HierVST: 分层自适应零样本语音风格转换
摘要: 尽管语音风格转换(VST)领域取得了快速进展,但最近的零样本VST系统仍然缺乏将新的说话者的语音风格进行转换的能力。在本文中,我们提出了HierVST,这是一个分层自适应的端到端零样本VST模型。在没有任何文本转录的情况下,我们仅利用语音数据集通过使用分层变分推理和自监督表示来训练模型。此外,我们采用了分层自适应生成器,按顺序生成音高表示和波形音频。此外,我们利用无条件生成来提高声纹相关声学表示的能力。通过分层自适应结构,模型能够适应新的语音风格并逐步转换语音。实验结果表明,在零样本VST场景中,我们的方法优于其他VST模型。音频样本可在https://hiervst.github.io/获取。
关键词:语音转换,语音风格转换,零样本语音转换,自监督语音表示
引言
近年来,声音转换(VC)系统[1, 2, 3, 4, 5]在声音风格转换(VST)方面取得了快速的进展。同时,神经声码器模型[6, 7, 8, 9, 10]的进步加速了VC系统的发展,因为这些模型能够生成高保真的波形音频,并且端到端VC系统[11, 12, 13, 14]通过结合VC和神经声码器,产生了高质量的转换波形音频,受到了广泛的关注。然而,端到端模型仍然在说话者适应性能方面表现较差,并且需要文本转录来解开语言表示和语音之间的联系。因此,存在着需要配对的文本-音频数据集的限制。
为了利用非平行语音数据集,AutoVC [1]在内容表示上引入了信息瓶颈,以解开内容和风格信息,并仅通过自重构损失训练模型。然而,根据信息瓶颈大小,音频质量和VST性能之间存在权衡,选择适当的信息瓶颈大小有一定难度。F0-AutoVC [15]将AutoVC扩展为使用源语音的附加音高轮廓,并使用目标语音的统计信息将标准化音高轮廓转换为目标音高轮廓。尽管有这些音高轮廓指导,大多数F0提取算法存在提取不准确的F0的问题,导致生成的声音嘈杂,并且与目标说话者的声音风格不同。
