会议:WWW,时间:2023,学校:东北大学计算机与通信工程学院
摘要:
目前TKGC模型存在的问题:只考虑实体或关系的结构信息,而忽略了整个TKG的结构信息。此外,它们中的大多数通常将时间戳视为一般特征,不能利用时间戳的潜在时间序列信息。
本文的方法:一种基于自注意机制和历时嵌入技术的分层自注意嵌入(HSAE)模型
原理:对于整个TKG的结构信息,本文将TKG划分为实体层和关系层,然后分别对实体层和关系层应用自关注机制捕获结构信息。对于时间戳的时间序列信息,本文将位置编码和历时嵌入技术结合到上述两个自关注层中进行捕获。最后,本文可以得到实体、关系和时间戳的嵌入表示向量,这些向量可以与其他模型结合使用以获得更好的结果。
介绍:
对于从时间戳\({t_0}\) 到时间戳 \({t_T}\) 的 TKG,TKG补全的任务通常分为两类:插值和外推。外推任务的目的是推理那些时间戳\({t>t_T}\)的事实,即利用历史知识来预测未来的事实。插值任务的目的是使用历史信息和未来信息来推理时间戳 \({t_0<t<t_T}\) 的事实。本文专注于插值任务,并针对的是预测实体的任务。
现有方法1:专注于扩展现有的静态KG补全模型。它们主要是通过计算每个时间戳的隐藏表示并扩展评分函数以利用时间戳表示以及实体和关系表示(例如,DE 模型 [9]、T mdoels [19]、TNT 模型 [14] 和 TuckERT 模型) [23])。
存在问题:忽略图结构信息。
现有方法2:基于注意力的模型,如EvoExplore [30],为TKG的结构信息建模提供了框架。 EvoExplore尝试使用注意力机制来计算相关实体或关系之间的相似度,然后为其分配权重,从而处理TKG中的图结构信息。
存在问题:
1.对于TKG来说,给定的实体或关系本身也是图结构信息的一部分,即实体或关系本身也应该被赋予权重。
2.他们中的大多数通常将时间戳视为通用维度,忽略了时间戳对TKGC任务至关重要的潜在时间序列信息。
本文模型:一种分层自注意力嵌入(HSAE)模型
模型架构:两层组成:实体级自注意力嵌入层和关系级自注意力嵌入层
模型原理:将TKG视为两层:实体层和关系层。为了捕获TKG的图结构信息,本文分别在上述两层应用自注意力机制。对于时间序列信息,本文使用位置编码将时间戳整合到实体和关系的自注意力计算中。然后本文将自注意力层的输出与历时嵌入技术相结合以获得最终表示向量,该表示向量可以与其他当前的KG补全模型相结合
相关工作:
静态KG补全:不过多介绍
时序KG补全:
插值:
大多数 TKGC 模型都专注于扩展现有的静态 KG 补全模型。例如,TTransE [15] 通过将时间戳嵌入添加到得分函数来扩展 TransE。受 TransH 的启发,HyTE [5] 将每个时间戳表示为一个超平面,然后将实体和关系投影到该超平面。为了合并时间信息,TA-DistMult [8] 采用循环神经网络来学习谓词的时间感知表示,然后在 DistMult 中使用。在历时词嵌入的推动下,DE-SimplE [9]将历时实体嵌入功能与静态模型 SimplE 相结合,能够指导模型学习实体在任意时间点的时间特征,以进行 TKGC。受四阶张量 tucker 分解的启发,TuckERT [23] 提供了三种方法,包括余弦相似性、对比学习和基于重建的方法,将先验知识融入到所提出的模型中。 BoxTE [20] 使用专用时间嵌入,允许灵活地表示时间信息。因此,它引入了框来表示与时间无关的查询的一组答案实体。
外推:
