
发表时间:2017(ICML 2017)
文章要点:这篇文章设计了一个叫Predictron的结构,在abstract的状态上进行学习,通过multiple planning depths来使得model self-consistent,进行端对端的学习。这里的设定是MRP,不是MDP,所以没有动作,只有状态转移。整个模型包括一个state representation,也就是encoder,一个model,用来做状态转移,以及一个value function。这里的一个想法就是,不管是1-step的planning,还是k-step的planning,他们最终学到的值都应该是一样的。就算我搞一个\(\lambda\)-return,最终的预测还是应该是一个东西。然后在学这个model的时候,就把所有的这些目标都一起学。比如只学k-step就是
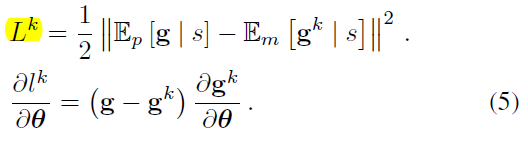
学0-K步就是
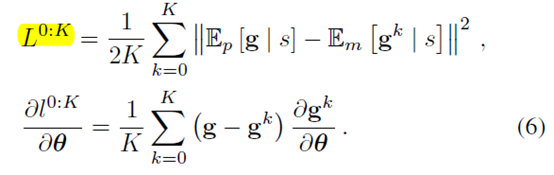
学\(\lambda\)-return就是
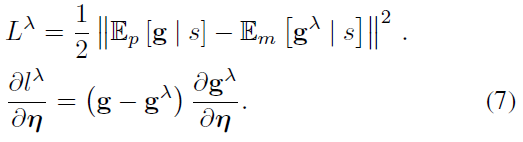
最后这些目标其实都是同一个目标,所以还可以让他们互相拟合,比如对着\(\lambda\)-return学

然后就结束了。
总结:其实这个背景设置是Markov reward process,所以没有policy,整个过程就是在学model和value。
疑问:不是很理解创新在哪,可能比较早吧。
- Predictron End-To-End End Learning Planningpredictron end-to-end end learning end-to-end transformers end-to-end end detection line end-to-end end detection extraction end-to-end generation language augmentation peripheral end-to-end end end-to-end end rfn-nest residual multi-instance entity-level end-to-end extraction audio-driven end-to-end animation end model-based learning planning scratch