一、论文信息
发表日期:2015年
发表机构:新加坡国立大学,计算机科学系
二、论文内容
1.解决问题:无人车在人员密集处的速度规划算法
2.方法:前向仿真+强化学习概念
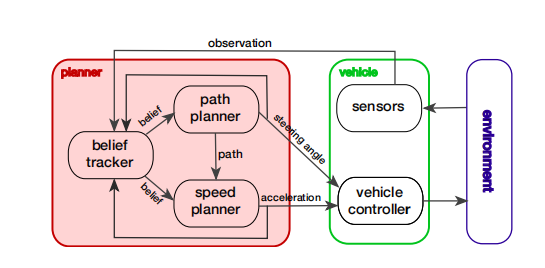

①.路径规划和速度规划进行解耦,进行速度规划之前路径已确定。
②.速度规划采取部分可观测马尔可夫决策过程,借用了强化学习的动作价值函数思想,S, A, Z, T, O, R, γ。设计状态变量、动作空间、动作价值函数。观测变量包括自车的状态变量(x,y,theta,v等)和行人的状态变量(x,y,v)。状态变量由观测值推出,基本与观测变量相同,但是需要由行人时序信息推测出其目的地goal(可能有多个)。动作价值函数考虑与行人距离、与目的地距离、快速性以及行驶的平稳性。动作空间为加速(0.5m/s^2)、减速(-0.5m/s^2)、匀速(0m/s^2)。在每个规划周期离线向前推导若干步,计算每个动作的价值函数,选取最大的一个进行执行。

三、方法性能分析
优点:具有较好的前瞻性,能够闭环模拟若干步
缺点:动作空间离散,引起动作不平顺;计算量大,无法及时响应突发情况;在论文中只把该算法和一种较为低级的反应式算法进行对比,无法真正证明此算法的优越性;代码未开源

- Intention-Aware Autonomous Intention Planning Drivingintention-aware autonomous intention planning intention-aware autonomous intention autonomous powered agents llm driving deep-neural-network-driven autonomous cdeepfuzz driving-license-subject-one first-person driving person first driving piggies luogu p2973