论文阅读13-SCGC:Simple Contrastive Graph Clustering
存在的问题
由于对比学习的发展,设计了更加一致和有辨别力的对比损失函数来取代网络训练的聚类引导损失函数。结果,缓解了手动试错问题,并提高了聚类性能。然而,复杂的数据增强和耗时的图卷积操作降低了这些方法的效率。
如何解决问题
为了解决这个问题,我们提出了一种简单对比图聚类(SCGC)算法,从网络架构、数据增强和目标函数的角度改进现有方法。
- 架构,我们的网络包括两个主要部分,即预处理和网络主干。简单的低通去噪操作将邻居信息聚合作为独立的预处理,并且仅包含两个多层感知器(MLP)作为主干。
- 数据增强,我们没有在图上引入复杂的操作,而是通过设计参数非共享编码器并直接破坏节点嵌入来构造同一顶点的两个增强视图。
- 目标函数,为了进一步提高聚类性能,设计了一种新颖的跨视图结构一致性目标函数,以增强学习网络的判别能力。
对比学习不同之处
AGE:论文阅读—Adaptive Graph Encoder for Attributed Graph Embedding_adaptive encoder_笃℃的博客-CSDN博客
DCRN:Deep Graph Clustering via Dual Correlation Reduction_友谊路夹老师的博客-CSDN博客
MCGRL:结点级别与图级别通用的自监督框架:MVGRL-CSDN博客
数据增强、网络架构和目标函数这三个关键因素显着决定了对比方法的聚类性能。
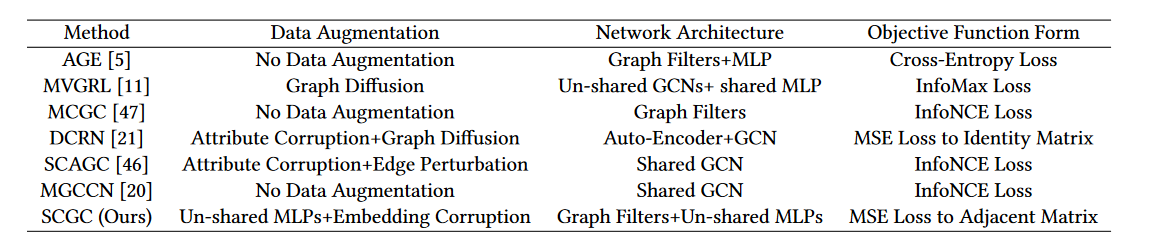
根据这些因素,我们在表 1 中总结了我们提出的 SCGC 和其他对比深度图聚类方法之间的差异。
