代数聚合
计算向量\(\mathbf x^l \in \mathbb R^{1 \times d}\)的softmax值
如果有向量\(\mathbf x^{l_1}, \mathbf x^{l_2}, \in \mathbb R^{1 \times d}\),利用上述计算公式可以获得
现在希望计算由\(\mathbf x^{l_1}, \mathbf x^{l_2}\)构成的向量\(\mathbf x = [\mathbf x^{l_1}, \mathbf x^{l_2}] \in \mathbb R^{1\times2d}\)的softmax值。因此按照softmax计算过程,可以得到
FlashAttention证明
符号定义与计算
-
\(\pmb K_{:j} \in \mathbb R^{jB_c \times d}\)表示\(\pmb K\)的前\(jB_c\)行
-
\(\pmb V_{:j} \in \mathbb R^{jB_c \times d}\)表示\(\pmb V\)的前\(jB_c\)行
-
\(\pmb S_{:,:j} = QK_{:j}^T \in \mathbb R^{N \times jB_c}\)表示 \(\pmb Q\)与\(\pmb K\)相似度量矩阵\(\pmb S\)的前\(jB_c\)列
-
\(\pmb P_{:,:j} = softmax(\pmb S_{:,:j} ) \in \mathbb R^{N \times jB_c}\)表示按行对\(\pmb S_{:,:j}\)进行概率归一化。
-
\(m^{(j)}, l^{(j)}, \pmb O^{(j)}\)表示在HBM中的\(m, l, \pmb O\)在外层第j次迭代后的值
-
\(\pmb O^{(j)} = \pmb P_{:,:j} \pmb V_{:j}\)
-
矩阵按行取最大值 \(m^{(j)} = rowmax(\pmb S_{:,:j}) \in \mathbb R^N\)
-
矩阵按行减去对应行最大值取对数再求和: \(l^{(j)} = rowsum(exp\{\pmb S_{:,:j}-m^{(j)}\}) \in \mathbb R^N\)
证明
在进行第\(j\)次迭代时,计算得到的是\(m^{(j)}\);在进行第\(j+1\)次迭代过程中(对应取\(\pmb K, \pmb V\)的第\(jB_c-(j+1)B_c\)行即\(\pmb K_{j:(j+1)}\), \(\pmb V_{j:(j+1)}\)),当内层完成循环计算后,可以计算得到\(\pmb S_{:,j:j+1} = Q\pmb K_{j:(j+1)}^T\),从而得到\(\tilde m = rowmax(\pmb S_{:,j:j+1}) \in \mathbb R^N\)。
按照如下方式更新\(m\)得到,\(m^{(j+1)} = max(m^{(j)}, \tilde m)\)。这种迭代式计算结果与\(m^{(j+1)} = rowmax(\pmb S_{:,:j+1}) \in \mathbb R^N\)是一样的。
同理道理,按照如下方式更新\(l\),\(l^{(j+1)} = e^{m^{(j)}-m^{(j+1)}}l^{(j)} + e^{{\tilde m}-m^{(j+1)} } \tilde l\), 其中$ \tilde l = rowsum(exp{\pmb S_{:,j:j+1}-\tilde m})$ 。这种迭代式计算结果与$ \tilde (l+1) = rowsum(exp{\pmb S_{:,:j+1} - m^{(j+1)}})$
按照下述公式更新\(\pmb O^{j+1}\),从公式第1行的更新公式出发,可以证明与等式最后1行是相等。说明了FlashAttention算法与原始Attention的结果是一样的。
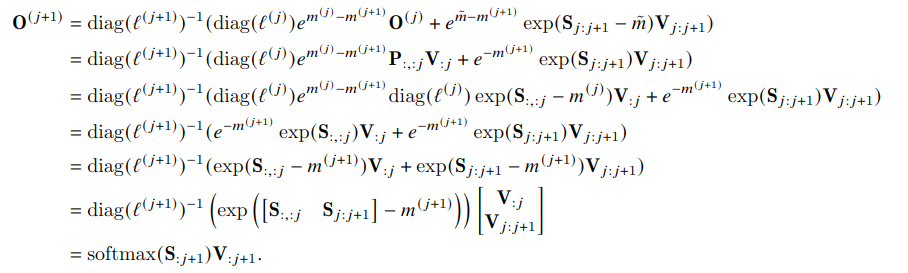
问题1: 为什么需要内层循环,不能去除吗?
用于计算的芯片SRAM 存储空间有限,除了加载HBM中数据,计算过程还需要申请额外空间用于存储计算中间结果如相似性度量矩阵
问题2: 为什么内存有效,还能加速训练呢?
Algorithm 0

第1步-第3步,HBM 读写总量依次为: \(2Nd+N^2\), \(2N^2\), \(2Nd+N^2\),总的为\(4(Nd+N^2)\);而论文中用\(\Theta(Nd+N^2)\)表示,符号\(\Theta\)应该表示同阶含义。
Algorithm 1

- 外循环执行完第6步,将完整从HBM中读取\(\pmb K,V\),读取量\(2Nd\)
- 单次内循环执行完第8步,将完整从HBM中读取\(\pmb {Q, O}, l, m\),读取量\(2Nd+2N\);外层循环执行\(T_c\)次,总读取量\(2NdT_c + 2NT_c\)
- 单次内循环执行完第12-13步,将完整向HBM中写\(\pmb {O}, l, m\),写入量\(Nd+2N\);外层循环执行\(T_c\)次,总写入量\(NdT_c+2NT_c\)
综合得到总的数据读写量为\(2Nd+3NdT_c+4NT_c\);而论文中用\(\Theta(NdT_c)\)表示。
由于用于计算的SRAM内存有限(100KB左右),因此需要将\(\pmb Q, K, V, O\)进行分块拆分。拆分的\(\pmb K_j, V_j \in \mathbb R^{B_c \times d}\), \(\pmb Q_i, O_i \in \mathbb R^{B_r \times d}\)。因此仅考虑将\(\pmb K_j, V_j\)放入HBM,则\(2B_cd=M\); 仅考虑将\(\pmb Q_i, O_i\)放入HBM中,则\(2B_rd=M\);同时由于计算过程中,还需要至少存储\(S_{ij}, l_i, m_i\),先忽略\(\tilde {m_{ij}}, \tilde {\pmb P_{ij}}, \tilde {l_{ij}}\). 则有\(B_cB_r = M\)。总的下来,则有\(2B_rd+2B_cd+B_cB_r = M\).
基于论文中推到,$$B_c = \Theta (\frac{M}{d}), B_r=\Theta(min(\frac{M}{d}, d)), T_c = \frac{N}{B_c} = \Theta(\frac{Nd}{M})$$实际上考虑到SRAM内存有限,\(B_c\) 仅可以设置为 \(B_c=\frac{M}{\alpha d}\),按照论文中设置,\(\alpha\)取值4附近某个值时,能保证\(\frac{M}{\alpha d}=\lceil \frac{M}{4 d} \rceil\)。那么$ T_c = \frac{N}{B_c} = \frac{\alpha Nd}{M}$,因此Algorithm 1的总读写量为\(2Nd+3NdT_c+4NT_c = 2Nd + \frac{3\alpha N^2d^2}{M} + \frac{4\alpha N^2d}{M}\)。
于是Algorithm 0与 Algorithm 1 的HBM读写量相减得到
在M=100KB, \(\alpha=4, d=128\)时,上述式子约等于\(2Nd+2N^2\),由此可见后者数据的读写量要少,整体上加速了Attention操作计算。