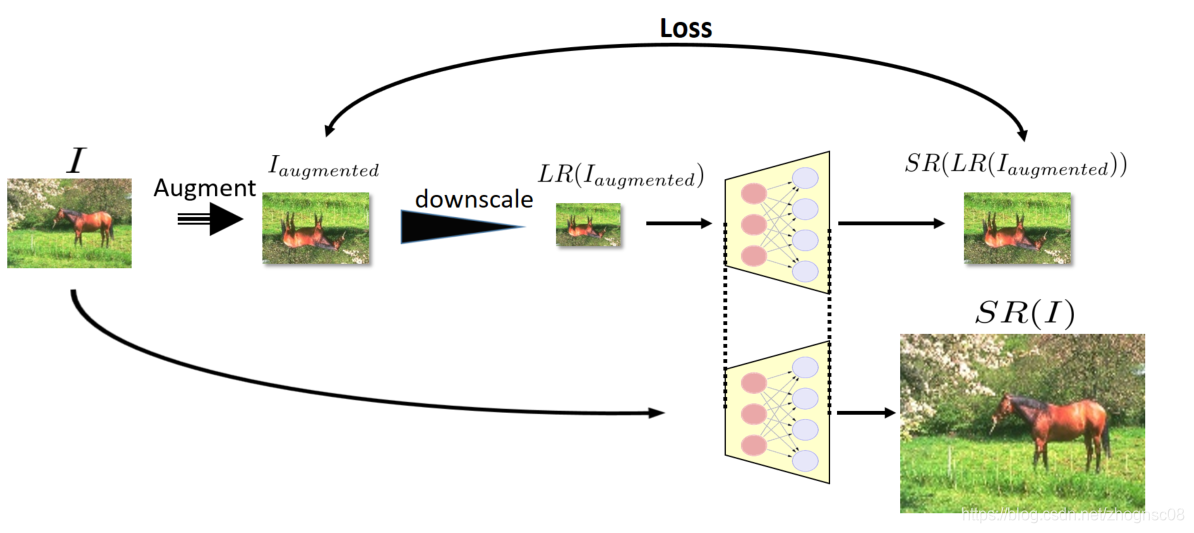
Architecture & Optimization
全卷积网络,具有8个隐藏层,每个层有64个通道。我们在每个层上使用ReLU激活函数。网络输入被插值到输出尺寸。与以前的基于CNN的SR方法一样,我们只学习插值LR图像与其HR父代之间的残差。
使用L1损失和ADAM优化器。从学习率0.001开始。定期对重建误差进行线性拟合,如果标准差比线性拟合的斜率大,我们将学习率除以10。最终停止在达到10^-6的学习率。

如何解决不同分辨率的造成的影响?
每次迭代中都从随机选择的LR-HR对中采取一个固定大小的随机裁剪。
这个裁剪通常为128×128(除非被采样的图像对更小)。在每个训练迭代中,采样LR-HR示例对的概率被设置为非均匀,并且与HR父代的大小成比例。
尺寸比率(HR父代与测试图像I之间的比率)越接近1,被采样的概率越高。The closer the size-ratio (between the HR-father and the test image I) is to 1, the higher its probability to be sampled. This reflects the higher reliability of non-synthesized HR examples over synthesize ones
最后通过 geometric self-ensemble proposed 和 median image 来构成对应的图像。
简单描述就是首先得到8中图像类型的输出结果,最后进行反变换以后,将对应像素值的内容取得中值,合成最终的图像。
结果的优势在哪里?
当LR图像从其HR图像中的获取参数固定为所有图像时(例如,相同的降采样核,高质量成像条件),当前的监督式SR方法可以取得令人难以置信的性能。
然而,在实际应用中,由于摄像机/传感器不同(例如,不同类型的镜头和点扫描函数)以及个别成像条件(例如,拍摄照片时微小的非自愿相机晃动,能见度差等),获取过程往往会从图像到图像不同。这导致了不同的降采样核,不同的噪声特性,各种压缩伪影等。
而且,单个监督式CNN不太可能在所有可能的退化/设置类型上表现良好。要获得良好的性能,需要许多不同的专门SR网络
这就是Image-Specific CNN的优势所在。我们的网络可以在测试时根据手头的测试图像的特定退化/设置进行适应调整。
- (i) 所需的降采样核(如果没有提供核,双三次插值核将作为默认值)。
- (ii) 所需的SR比例因子s。
- (iii) 所需的逐渐增加尺度的数量(速度和质量之间的权衡-默认值为6)。
- (iv) 是否在LR和HR图像之间执行反投影(默认为“是”)。
- (v) 是否在从测试图像中提取的每个LR-HR示例对中的LR sons中添加“噪声”(默认为“否”)。
特殊的,向LR_sons中添加一些合成噪声(但不添加到它们的HR fathers中)可以教会网络忽略不相关的跨尺度信息(噪声),同时学习增加相关信息的分辨率(信号细节)。
同时发现,下采样过程中添加一点高斯噪声(均值为零,标准差约为5个灰度级),可以改善各种退化(高斯噪声、斑点噪声、JPEG伪影等)的性能。
Specific 的非理想降采样模拟
对于质量较低的LR图像以及各种不同类型的退化,Specific CNN的SR结果要比SotA EDSR+ [13]显著提高。