- 数据增强。对比方法中现有的数据增强旨在通过在图上引入复杂的操作来构建同一顶点的不同视图。具体来说,MVGRL和DCRN采用图扩散矩阵作为增广图。此外,SCAGC通过随机添加或删除边来扰乱图拓扑。此外,DCRN和SCAGC通过属性损坏对节点属性进行增强。尽管被验证是有效的,但这些数据增强很复杂,并且仍然困扰着训练期间的聚合和转换,从而限制了对比方法的效率。与它们不同,我们SCGC通过简单地设计参数非共享编码器并直接破坏嵌入来构造同一顶点的两个增强视图,而不是在图上引入任何复杂的操作。
- 网络架构。对于网络架构,SCAGC 和 MGCCN 都使用共享的 GCN 编码器 对节点进行编码。不同的是,MVGRL采用两参数非共享GCN编码器和共享MLP作为骨干。此外,DCRN 利用自动编码器 和 GCN 编码器将增强视图嵌入到潜在空间中。然而,之前的GCN编码器在训练过程中都纠缠着变换和聚合操作,从而导致较高的时间成本。为了解决这个问题,AGE 通过图拉普拉斯滤波器 和一个 MLP 将 GCN 中的这两个操作解耦。与 AGE不同,我们用两个独立的 MLP 来编码平滑的节点属性,它们具有相同的架构但不共享参数。
- 目标函数。MVGRL设计了InfoMax损失以最大化节点和图的全局摘要之间的跨视图互信息。同时,AGE设计了一个任务,通过交叉熵损失对相似节点和不相似节点进行分类。随后,SCAGC、MCGC和MGCCN都采用infoNCE损失将正样本对拉到一起,同时推开负样本对。具体来说,基于相似度,MCGC将正样本定义为该节点的k近邻,而将其他节点视为负样本。 SCAGC 设计对比聚类损失以最大化同一聚类表示之间的一致性。 MGCCN 拉近了不同节点中同一节点的嵌入GCN 分层并推开不同节点的嵌入。此外,DCRN设计了MSE损失来减少特征级别和样本级别的冗余。与它们不同的是,我们设计了一种新颖的面向邻居的对比损失,以保持跨视图的结构一致性,从而提高我们网络的判别能力。