RE-Net [11] 提出了一种循环事件编码器来编码历史知识,并采用邻域聚合器来建模并发知识。 RE-GCN [18]通过对 TKG 序列进行循环建模来学习实体和关系的进化表示。 CluSTeR [17] 采用强化学习来发现固定长度的查询相关路径中的进化模式。 EvoExplore [30]同时模拟局部和全局结构演化。它包含一种新颖的基于分层注意力的时间点过程和一种新颖的基于软模块化的社区划分组件。
现有方法存在的问题:
大多只关注实体的表示学习,并没有发现实体和关系的表示同样重要。因此,本文提出了一种新的分层自注意力模型。在实体层面,目标实体由相关实体表示,在关系层面,目标关系由相关关系表示。这将自注意力引入到本文的模型中。此外,现有的注意力模型几乎忽略了有用的时间信息,因此本文将时间信息编码为实体和关系以提高效果。
问题的形式化表达:
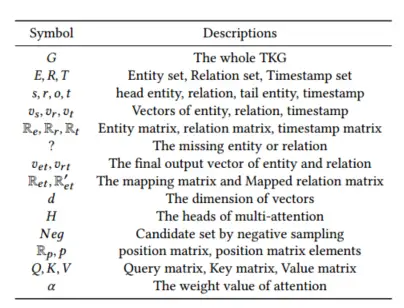
我总结来说,本文主要研究的任务是在时间戳为\({t_0<t<t_T}\)的情况下,查询缺失的客观实体\({(s,r,?,t)}\)。下图展示了本文中的关键符号和描述:
模型方法:
模型层次结构:
为了捕获TKG的图结构信息,本文将TKG分为实体层和关系层,如下图所示。左边的块代表原始TKG,其中s代表主题实体,r1,r2和r3代表不同的关系,o1 ,o2,o3,o4和o5代表不同的对象实体,t1,t2和t3代表不同的时间戳。右边的块代表本文的层次结构。假设给定一个事实 (s, r2, o5, t2)。对于关系层,本文可以发现r1和r3与r2相关(下图中的右侧块)。也就是说,r1和r3(按时间戳排序)包含r2的图结构信息,应将其输入到关系级自注意力嵌入层以获得r2的表示向量。
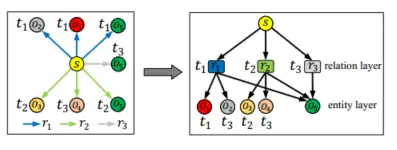
对于实体层,根据图1右块,本文可以通过在时间戳t2处绑定实体s和关系r2,得到实体s的相关实体o3、o4和o5。也就是说,o3、o4和o5(按时间戳排序)是s的图结构信息,应该输入到实体级自注意力嵌入层中以获得s的表示向量。
编码器模块:
模块组成:主要由两层组成,分别是实体自注意嵌入层和关系自注意嵌入层。
模块架构:如下图所示,本文首先通过位置编码技术将输入的时间序列编码到实体矩阵,然后依次经过实体级自注意力层和前馈层。对于关系,本文使用实体和时间戳构建一个矩阵空间,然后将关系矩阵映射到该空间。同时,本文还构造了关系的位置矩阵,与关系矩阵相加作为关系级自注意力层的输入。最后,通过前馈层得到实体的最终表示向量。
以下图为例。对于给定的查询(s,r2,?,t2),本文首先根据TKG的层次结构确定与给定头实体s有关系r2的所有实体的集合(包含o3,o4和o5),并排序这些实体根据时间戳。然后将它们嵌入到d维向量中,然后将它们用于形成实体矩阵\({\mathbb{R}_e^{(n\times d)}}\)(包含s、o3、o4和o5),作为实体自注意力嵌入层的输入。同时,为了保留TKG的时间序列信息,本文构造了与实体矩阵\({\mathbb{R}_e^{(n\times d)}}\)大小相同的位置矩阵\({\mathbb{R}_p^{(n\times d)}}\)。本文将位置矩阵设计为\({p_{\left( i,2j \right)}=\sin \left( \frac{i}{10000^{2j/d}} \right)}\)与\({p_{\left( i,2j+1 \right)}=\cos \left( \frac{i}{10000^{2j/d}} \right)}\)。其中p表示矩阵\({\mathbb{R}_p^{(n\times d)}}\)中的元素,i和j表示p在矩阵中的行号和列号。