当降采样核已知时(例如,已知PSF的传感器),可以将其提供给网络,进行特定的下采样运算。
非理想的降采样核(偏离双三次插值核)
非理想的降采样核数据构建:这个实验的目的是测试更现实的模糊核,并能够对结果进行数值评估。为此,使用了BSD100 创建了一个新的数据集,通过使用随机(但相对合理大小的)高斯核对HR图像进行降采样。对于每个图像,其降采样核的协方差矩阵Σ被选择为具有随机角度θ和每个轴上的随机长度λ1、λ2
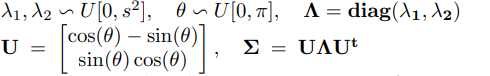
因此,每个LR图像都是由不同的随机核进行子采样的,与当时的SOTA方法相比较:

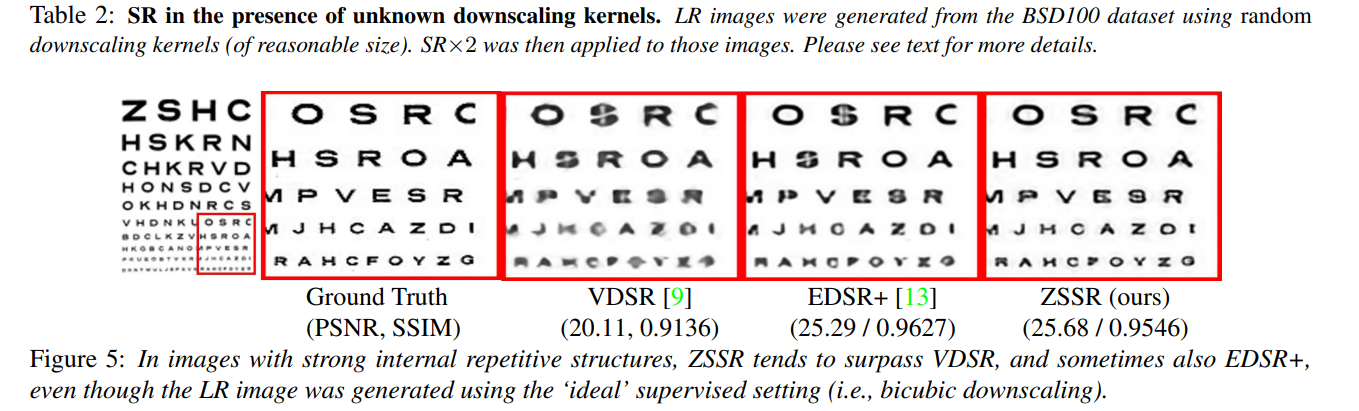
未知降采样核的更现实的情况
当降采样核未知时(通常是这种情况),可以直接从测试图像本身计算出粗略的核估计(例如,使用[15]的方法)。这样的粗略核估计足以在非理想的核上获得比EDSR+高1dB的改进。
通过寻找最大化LR测试图像中不同尺度下的补丁相似性的非参数化降采样核来估计未知的SR核。
通过在LR测试图像上查找不同尺度下的图像补丁(小图像块)之间的相似性,来创建一个非参数化的降采样核。这个非参数化的核是一种不依赖于固定参数或模型的核,而是根据LR图像上的实际信息来动态计算的。通过最大化不同尺度下图像补丁的相似性,他们能够估计出这个核,以便将LR图像升采样到更高的分辨率
和SRGAN的结果对比
