来自微软(*^____^*)
论文地址:[2107.00641] Focal Self-attention for Local-Global Interactions in Vision Transformers (arxiv.org)
一、写在前面
还是ViT的历史遗留问题:ViT通过自注意力机制捕获长短视觉依赖在一系列视觉任务上都取得了较好的效果。但是他也带来了一些列挑战,由于二次计算开销,对于高分辨率的视觉任务,计算负担巨大。最近的许多工作都试图通过应用粗粒度全局关注(PVT、CVT)或细粒度局部关注(Swin)来降低计算和内存成本并提高性能。然而,这两种方法都削弱了多层变压器原有自关注机制的建模能力,从而导致次优解。为了解决二次计算的巨大开销同时保留原有性能,作者采用一种新的机制 Focal Self-Attention(FSA),以细粒度的方式关注离自己近的token,以粗粒度的方式关注离自己远的token,以此来更有效的捕获short-range和long-range的关系。
二、Motivation
图一左图:在DeiT-Tiny模型的第一层中,给定查询补丁(蓝色)的三个头部注意图的可视化。右图:焦点自我注意机制的图解描述。使用三个粒度级别组成蓝色查询的注意区域。
通过完全自注意的可视化,我们确实观察到它学会了同时关注局部环境(如cnn)和全局上下文(见图1左)。然而,当涉及高分辨率图像进行密集预测(如对象检测或分割)时,由于特征图中网格数量的二次计算成本,全局和细粒度的自注意变得非常重要。最近的研究要么利用粗粒度的全局自关注,要么利用细粒度的局部自关注来减少计算负担。然而,这两种方法都削弱了原始的完全自我注意的能力,即同时模拟短期和长期视觉依赖的能力,如图1左侧所示。
本文,作者提出了一种全新的焦点自注意力机制,考虑到距离较近的区域之间的视觉依赖关系通常比距离较远的区域更强,我们只在局部区域执行细粒度的自我注意,而全局执行粗粒度注意。如图1右侧所示,特征映射中的查询令牌以最细的粒度参与其最近的环境,就像它自己一样。然而,当它进入更远的区域时,它会关注汇总的标记以捕获粗粒度的视觉依赖。因此,它可以有效地覆盖整个高分辨率特征图,而在自注意计算中引入的令牌数量比完全自注意机制少得多。因此,它具有有效捕获短期和长期视觉依赖的能力。我们称这种新机制为焦点自我关注,因为每个令牌都以焦点的方式关注其他令牌。基于所提出的焦点自注意,我们开发了一系列focal Transformer模型:1)利用多尺度架构来保持高分辨率图像的合理计算成本;2)将特征映射划分为多个窗口,其中令牌共享相同的环境,而不是对每个令牌执行焦点自注意。

三、Contribution
1.提出了一种焦点自注意力机制 Focal-Self-Attention(FSA)
2.基于焦点自注意力机制,提出了一种 Focal Transformer和一系列变体
四、Method