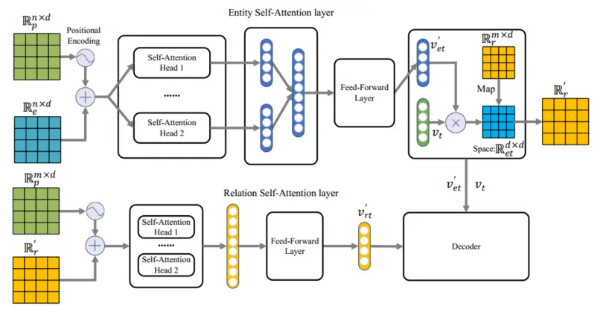
为了获得包含时间序列信息的实体矩阵\({\mathbb{R}_e^\prime}\),本文将实体矩阵\({\mathbb{R}_e^{(n\times d)}}\)和位置矩阵\({\mathbb{R}_p^{(n\times d)}}\)相加。实体矩阵\({\mathbb{R}_e^\prime}\)计算过程为:\({\mathbb{R}_e^\prime=\mathbb{R}_e^{(n\times d)}+\mathbb{R}_p^{(n\times d)}}\)。
对于实体矩阵\({\mathbb{R}_e^\prime}\)中包含的图结构信息,本文使用实体级自注意力层来处理。此外,本文使用多头注意力来防止过度拟合。下图详细说明了本文的单头自注意力机制的计算过程。对于实体矩阵\({\mathbb{R}_e^\prime}\),第一行是给定的实体 s,获得其嵌入表示是此阶段的目标。因此,本文只需要进行一次单注意力计算就可以得到一个表示向量,不需要计算所有的结果。因此,本文将给定的实体向量\({\mathbb{R}_e^\prime}\)[1] (s) 分别视为 Query、Key 和 Value,其余的视为 Key 和 Value(其中\({\mathbb{R}_e^\prime}\)[1] 表示矩阵的第一行)。查询矩阵Q、键矩阵K和值矩阵V计算如下式所示:\({Q=\mathbb{R} _{e}^{\prime}\left[ 1 \right] W^q}\),\({K=\mathbb{R} _{e}^{\prime}W^k}\)和\({V=\mathbb{R} _{e}^{\prime}W^v}\)。其中\({W^q,W^k,W^v}\)分别代表三个不同的权重矩阵。
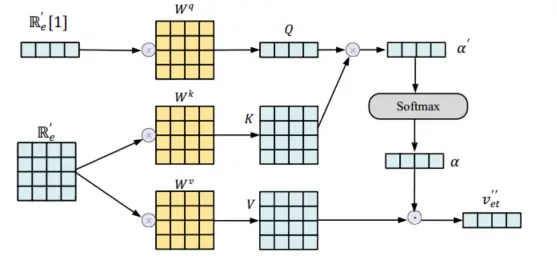
为了得到每个实体(包含 s、o3、o4 和 o5)的权重α,本文采用Scaled Dot-Product Attention来计算实体的注意力,Softmax用于标准化。其计算公式:\({\alpha = Softmax(\alpha^\prime)=Softmax(\frac{QK^T}{\sqrt{d}})}\),其中\({\alpha^\prime}\)为未经过归一化的权重值。本文将实体权重矩阵与对应的实体相乘,然后求和得到单头注意力\({v_{et}^{\prime\prime}}\)的输出结果,计算过程:\({v_{et}^{\prime\prime}=\sum_{i=0}^n{\alpha \left[ i \right] V\left[ i \right]}}\)将所有单头注意力的输出拼接成一块,就是实体级自注意力模型的最终输出,计算过程:\({v_{et}^{\prime\prime\prime}=\prod_{h=1}^H{v_{et}^{\prime\prime k}}}\)其中\({\prod}\)表示连接操作,H表示独立注意力头的数量。为了减少多头注意力带来的维度,本文将向量v输入到Feed-Forward层,该层包含两个全连接层和一个激活函数GELU。 Dropout技术和Layer Normalization也被用来解决过度拟合问题。计算过程:\({v_{et}^{\prime}=LN\left( GELU\left( v_{et}^{\prime\prime\prime}W_1+b_1 \right) W_2+b_2+v_{et}^{\prime\prime\prime} \right)}\),其中\({W_1\in \mathbb{R}^{d\times 2d}}\)与\({W_2\in \mathbb{R}^{d2\times d}}\)是线性变换矩阵。
