3.0.0主要的新特性:
- 在TPC-DS基准测试中,通过启用自适应查询执行、动态分区裁剪等其他优化措施,相比于Spark 2.4,性能提升了2倍
- 兼容ANSI SQL
- 对pandas API的重大改进,包括python类型hints及其他的pandas UDFs
- 简化了Pyspark异常,更好的处理Python error
- structured streaming的新UI
- 在调用R语言的UDF方面,速度提升了40倍
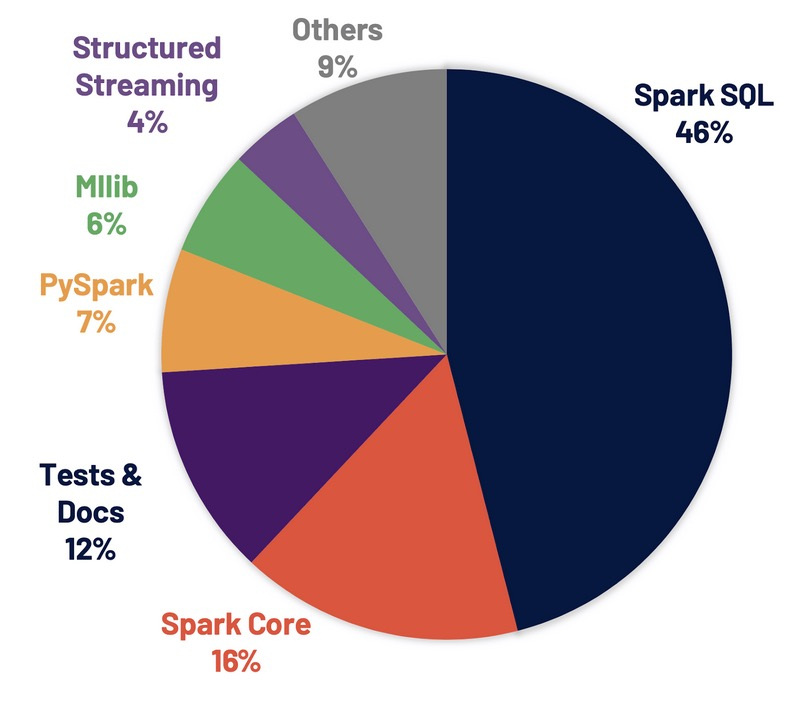
- 超过3400个Jira问题被解决,这些问题在Spark各个核心组件中分布情况如下图:
改进的Spark SQL引擎
Spark SQL是支持大多数Spark应用的引擎。例如,在Databricks,超过 90%的Spark API调用使用了DataFrame、Dataset和SQL API及通过SQL优化器优化的其他lib包。这意味着即使是Python和Scala开发人员也通过Spark SQL引擎处理他们的大部分工作。
自适应查询执行
即使由于缺乏或者不准确的数据统计信息和对成本的错误估算导致生成的初始计划不理想,但是自适应查询执行(Adaptive Query Execution)通过在运行时对查询执行计划进行优化,允许Spark Planner在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化,从而提升性能。
由于Spark数据存储和计算是分离的,因此无法预测数据的到达。基于这些原因,对于Spark来说,在运行时自适应显得尤为重要。AQE目前提供了三个主要的自适应优化:
-
动态合并shuffle partitions
可以简化甚至避免调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区。 -
动态调整join策略
在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行次优计划的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能 -
动态优化倾斜的join(skew joins)
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。
动态分区裁剪
当优化器在编译时无法识别可跳过的分区时,可以使用"动态分区裁剪",即基于运行时推断的信息来进一步进行分区裁剪。这在星型模型中很常见,星型模型是由一个或多个并且引用了任意数量的维度表的事实表组成。在这种连接操作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。在一个TPC-DS基准测试中,102个查询中有60个查询获得2到18倍的速度提升。
ANSI SQL兼容性
对于将工作负载从其他SQL引擎迁移到Spark SQL来说至关重要。
为了提升兼容性,该版本采用Proleptic Gregorian日历,用户可以禁止使用ANSI SQL的保留关键字作为标识符。此外,在数字类型的操作中,引入运行时溢出检查,并在将数据插入具有预定义schema的表时引入了编译时类型强制检查,这些新的校验机制提高了数据的质量。