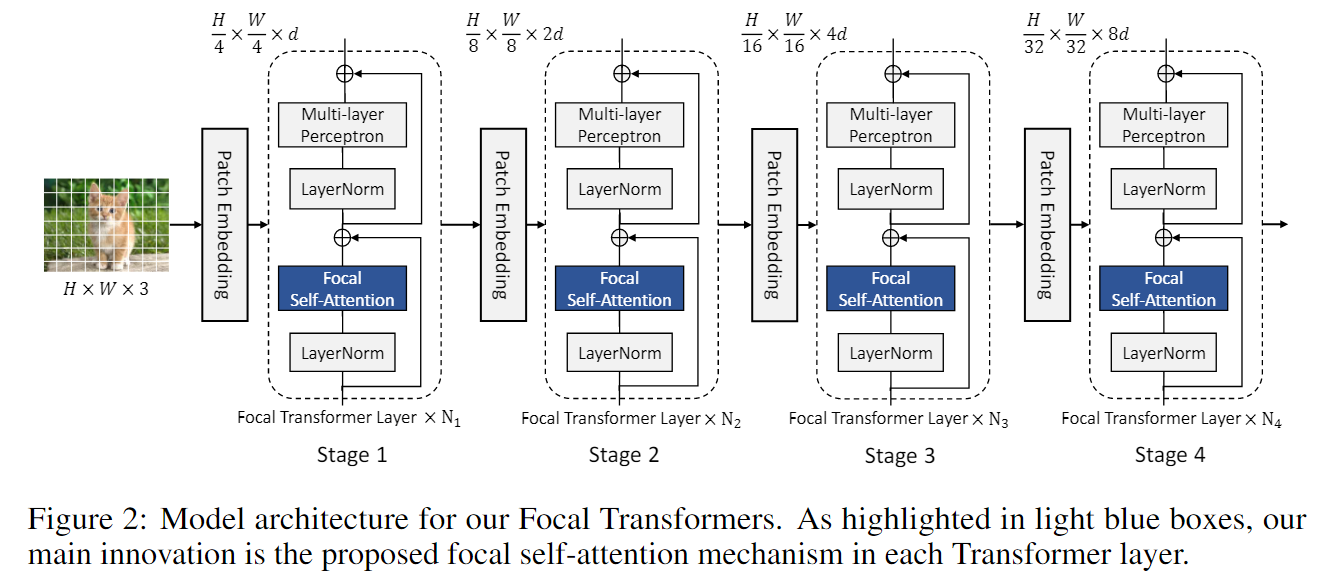
4.1 Model architecture
为了适应高分辨率的视觉任务,Focal Transformer采用了和PVT一致的层级结构。
首先,首先将图像 I 划分为大小为 4×4 的patch,图像大小变为H/4×W/4×3;然后,进入 Patch Embedding 层,Patch Embedding层为卷积核和步长都为4的卷积;再进入N 个 Focal Transformer 层,在每个stage中,特征的大小减半,通道维度变为原来的两倍。对于不同任务在最后阶段有所不同,对于图像分类,我们取最后阶段输出的平均值,并将其发送到分类层;对于目标检测,根据作者使用的特定检测方法,将最后3个或全部4个阶段的特征映射送到检测头。
 2.2 Focal self-attention
2.2 Focal self-attention
FSA对靠近当前token的信息进行更加细粒度的关注,对远离当前token的信息进行粗粒度的关注。在论文中,粗粒度的关注指的是将多个token的信息进行聚合(也就是下面讲到的sub-window pooling),因此聚合的token越多,那么关注也就越粗粒度,在相同的代价下,FSA的感受野也就越大。下图展示了对这attended token数量的增加,SA和FSA感受野的变化:
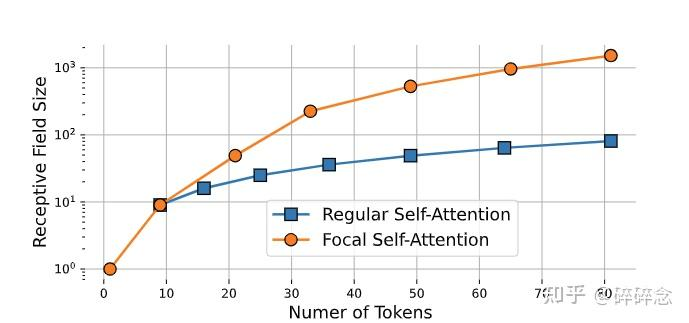
焦点机制能够以更少的时间和内存成本实现远程自我关注,因为它关注的汇总的 token 数量要少得多;然而,在实践中,为每个查询位置提取周围的 token 会受到高时间和内存成本的影响,因为需要为所有可以访问它的查询复制每个令牌;在窗口级别执行焦点自注意力成为一种解决方案。
假设有一个大小为 20 × 20 的输入特征图;
首先,将图片划分为大小为 4 × 4 的 5 × 5 个窗口,以中间的 4 × 4 蓝色窗口作为查询,以多粒度提取其周围的标记级别,作为它的键和值;
对于第一级,我们以最细的粒度提取最接近蓝色窗口的 8 × 8 标记;
然后在第二级,我们扩展注意力区域并池化周围的 2×2 子窗口,从而产生 6×6 池化的令牌;
在第三级,我们参与覆盖整个特征图和池 4 × 4 子窗口的更大区域。
最后,将这三个级别的令牌连接起来计算蓝色窗口中 4 × 4 = 16 个token(查询)的键和值

4.2.1 Window-wise attention
Focal Self-Attention的结构如上图所示,首先明确三个概念:
Focal levels :可以表示FSA中对特征关注的细粒度程度。level L的下标越小,对特征关注也就越精细。
Focal window size :作者将token划分成了多个sub-window,focal window size指的是每个sub-window的大小。