[11, 16]利用一种离散的自监督语音表示单元和标准化F0的量化表示来重构语音,并仅通过替换说话者表示来转换语音。NANSY [17]利用连续的自监督语音表示,并引入语音扰动来仅从语音中获取语言表示。HierSpeech [18]也使用自监督语音表示来从语音中提取语言表示,但需要文本转录来使语言表示规范化,仅包含语言信息。基于扩散的VC系统[19, 20]也显示了生成性能的提高,但它们也需要文本转录来从提取的音素对齐中训练平均-Mel编码器[21]。此外,大多数模型在零样本VC方面仍然存在限制,导致在VST方面缺乏能力。
为了解决上述问题,我们提出了HierVST,这是一个分层自适应的端到端VST系统。我们采用了从单一语音中恢复与说话者无关的语言表示,以及从原始语音中提取与说话者相关的语言表示的多路径自监督语音表示。我们还引入了具有源模型的分层自适应生成器(HAG),并通过分层变分推理将多个表示连接起来。我们发现分层自适应是零样本VC成功的关键。此外,我们提出了韵律蒸馏来增强语言表示,并在HAG上使用无条件生成来提高声纹相关声学表示的能力,以实现更好的说话者适应性。实验结果表明,在零样本VST场景中,我们的模型在音频质量和说话者相似度方面优于其他模型,而无需任何文本转录。
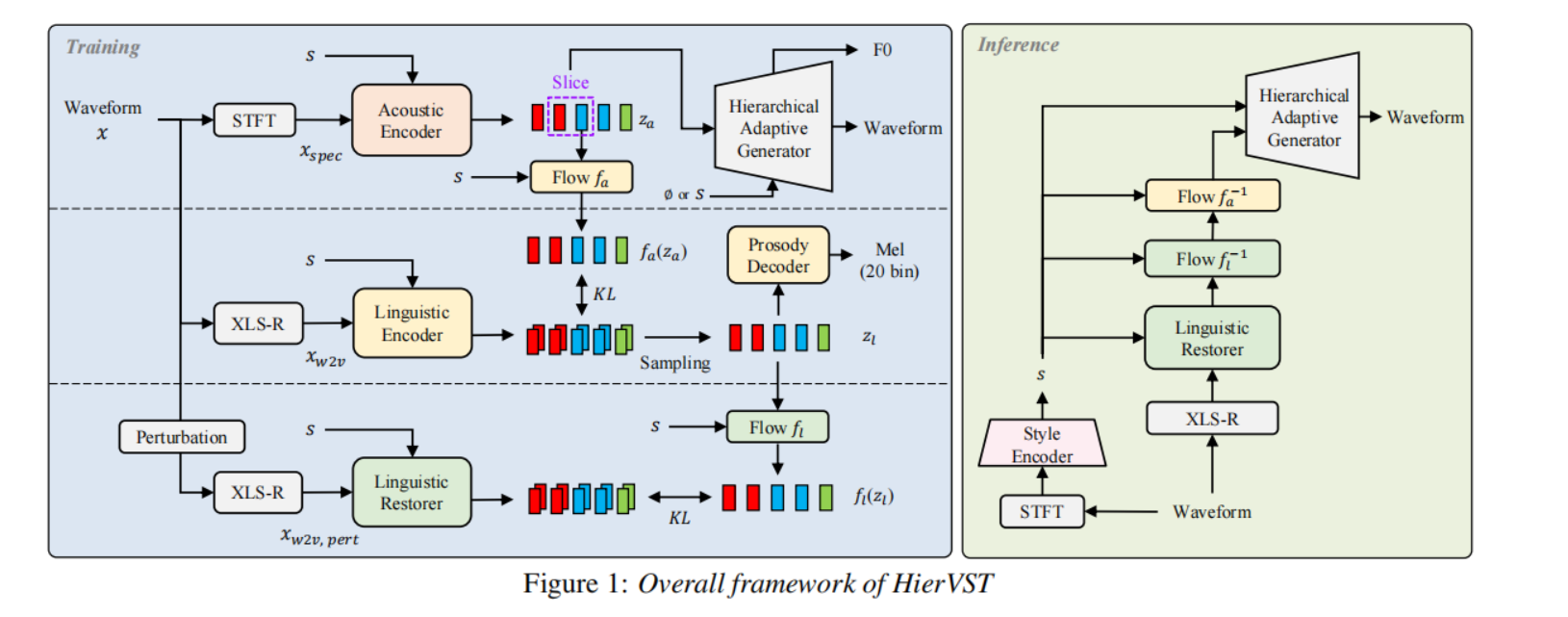
HierVST
我们提出了一种分层自适应的端到端VST系统——HierVST。对于未转录的语音转换,我们引入了多路径自监督语音表示,并采用分层变分推理将语音表示连接起来。此外,我们引入了HAG(分层自适应生成器)、韵律蒸馏和无条件生成,以实现更好的说话者适应性。具体细节如下所述。
2.1. 语音表示
对于语音转换,我们首先将语音分解为扰动的语言表示、语言表示和声学表示,并从解耦表示中重新合成语音。我们使用高分辨率线性频谱图提取声学表示,遵循[12, 18]的方法。对于说话者适应,我们还从Mel频谱图中提取样式表示。
按照[18]的方法,我们从XLS-R的中间层中提取wav2vec特征xw2v,XLS-R是一个使用大规模跨语言语音数据集进行预训练的自监督模型。为了实现语音解耦,我们引入了多路径自监督语音表示,通过利用数据扰动[17]从同一自监督语音模型中减少内容无关的特征。从扰动语音中提取的xw2v,pert被输入到语言恢复器中以恢复语言表示。提取的xw2v被输入到语言编码器中以提取增强的语言表示。
2.1.2.