模型详情
模型架构图
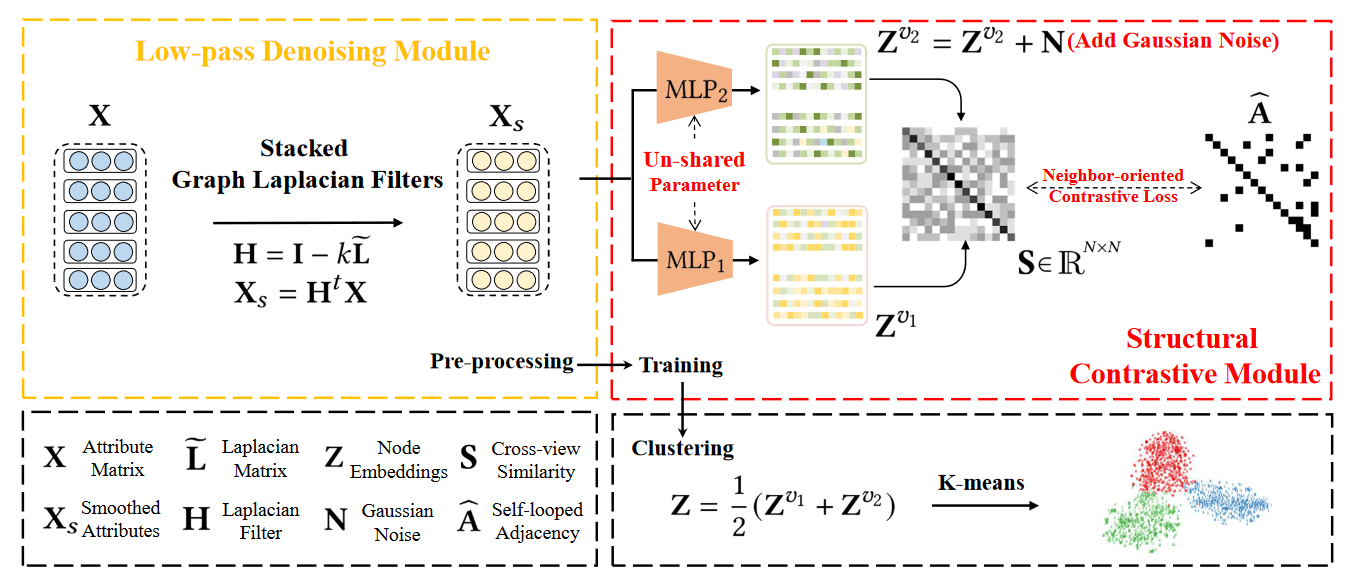
SCGC的框架。它主要由两个部分组成:低通去噪操作和结构对比模块(SCM)。
我们首先通过低通去噪操作对节点属性进行预处理。然后,结构对比模块仅用两个 MLP 对平滑节点属性进行编码,并通过设计参数非共享编码器和破坏节点嵌入来构造节点嵌入的增强视图。此外,设计了一种新颖的面向邻居的对比损失来保持跨视图结构的一致性,从而提高网络的判别能力。
Low-pass Denoising Operation:低通去噪操作
有实验证明拉普拉斯滤波器可以达到与图卷积运算[16]相同的效果。受他们成功的启发,我们引入了低通去噪操作来进行邻居信息聚合,作为训练前的独立预处理。这样,属性中的高频噪声就会被有效地滤除。
其中 \(\tilde{L}\)表示对称归一化图拉普拉斯矩阵,k 是实值。对于k的选择,我们遵循AGE并在所有实验中设置k=2/3。随后,我们堆叠 t 层图拉普拉斯滤波器,
低通去噪操作,滤除属性中的高频噪声
Structural Contrastive Module 结构对比模块
架构和增强
两个不同视图之间保持结构一致性,从而增强网络的判别能力
我们首先使用设计的参数非共享 MLP 编码器对平滑属性 Xs 进行编码,然后使用 l2-范数对学习到的节点嵌入进行归一化。
Zv1 和 Zv2 表示学习节点嵌入的两个增强视图。值得一提的是,MLP1和MLP2具有相同的架构但不共享参数,因此Zv1和Z v2在训练期间将包含不同的语义信息。此外,我们通过简单地将随机高斯噪声添加到 Zv2 来进一步保持两个视图之间的差异,