时间非敏感实体:
此外,本文认为并非所有事实都是时间敏感的,例如(Lionel Messi,Born In,Argentina,1987),它是长期有效的,因此时间信息对这些事实的重要性不如其他时间敏感事实。受历时嵌入技术的启发,本文使用时间信息权重β来控制实体嵌入中时间信息的比例。实体\({v_{et}}\)最终的计算过程为:\({v_{et}=\left( 1-\beta \right) v_e+\beta v_{et}^{\prime}}\)。
对于关系,为了保留图结构信息,本文通过实体层自注意力模块输出的实体向量\({v_{et}}\)和输入的\({v_t}\)构造空间矩阵\({\mathbb{R}^{d\times d}_{et}}\),矩阵的计算过程为:\({\mathbb{R} _{et}^{d\times d}=v_{et}v_{t}^{T}}\)
之后,本文将关系矩阵\({\mathbb{R}^{m\times d}_{r}}\)投影到矩阵空间\({\mathbb{R}^{d\times d}_{et}}\)中,得到包含时间信息和实体信息的关系向量。映射关系矩阵\({\mathbb{R}^{\prime}_{r}}\)的计算过程为:\({\mathbb{R}^{\prime}_{r}=\mathbb{R}^{m\times d}_{r}\mathbb{R}^{d\times d}_{et}}\),其中m×d表示矩阵维度,m表示关系数,d表示嵌入维度。
根据上述计算式,本文执行与\({\mathbb{R}_e^{\prime}}\)相同的操作(指进行矩阵变换和最后的拼接),经过关系级自注意力层和前馈层,得到关系\({v_r}\)的最终表示\({v_{rt}}\)。
解码器模块:
通过模型的编码器模块,本文可以获得包含时间序列信息和图结构信息的实体和关系的嵌入表示。然后本文将嵌入表示输入到解码器中并使用它们来训练模型。解码器模块如下图所示,其中\({\mathbb{R}^\prime_s}\)和\({\mathbb{R}^\prime_o}\)是实体级自注意力嵌入层的输出矩阵,\({\mathbb{R}^\prime_r}\)是关系级自注意力嵌入层的输出矩阵,\({\mathbb{R}_t}\)是时间戳的嵌入矩阵。这些矩阵被输入到分数函数中以计算它们各自的分数。使用Softmax层处理这些分数可以获得它们各自的概率,然后通过Cross-Entropy层计算模型的损失。
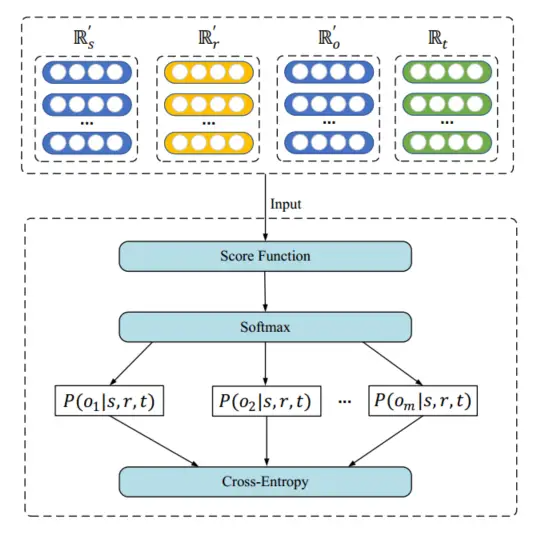
为了验证本文模型的有效性,本文将 HSAE 与最新的代表性 TKG 嵌入模型 T-Simple 相结合。该扩展模型称为 HSAE-Simple。本文首先使用负采样技术来构建候选集Neg。 Neg包含一个正确的实体和m个随机实体。然后使用Softmax函数计算每个候选实体的概率分布,以最大化正确实体的概率。在 HSAE-SimplE 中,每个实体 e 的嵌入有两个向量\({v_s,v_o\in \mathbb{R}_e^{n\times d}}\) ,每个关系 r 有两个向量 \({v_r,v_r^{-1}\in \mathbb{R}_r^{m\times d}}\),每个时间戳 t 有一个向量 \({v_t}\) 。评分函数为:
