摘要
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks.
知识蒸馏成为提高小型神经网络性能的事实上的标准。
Most of the previous works propose to regress the representational features from the teacher to the student in a oneto-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary.
由于架构的差异,同一空间位置的语义信息通常会有所不同。
we propose a novel one-to-all spatial matching knowledge distillation approach.
we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer.
我们允许将教师特征的每个像素提取到学生特征的所有空间位置,该相似性是由目标感知转换器生成的。
代码可在 https://github.com/sihaoevery/TaT 获取。
introduction
People discover that distilling the intermediate feature maps is a more effective approach to boost the student’s performance.This line of works encourage similar patterns to be elicited in the spatial dimensions, and is constituted as state-of-the-art knowledge distillation approach
提取中间特征图是提高学生模型性能的更有效方法,这一系列工作鼓励在空间维度中引出类似的模式,并被视为最先进的知识蒸馏方法。
To compute the distillation loss of the aforementioned approach, one need to select the source feature map from the teacher and the target feature map from the student, where these two feature maps must have the same spatial dimension.
为了计算上述方法的蒸馏损失,需要选择来自教师的源特征图和来自学生的目标特征图,其中这两个特征图必须具有相同的空间维度。如下图b所示,这种损失通常通过一对一的空间匹配风格来计算,表述为每个空间位置处源特征和目标特征之间的距离总和。【这种方法的一个基本假设是每个像素的空间信息是相同的。】在实践中,这种假设通常是无效的,因为学生模型的卷积层数通常少于教师模型。学生模型的感受野通常比教师模型的感受野小,感受野对模型表示能力的影响明显。
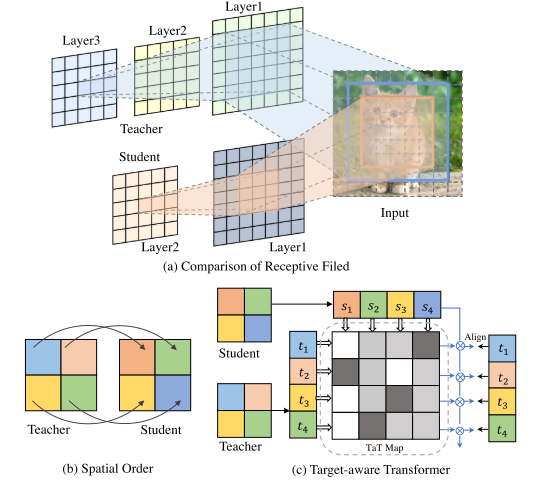
our method distills the teacher’s features at each spatial location into all components of the student features through a parametric correlation, i.e., the distillation loss is a weighted summation of all student components.
我们的方法通过参数相关性将每个空间位置的教师特征蒸馏为学生特征的所有组成部分,即蒸馏损失是所有学生组成部分的加权总和。
To model such correlation, we formulate a transformer structure that reconstructs the corresponding individual component of the student features and produces an alignment with the target teacher feature. We dubbed this target-aware transformer.
为了对这种相关性进行建模,我们制定了一个变压器结构,该结构可以重建学生特征的相应个体组件,并产生与目标教师特征的对齐。我们将这种目标感知变压器称为“目标感知变压器”。
As such, we use parametric correlations to measure the semantic distance conditioned on the representational components of student feature and teacher feature to control the intensity of feature aggregation, which address the downside of one-to-one matching knowledge distillation.
因此,我们使用参数相关性来测量以学生特征和教师特征的表示成分为条件的语义距离,以控制特征聚合的强度,这解决了一对一匹配知识蒸馏的缺点。
As our method computes the correlation between feature spatial locations, it might become intractable when feature maps are large.
当我们的方法计算特征空间位置之间的相关性时,当特征图很大时,它可能会变得棘手。
To this end, we extend our pipeline in a two-step hierarchical fashion: 1) instead of computing correlation of all spatial locations, we split the feature maps into several groups of patches, then performs the one-to-all distillation within each group; 2) we further average the features within a patch into a single vector to distill the knowledge. This reduces the complexity of our approach by order of magnitudes.
为此,我们以两步分层方式扩展我们的管道:1)我们不是计算所有空间位置的相关性,而是将特征图分成几组块,然后在每组内执行一对多蒸馏; 2)我们进一步将块中的特征平均化为单个向量以提取知识。这将我们方法的复杂性降低了几个数量级。
本文的贡献包括:
We propose the knowledge distillation via a target-aware transformer, which enables the whole student to mimic each spatial component of the teacher respectively. In this way, we can increase the matching capability and subsequently improve the knowledge distillation performance.
我们提出通过目标感知变压器进行知识蒸馏,使整个学生能够分别模仿教师的每个空间组成部分。通过这种方式,我们可以增加匹配能力,从而提高知识蒸馏性能。
We propose the hierarchical distillation to transfer local features along with global dependency instead of the original feature maps. This allows us to apply the proposed method to applications, which are suffered from heavy computational burden because of the large size of feature maps
我们提出分层蒸馏来传输局部特征以及全局依赖性,而不是原始特征图。这使我们能够将所提出的方法应用于由于特征图尺寸较大而承受沉重计算负担的应用程序
We achieve state-of-the-art performance compared against related alternatives on multiple computer vision tasks by applying our distillation framework.
通过应用我们的蒸馏框架,与多个计算机视觉任务的相关替代方案相比,我们实现了最先进的性能。
方法论
假设教师和学生模型为两个卷积神经网络,分别表示为\(T\)和\(S\),\(F^T\in \mathbb{R}^{H\times W \times C}\)和\(F^S \in \mathbb{R}^{H\times W\times C^\prime}\),其中\(H,W\)分别为特征图的高度和宽度,C表示通道数目。蒸馏损失可以通过
- Distillation Target-aware Transformer Knowledge Targetdistillation target-aware transformer knowledge target-aware understanding distillation knowledge empirical distillation relational knowledge distillation innovative knowledge landscape distillation recommender knowledge framework distillation knowledge stronger teacher distillation unsupervised adaptation knowledge distillation decoupled knowledge recommendation distillation knowledge unbiased