我们通过设计参数非共享编码器并直接破坏节点嵌入而不是引入针对图的复杂操作来构造两个增强视图 Zv1 和 Zv2,从而提高了训练效率。
设计新的目标函数
设计了一种新颖的面向邻居的对比损失以保持跨视图结构的一致性。
具体来说,我们计算 Z v1 和 Zv2 之间的跨视图样本相似度矩阵 S ∈ RN ×N,
Si j 表示第一视图中的第 i 个节点嵌入与第二视图中的第 j 个节点嵌入之间的余弦相似度。然后我们强制跨视图样本相似度矩阵 S 等于自循环邻接矩阵 b

我们将同一节点的跨视图邻居视为正样本,而将其他非邻居节点视为负样本。然后我们将正样本聚集在一起,同时将负样本推开。更准确地说,在等式中,第一项强制节点即使在两个不同的视图中也与其邻居达成一致,而第二项则最小化节点与其非邻居之间的一致性。这种面向邻居的对比目标函数通过保持跨视图结构一致性来增强我们网络的判别能力,从而提高聚类性能。
实验结果
对比实验
-
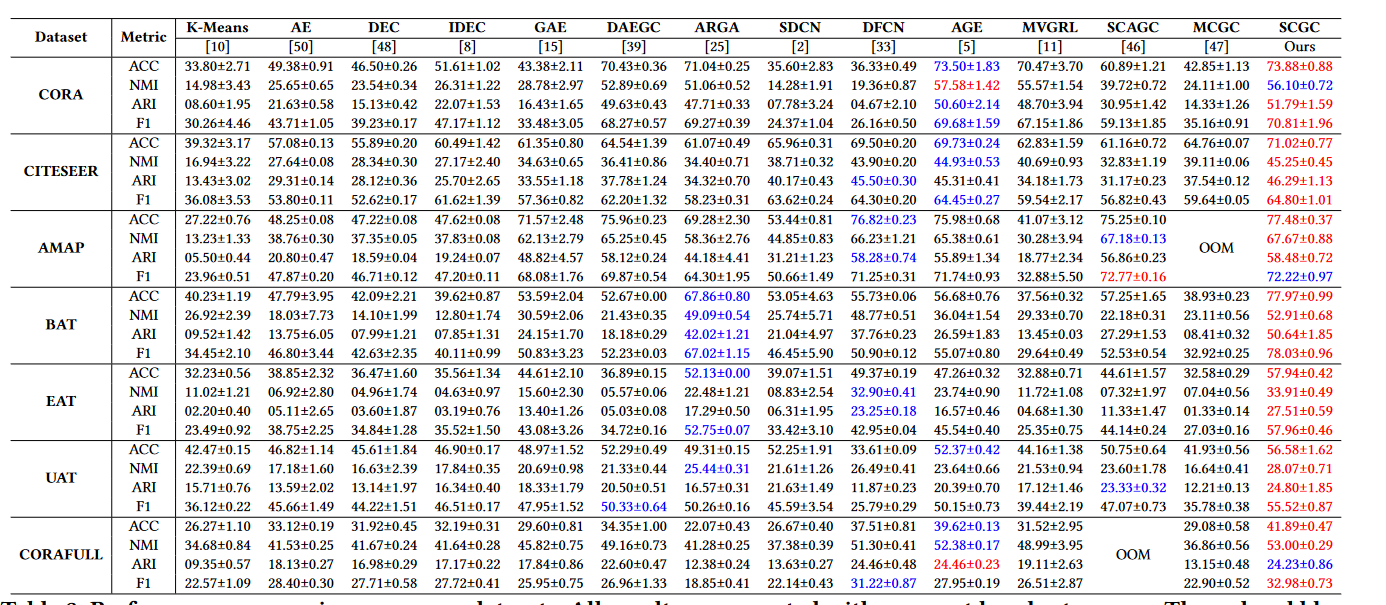
由于K-means是直接对原始属性进行的,因此得到的结果并不理想。
-
我们的SCGC超越了代表性的深度聚类方法,因为它们只考虑节点属性,而忽略了图中的拓扑信息。
-
与我们提出的 SCGC 相比,最近的对比方法 实现了次优性能。原因是我们通过在所提出的结构对比模块中保持跨视图结构一致性来提高样本的判别能力。
时间消耗:降低复杂度
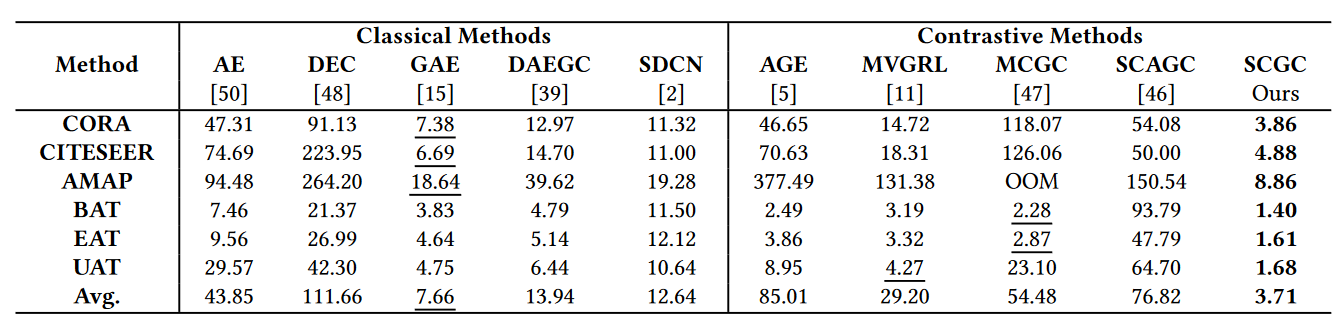
数据增强的有效性:自己增强和别的增强对比
