https://blog.csdn.net/amusi1994/article/details/130037400
triplet loss中需要计算每个样本之间的距离,从而计算出loss,作者认为同一类的某些样本可能存在有害的信息,所以不应该将所有样本都用于计算loss。作者提出的SP loss中只计算挑选出来的样本的距离,从而得到loss。
我们提出的稀疏Pairwise损失函数(命名为SP loss)针对每一类仅采样一个正样本对和一个负样本对。其中负样本对为该类别与其他所有类别间最难的负样本对,而正样本对为所有样本的hard positive pair集合中的最不难positive pair(least-hard mining):
没看懂,到底正样本是什么,负样本是什么,能举个例子吗?
,我们的方法采样得到的正样本对中harmful positive pair的期望占比小于Triplet-BH和Circle等密集采样方法。?
harmful positive pair是什么?答:应该就是哪些识别起来困难的样本。
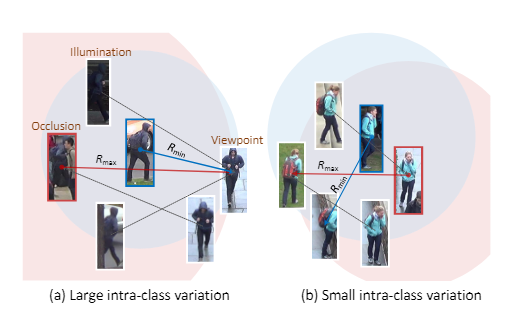
类内差异小的,每个实例都有有效的信息。
类内差异大的,部分实例中的信息是有害的。
本文提出的loss,可以自动识别并处理上述两种情况?
不需要和triplet loss一样,加上一个margin吗?
这不就是和负样本的距离之和吗?
anchor-free是什么意思?
SP loss为什么是anchor-free?
- Re-Identification Identification Adaptive Pairwise Sparsere-identification identification adaptive pairwise re-identification re-identification identification information re-identification identification transforming re-identification identification co-parsing re-identification identity-guided identification camera camera-conditioned re-identification re-identification intra-identity identification re-identification identification perspectives pairwise