风格表示 对于全局声音风格表示(音色信息),我们从Mel频谱图中提取风格表示。风格编码器[22]用于提取风格表示,它是单个句子的平均风格向量,并且该编码器与模型一起进行端到端的联合训练。对于分层风格自适应,此风格表示被馈送给所有网络,包括语言恢复器、语言编码器、声学编码器、标准化流模块和HAG。对于零样本VST场景,我们不使用说话者ID信息,我们仅从语音中提取风格表示。
2.2. 分层变分自动编码器 我们采用HierSpeech [18]的结构作为端到端VST系统,并用语言恢复器替换文本编码器。我们使用扰动的语言表示xw2v,pert作为条件信息c,来分层地生成波形音频。我们还使用来自原始波形的自监督表示的增强语言表示,该表示没有经过扰动。此外,在训练过程中,从线性频谱图中提取的声学表示用于重新构建原始波形音频。为了连接声学和多路径语言表示,我们采用了分层变分推理,而HierVST的优化目标可以定义如下:
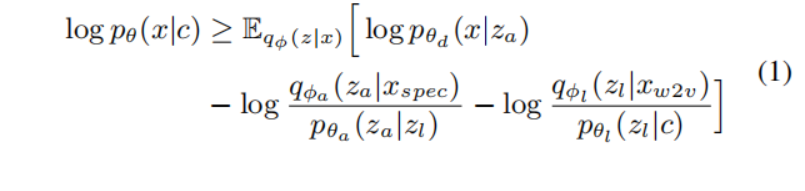

其中qϕa(za|xspec)和qϕl(zl|xw2v)分别是声学表示和语言表示的近似后验。pθl(zl|c)表示在给定条件c的情况下,语言潜在变量zl的先验分布,pθa(za|zl)表示在给定声学潜在变量za的情况下的声学先验分布,pθd(x|za)是由HAG表示的似然函数,它给出了在给定潜在变量za的情况下产生数据x的可能性。此外,我们使用归一化流来提高每个语言表示的表达能力。对于重构损失,我们使用HAG的多个重构项,如下面的子节中所述。


当我们移除多周期鉴别器(MPD)以加快训练速度时,我们观察到音频质量在感知上下降。
这句话说明了在训练过程中移除多周期鉴别器对于加快训练速度是有好处的,但是会导致生成的音频质量在主观感知上下降。多周期鉴别器是用于对抗性训练的一部分,它有助于提高音频生成的质量。移除它可能导致生成的音频在一定程度上失去了真实性和逼真性,从而感知上降低了音频质量。这也表明对于该模型来说,对抗性训练在保持音频质量方面起到了重要的作用。
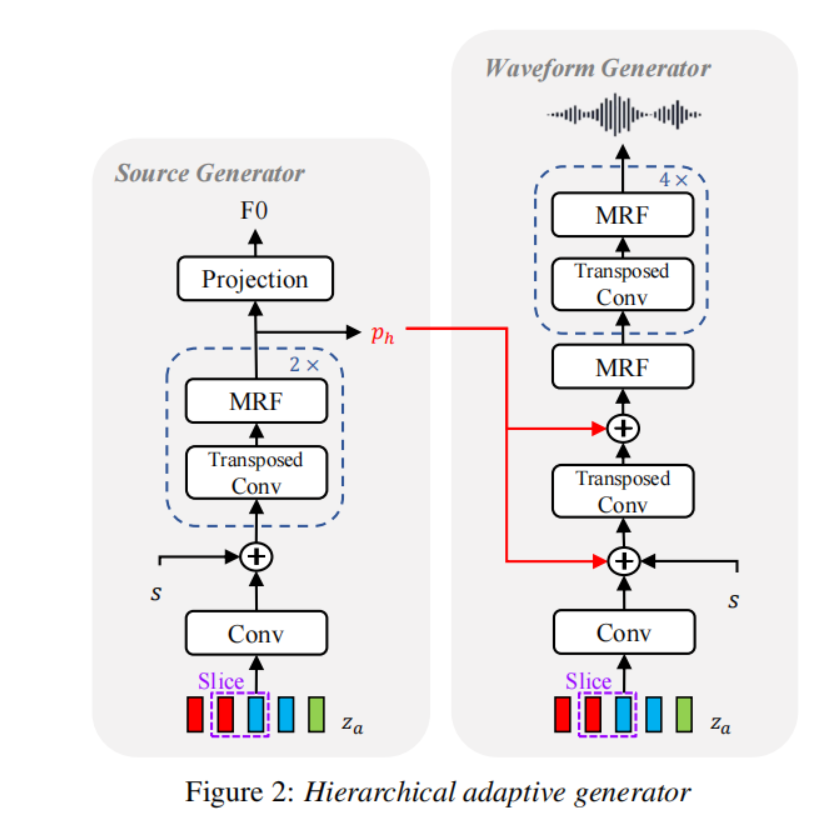
韵律蒸馏
我们引入韵律蒸馏来从语言编码器中提取增强的语言表示 <span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord"><span class="mord mathnormal">z<span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist"><span class="pstrut"><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">l<span class="vlist-s"><span class="vlist-r"><span class="vlist">。<span class="math math-inline"><span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord"><span class="mord mathnormal">z<span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist"><span class="pstrut"><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">l<span class="vlist-s"><span class="vlist-r"><span class="vlist"> 被输入到韵律解码器,该解码器生成包含韵律表示的前20个频带的Mel频谱图。