在我们提出的 SCGC 中,我们通过设计参数非共享 MLP 编码器并向节点嵌入添加高斯噪声来构造同一节点的增强视图,而不是在图上引入复杂的操作。
“U”:参数非共享的策略MLP
“G”:节点嵌入添加高斯噪声
“U+G”:包含二者
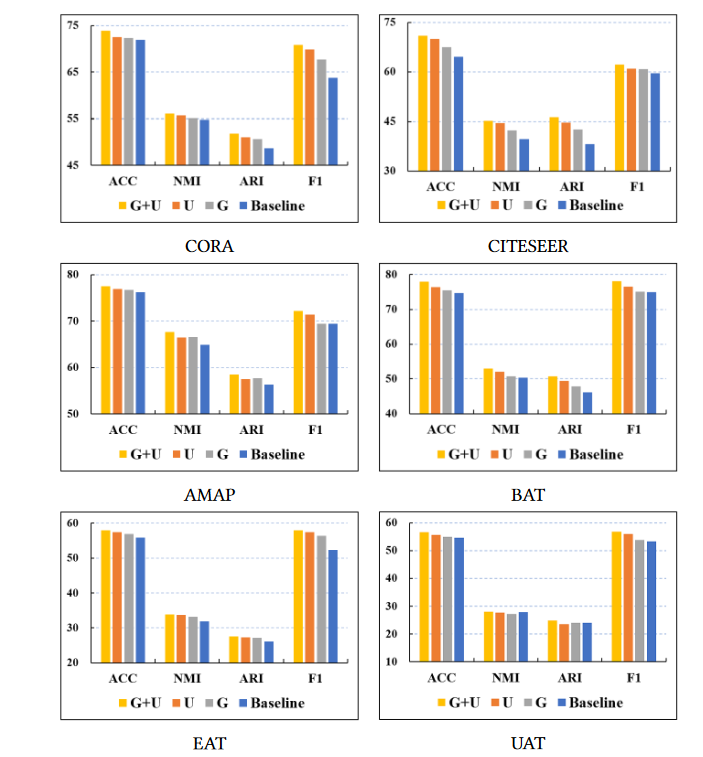
1)这两种简单的策略都旨在构建同一节点的两个不同视图,从而提高聚类性能。
2)这两种策略的结合达到了最好的性能。总之,我们通过这些实验结果验证了我们提出的数据增强方式的有效性。
我们的数据增强方式与其他经典图数据增强方式进行比较
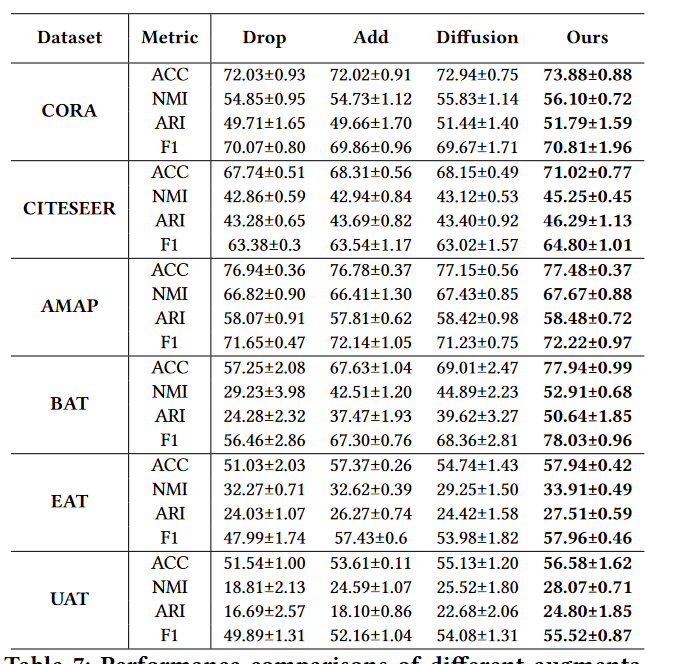
1)随机边缘丢弃和添加会损害聚类性能,这可能会导致语义漂移[28]。
2)图扩散在CORA和AMAP数据集上可以达到可比的性能,但无法与我们在其他数据集上的性能进行比较。它表明图扩散可能会改变图的底层语义。
- Contrastive Clustering Simple 论文 Graphcontrastive clustering simple论文 graph recommendation augmentations contrastive classification论文mixup graph clustering clustering-based scatter-clustering clustering algorithm learning machine attentional attributed clustering embedding clustering-based hierarchical personalized recognition clustering机器k-means笔记