\({Sco\left( v_s,v_r,v_{o}^{\prime},v_t \right) =\frac{1}{2}sum\left( \left( v_{st}*v_{rt}*v_{ot}*v_t \right) +\left( v_{st}*v_{rt}*v_{ot}*v_t \right) ^{-1} \right)}\)
因此,最终的损失函数为:
\({L\left( s,r,t \right) =-\sum_{\left( s,r,o,t\in E_{train} \right)}{\frac{\exp \left( Sco\left( v_s,v_r,v_{o}^{\prime},v_t \right) _o \right)}{\sum_{i\in Neg}{\exp \left( Sco\left( v_s,v_r,v_{o}^{\prime},v_t \right) _i \right)}}}}\)
类似地,预测缺失头部实体的任务 (?, r, o, t) 的损失函数为 L (s,r,t)。由此,全局损失函数Loss的表达式为:
\({Loss=L(s,r,t)+L(o,r,t)}\)
伪代码如下:

实验:
前期设置:
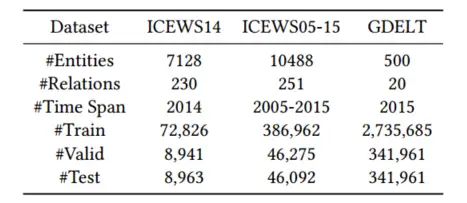
数据集:ICEWS14,ICEWS05-15和GDELT
评判标准:
对于实体预测,本文替换每个测试四元组的头或尾实体以创建两个负四元组:(s,r,?,t) 和 (?,r,o,t),然后混合正四元组和负四元组。使用评分函数MRR和Hist@K对这些实体进行分级并按降序排列。
基线模型:
对于静态 KGC 模型,本文包括 TransE、DistMult 和 Simple。值得注意的是,本文忽略了所有静态基线模型输入中的时间戳维度。
对于 TKGC 模型,本文包括 TTransE、Hyte、DE 模型(DE-TransE、DEDistMult 和 DE-SimplE)、T 模型(T-DistMult、T-ComplEx 和 T-SimplE) )。 TuckERT 模型 和 EvoExplore 模型。
参数设置:
本文使用 PyTorch 进行模型并将本文的模型与 T 模型结合起来 [19]。一些参数设置确定如下。本文选择批量大小b = 512,最大epoch = 500,嵌入维度k = 100,时间比率beta = 0.5,学习率lr = 0.001,时间嵌入维度tdim = 64,Dropout在0.0,0.2,0.4之间。具体来说,对于 ICEWS 数据集,本文为所有实验设置负比率 neg = 500,而对于 GDELT,由于数据集较大,neg 设置为 5。此外,采用 ADAM 作为本文的默认优化器。所有实验均在具有 GPU 的核心上进行。
实验结果:
通过将本文的 HSAE 模型与最新的时间平移模型 T-SimplE、T-ComplEx 和 T-DistMult 相结合,本文构建了三个实验模型:HSAE-SimplE、HSAEComplEx 和 HSAE-DistMult。在最佳配置中,每个数据集的结果是通过平均指标(5次运行)获得的。与基线相比的实验结果如表3所示,总结如下:
- 在 ICEWS14 数据集上,HSAE-Simple 在 MRR、Hit@1、Hit@3 和 Hit@10 指标上比 EvoExplore 模型和 T-SimplE 模型提高了 1.23% 和 23.3%。
- 在ICEWS05-15 数据集上,HSAE-Simple 在所有指标上比EvoExplore 模型和TSimplE 模型分别提高了32.1% 和84.3%。