与ProsoSpeech [26]不同,后者限制了韵律向量中的说话者信息,我们让 <span class="math math-inline"><span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord"><span class="mord mathnormal">z<span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist"><span class="pstrut"><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">l<span class="vlist-s"><span class="vlist-r"><span class="vlist"> 获得与说话者相关的韵律信息,以增强语言信息。我们使用韵律损失 <span class="math math-inline"><span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord"><span class="mord mathnormal">L<span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist"><span class="pstrut"><span class="sizing reset-size6 size3 mtight"><span class="mord mtight"><span class="mord text mtight"><span class="mord mtight">prosody<span class="vlist-s"><span class="vlist-r"><span class="vlist">,它最小化GT和重构Mel频谱图之间的l1距离。
简单来说,韵律蒸馏是一种用于从语音中提取韵律信息的技术。它通过生成Mel频谱图的一部分来表示语音的韵律特征,并使用重构损失来使生成的韵律表示与真实的韵律信息尽可能接近。韵律蒸馏有助于提高语言表示的表达能力,并帮助语音转换模型更好地捕捉说话者的韵律特征。
无条件生成
对于说话者适应性,我们在整个框架内使用风格表示作为条件,如在第2.1.2节中提到的。我们观察到说话者适应主要在分层自适应生成器(HAG)中进行。因此,我们在分层生成器中引入无条件生成,以增加声学表示上的说话者特征,以实现逐步的说话者适应。遵循[27]的方法,我们通过10%的概率将风格表示 <span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord mathnormal">s 替换为空说话者嵌入 <span class="math math-inline"><span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord">∅,这样我们可以将模型视为条件和无条件模型在同一个模型中。
简单来说,无条件生成是指模型在生成音频时不仅使用风格表示(即说话者信息)作为条件,还会以一定概率忽略风格表示。这样,模型可以在一些情况下不依赖于特定的说话者信息,从而增加了模型的灵活性和泛化能力。通过引入无条件生成,我们可以让模型在适应新说话者的过程中更加灵活和鲁棒。