Focal region size :focal region size是横向和纵向的sub-window数量。
Sub-window pooling:sub-window pooling方法,将多个token信息进行聚合,以此来减少计算量。那么,聚合的token数越多,后期attention计算需要的计算量也就越小,当然,关注的程度也就更加粗粒度,同样的聚集的token越多感受野越大。每个focal level中,首先将token划分成多个大小为swl*swl的sub-window,然后用一个线性层进行pooling操作:
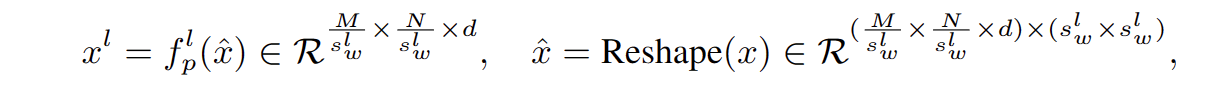
不同级别的池化特征图在细粒度和粗粒度上都提供了丰富的信息。由于我们为与输入特征图具有相同粒度的第一个焦点级别设置 slw = 1,因此不需要执行任何子窗口池化。考虑到焦点窗口大小通常非常小(在我们的设置中最大 7),这些子窗口池化引入的额外参数的数量相当可以忽略不计。
Attention computation:Focal-self-attention 具体的计算步骤其实和标准的Self-Attention很像,主要不同之处有两点1)引入了相对位置编码,来获取相对位置信息;2)每个query和所有细粒度的key和value都进行了attention的计算,因此本文方法的计算量其实还是不算小的。作者利用三个线性层分别计算第一层的query 和所有层的key与value。
![]()
由于在子窗口中的token共享相同环境,只需要将当前层的query和所有层的key、value进行带相对位置编码的Self-Attention

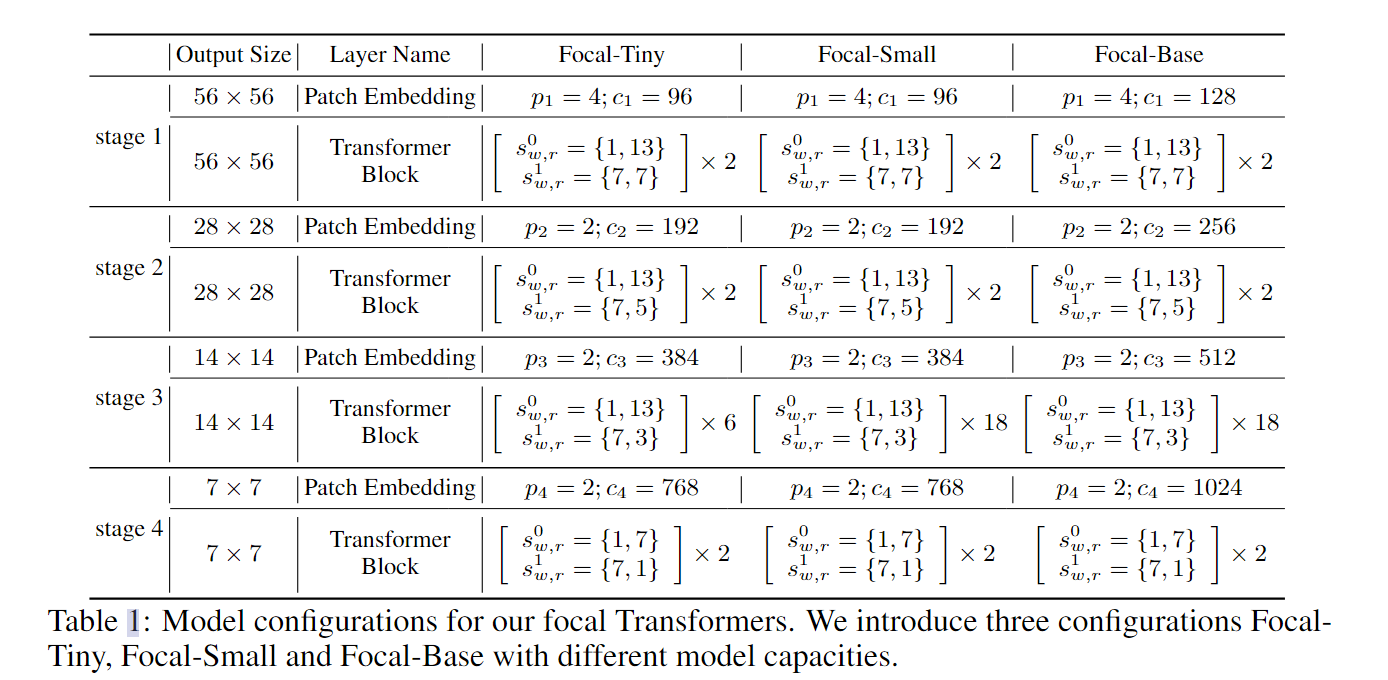
五、变体
- Self-attention Local-Global Interactions Transformers attentionself-attention local-global interactions transformers self-attention self-attention attention self recommendation self-attention sequential stochastic self-attention representation functional attention self-attention attention笔记self self-attention注意力attention机制 self-attention attention self 4.1 attention self-attention multi-head multi self-attention modifications predicting expression