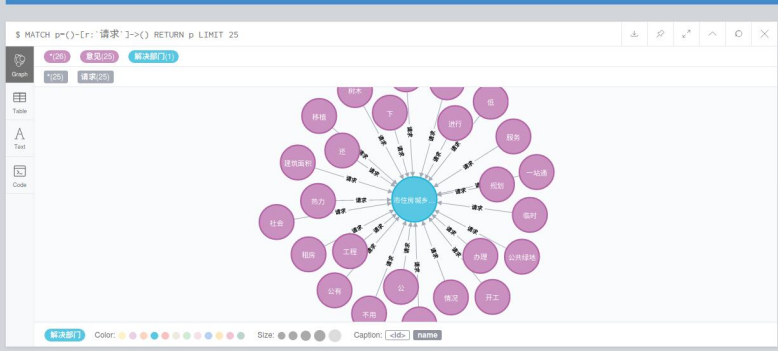
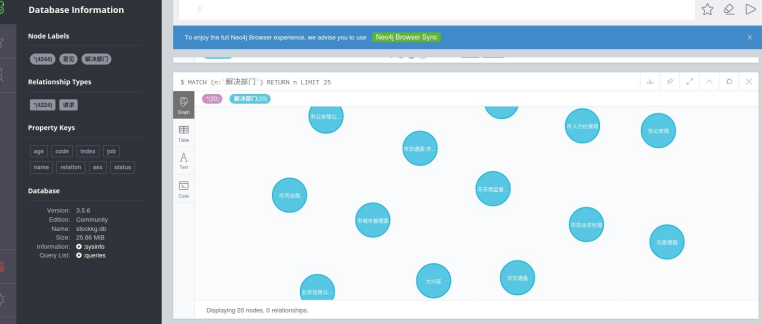
使用neo4j数据库进行存储关系的展示

热词云

import json import matplotlib.pyplot as plt import re import jieba from py2neo import Graph,Node,Relationship,NodeMatcher from wordcloud import WordCloud from collections import Counter import warnings warnings.filterwarnings('ignore') contents = [] institutions = [] # 逐行读取输入文件 with open('letter.json', 'r',encoding='utf-8') as file: for line in file: # 解析每一行为 JSON 对象 json_obj = json.loads(line) contents.append(json_obj['content']) institutions.append(json_obj['institution']) # ===================================================================== # 内容清洗 # 文本内容清洗,清楚特殊符号,用正则表达式 pattern = r"[!\"#$%&'()*+,-./:;<=>?@[\\\]^_^{|}~—!,。?、¥…():【】《》‘’“”\s]+" re_obj = re.compile(pattern) def clear(text): return re_obj.sub("",text) def cut_word(text): return jieba.lcut(text) def get_stopword(): s = set() with open('hit_stopwords.txt',encoding = 'UTF-8') as f: for line in f: s.add(line.strip()) return s def remove_stopword(words,stopword): return [word for word in words if word not in stopword] def createWorldCould(c): # 生成词云图 wordcloud = WordCloud(width=800, height=400, font_path="msyh.ttc").generate_from_frequencies(c) # 显示词云图 plt.figure(figsize=(10, 5)) plt.imshow(wordcloud, interpolation="bilinear") plt.axis("off") plt.show() def createMapping(contents,institutions): # 创建知识图谱节点 graph = Graph('http://localhost:7474', user='neo4j', password='123456') graph.delete_all() # 清除neo4j里面的所有数据 # 确保相同名称的结点被视为同一个结点 label_1 = '意见' label_2 = '解决部门' # 将每一个机构的关键词都与机构对应上 for i in range(len(institutions)): # 将一个关键词去重 keys[i] = list(set(keys[i])) # 创建索引 matcher = NodeMatcher(graph) nodelist = list(matcher.match(label_2,name=institutions[i])) # 已经有机构了 if len(nodelist)>0: # 创建关键词节点 for j in range(len(keys[i])): matcher = NodeMatcher(graph) nodelist = list(matcher.match(label_1,name=keys[i][j] )) if len(nodelist)>0: print("已经有了") else: node_1 = Node(label_1, name=keys[i][j]) graph.create(node_1) node_2 = graph.nodes.match(label_2, name=institutions[i]).first() rel = Relationship(node_1, "请求", node_2) graph.create(rel) else: # 创建机构节点 node_2 = Node(label_2, name=institutions[i]) graph.create(node_2) # 创建关键词节点 for j in range(len(keys[i])): node_1 = Node(label_1, name=keys[i][j]) graph.create(node_1) rel = Relationship(node_1,"请求",node_2) graph.create(rel) return if __name__ == '__main__': keys = contents for i in range(len(contents)): # 文本清洗 contents[i] = clear(contents[i]) # 分词 contents[i] = cut_word(contents[i]) # 除去停用词 stopword = get_stopword() contents[i] = remove_stopword(contents[i],stopword) contents = [element for sublist in contents for element in sublist] createMapping(keys,institutions) print(f'总词汇量:{len(contents)}') c = Counter(contents) print(f'不重复词汇量:{len(c)}') common = c.most_common(15) createWorldCould(c)