实验和结果
3.1. 数据集与预处理
我们使用大规模多说话者数据集LibriTTS [28]来训练模型(train-clean-360和train-clean-100),该数据集包含大约300小时的音频,涵盖了1,151位说话者的语音。我们使用dev-clean子集进行验证。为了评估零样本VST任务,我们使用了VCTK数据集 [29]。对于这两个数据集,我们将音频降采样到16 kHz。对于自监督语音表示,我们将降采样后的音频输入XLS-R模型,从XLS-R的中间层提取语言相关的表示,这个表示是一个1024维的向量序列,是从16 kHz音频中降采样得到的(降采样比例为320×)。我们还利用高分辨率的F0,它是从音频中提取的F0序列(降采样比例为80×)。对于Mel频谱图,我们使用短时傅里叶变换(STFT)将音频转换为频谱图,使用320的跳步大小,1280的窗口大小,1280的FFT大小以及80个Mel滤波器的频带。
以上是实验中使用的数据集以及预处理步骤。LibriTTS数据集用于训练模型,VCTK数据集用于评估零样本VST任务。降采样和频谱图处理是为了使数据适应模型,并提取语音特征进行训练和评估。
训练 我们使用AdamW优化器 [30],并采用与 [18] 相同的设置。我们在四块NVIDIA A100 GPU上使用批大小为128进行600,000步的训练(耗时六天)。对于一次性VST,我们使用单个新说话者的样本进行1,000步的微调,并初始化相同的AdamW优化器,但使用较低的学习率(1 × 10^-4)。我们进行了消融实验,使用批大小为64,在两块A100 GPU上进行300,000步的训练。为了进行高效训练,我们将音频划分为61,440帧的段进行输入,并使用窗口生成器训练,使用额外切片的音频(9,600帧)。
3.3. 实现细节 语言恢复器(linguistic restorer)、语言编码器(linguistic encoder)和声学编码器(acoustic encoder)由16层非因果WaveNet组成,每层有192个隐藏维度。流模块包括<span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord"><span class="mord mathnormal">f<span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist"><span class="pstrut"><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">l<span class="vlist-s"><span class="vlist-r"><span class="vlist">和<span class="math math-inline"><span class="katex"><span class="katex-mathml"><span class="katex-html"><span class="base"><span class="strut"><span class="mord"><span class="mord mathnormal">f<span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist"><span class="pstrut"><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">a<span class="vlist-s"><span class="vlist-r"><span class="vlist">,由四个仿射耦合层和四层WaveNet组成。