- 在GDELT 数据集上,HSAE-Simple 在所有指标上均比EvoExplore 模型和T-SimplE 模型提高了32.4% 和110.4%。
- 上述结果表明本文的模型在所有数据集上都有显着改进。此外,改进在 GDELT 数据集上最为明显。
- 这些结果凸显了HSAE通过应用分层自注意力机制来提高TKGC任务性能的能力,并证明了图结构信息和时间序列信息在TKGC任务中的重要性
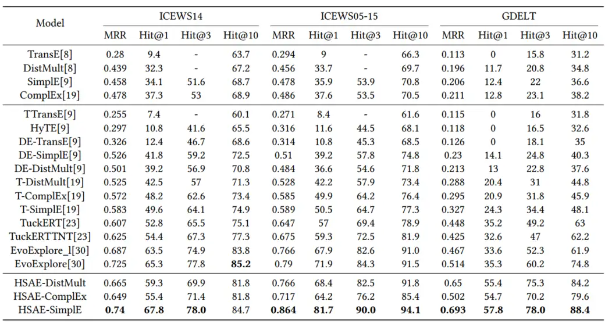
消融研究:
本文进行了两项消融研究来分析 HSAE 中不同成分的贡献。为了了解自注意力机制和时间信息在 HSAE 中的贡献,本文在 ICEWS14 的测试集上对 HSAE-SimplE 进行了消融研究,如表 4 所示。 HSAE-SimplE (-ER) 表示 HSAE-SimplE 没有实体和关系自注意力层。实验结果表明,没有分层自注意力模块的模型在 MRR 上的准确率下降了 21.1%,这证明了本文的分层自注意力模块的重要性。 HSAE-SimplE (-T)表示评分函数中没有时间维度的模型。根据表4,本文可以发现MRR的实验结果下降了2.1%。 HSAE-SimplE (RELU)表示用RELU替换Sigmoid函数GELU的模型。实验结果表明MRR有所下降。
敏感性研究:
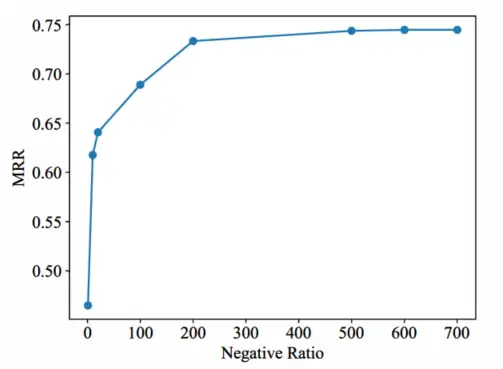
在保持其他参数不变的情况下,本文在ICEWS14上使用不同的负无线电对HSAE-SimplE进行了测试。如图5所示,本文将负射电负的值分别设置为1、10、20、100、200和500。实验结果表明,磁阻比与负辐射成正比。在负无线电达到200之前,MRR值随着负无线电的增加而迅速上升。负射值达到200后,MRR的增长率逐渐趋于稳定。当负辐射值达到500时,几乎不再增加。因此,500是负无线电的合理选择。
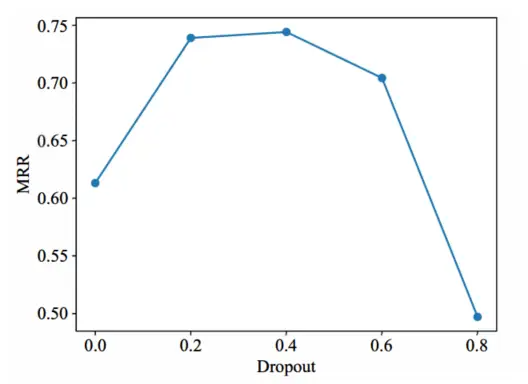
本文从0.0,0.2,0.4,0.6,0.8验证Dropout的值。如图6所示,在Dropout值达到0.4之前,MRR值随着Dropout的增大而迅速上升。这是因为dropout丢弃了一些参数来解决模型的overft问题。当Dropout值大于0.4时,MRR值随着Dropout值的增大而迅速下降。因此,0.4是Dropout的最佳值。
缺陷分析:
该方法通过将实体和关系的两层自关注机制与张量嵌入方法相结合,获得隐含图结构信息和时间信息的实体和关系的嵌入表示。然而,本文的模型也有不完善之处。它在插值任务上表现出色,但不能应用于外推任务。通过根据时间戳屏蔽事实,本文可以将模型扩展到外推。此外,本文对大数据集(大量事实)的改进效果明显大于对小数据集的改进效果。这是因为小数据集的事实少,实体和关系之间的联系不紧密,限制了注意机制的有效性。本文可以使用小数据集附加信息的方法来增强实体和关系的表示,以提高模型在小数据集上的准确性。
- 时序 图谱 Self-Atention Hierarchical Completion时序 图谱self-atention hierarchical 时序 图谱decomposition completion 数据库 数据 时序 图谱 时序 图谱 增量embedding-based 时序 图谱correlations relational 时序commonsense-guided图谱commonsense 时序 图谱reinforcement attention 时序 图谱 模型 知识 时序 图谱path-memory knowledge 时序 图谱contrastive historical