对于HAG,源生成器(source generator)由两个上采样层[2,2]和两个多接收域融合(MRF)块组成,波形生成器(waveform generator)由HiFi-GAN [6]和一个来自源生成器表示的条件层组成。我们使用上采样率[4,5,4,2,2]和初始通道数为512。鉴别器使用MPD [6]和MS-STFTD [25],其中包含五个不同大小的窗口([2048,1024,512,256,128])。我们对韵律蒸馏使用了一个浅层的前馈Transformer网络,包含两层和768个隐藏维度。对于无条件生成,我们将无条件生成比率puncond设置为0.1,我们只使用有条件生成对模型进行微调。推理阶段整个模型参数的数量为45M。
我们使用了一个官方预训练模型。然而,这个模型是使用LibriTTS、VCTK和额外的数据集进行训练的。此外,YourTTS在训练时使用了文本转录。
3https://github.com/resemble-ai/Resemblyzer
多对多VST
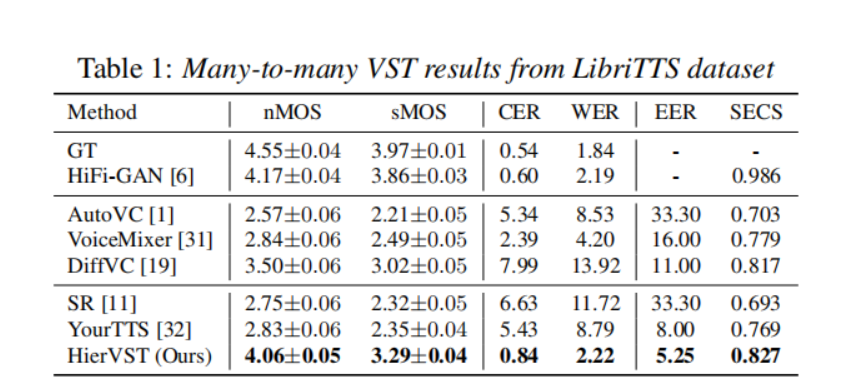
我们将我们的模型与五个基线模型进行了比较:(1) AutoVC [1],基于信息瓶颈的VC模型。(2) VoiceMixer [31],基于相似性的信息瓶颈和对抗性训练的VC模型。(3) DiffVC [19],基于扩散的VC模型。(4) Speech Resynthesis (SR) [11],使用离散语音单元的端到端模型。(5) YourTTS2 [32],基于VITS [12]的端到端语音合成模型。遵循 [18] 的方法,我们对主观评估指标进行了自然度平均意见分数(nMOS)和相似性平均意见分数(sMOS)评估。为了评估语言一致性,我们还通过Whisper大模型 [33] 计算字符错误率(CER)和词错误率(WER)。对于说话者相似性的测量,我们计算了自动语音识别模型 [34] 的等误差率(EER),以及目标和转换语音之间的说话者嵌入余弦相似度(SECS)。
表1显示,我们的模型在所有评估指标上都取得了显著的改进。具体而言,我们的模型在nMOS和sMOS方面分别提高了音频质量和说话者适应质量。此外,我们的模型在转换语音的内容信息损失方面很小,其中CER和WER远低于其他模型,即使我们的模型是在没有文本转录的情况下训练的。对于说话者相似性的客观指标也显示出我们的模型可以很好地适应目标语音风格。虽然HierVST与使用变分推断增强的标准化流 [32] 具有类似的结构,但我们的分层结构在说话者适应和音频质量方面,包括自然度和发音方面,都表现更好。
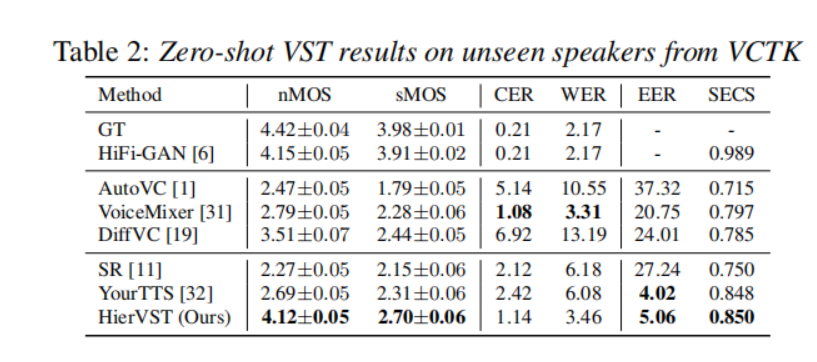
零样本VST
我们在VCTK数据集上对零样本VST的性能进行了比较。表2显示,只有我们的模型能够在EER和SECS方面适应新的说话者。值得注意的是,YourTTS是使用VCTK数据集进行训练的,因此YourTTS的VST情景并不是零样本VST。尽管如此,我们模型在零样本说话者适应方面的结果显示出EER和SECS方面的说话者适应质量与YourTTS相似。此外,我们的模型在两个主观评估指标上的表现也比其他模型要好得多,这意味着我们的模型即使在零样本VST情景下,也能够以分层自适应结构稳健地转换语音。
表3:根据微调步数的VCTK数据集上的一次性VST结果。
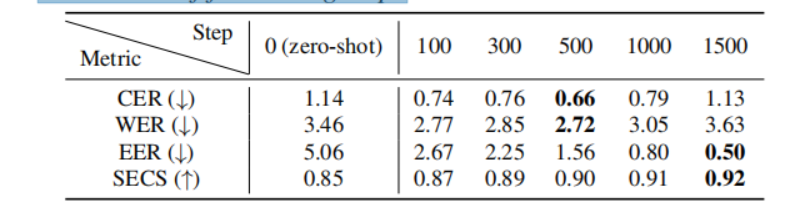
一次性VST
我们将零样本和一次性VST的性能与不同微调步数进行了比较。表3显示,用一个样本进行微调可以提高VST性能,即EER和SECS方面的说话者适应质量。然而,过度拟合到小的训练样本后,语言一致性下降,因此我们只使用1,000步来微调模型。
3.7. 消融实验
3.7.1. 分层VAE
我们采用分层VAE(HVAE)来恢复扰动的语言表示,并提高说话者适应质量。表4显示,移除HVAE会显著降低说话者适应性能。然而,我们发现分层结构需要更多的训练步骤才能实现更低的CER和WER,以获得适当的发音,即使用600k步进行训练的HierVST具有较低的CER和WER。此外,模型的自然度更好,这意味着分层结构通过使用与说话者相关的语言表示对声学表示进行正则化,减少了音频质量的退化。值得注意的是,需要扰动波形音频以去除语言表示中与说话者相关的信息,因此没有经过音频扰动训练的模型无法进行语音风格转换。
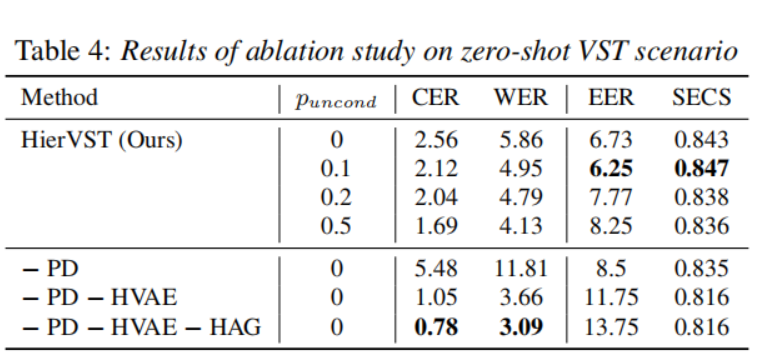
分层自适应生成器
我们通过将HiFi-GAN与源生成器结合,对其进行修改。通过对源相关表示进行蒸馏,带有分层自适应生成器的模型合成具有更好质量的音频,如表4所示,并且适应性能在EER方面也有所提高。
3.7.3. 韵律蒸馏
尽管分层VAE可以提高VST质量,但该模型的CER和WER较高。因此,我们另外引入了韵律蒸馏(PD)来增强语言表示。添加韵律蒸馏可改善所有指标的整体性能,并增强语言表示。我们还将20个Mel-spectrogram的频带与全频带的Mel-spectrogram进行了比较,使用20个Mel-spectrogram的模型在源生成器中具有较低的F0 l1距离,因此我们只使用了20个频带进行韵律蒸馏。
3.7.4. 无条件生成
我们在HAG上以不同的无条件比率训练了模型。我们发现增加无条件比率可以改善转换语音的发音。然而,比率较小的模型可以生成更好的说话者适应的转换语音。表4显示,采用适当的无条件生成比率简单地提高了模型的生成任务能力。
- 结论
我们提出了HierVST,它可以通过分层转换声音风格来转换语音。仅使用语音数据集,我们从解耦表示中恢复了语言表示,重构了增强的语言表示和丰富的声学表示,并生成了高质量的转换语音。此外,我们通过韵律蒸馏和无条件生成来提高整个模型的能力。实验结果表明,我们的模型可以生成高保真音频和高质量的说话者适应的转换语音。我们发现我们的分层自适应结构可以应用于基于单位的语音到语音翻译系统,以生成翻译语音的表现性声音风格。尽管我们的模型生成了高质量的转换语音,但我们的模型在没有转换音色的情况下具有很少的可控性。在未来的工作中,我们将利用音高和时长来直接控制语音的语调和节奏。
- Hierarchical Zero-shot 语音 Adaptive Transferhierarchical zero-shot语音adaptive zero-shot hierarchical transformer hierarchical shifted windows adaptive relational zero-shot knowledge learning autoregressive hierarchical compression learned zero-shot reasoners language models construction zero-shot knowledge prompting clustering-based hierarchical personalized recognition