Flink集群安装部署
Flink支持多种安装部署方式
- Standalone
- ON YARN
- Mesos、Kubernetes、AWS…
这些安装方式我们主要讲一下standalone和on yarn。
如果是一个独立环境的话,可能会用到standalone集群模式。
在生产环境下一般还是用on yarn 这种模式比较多,因为这样可以综合利用集群资源。和我们之前讲的spark on yarn是一样的效果
这个时候我们的Hadoop集群上面既可以运行MapReduce任务,Spark任务,还可以运行Flink任务,一举三得。
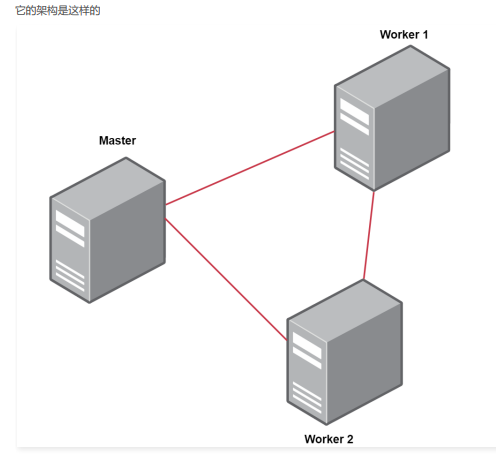
standalone
它的架构是这样的
依赖环境
jdk1.8及以上【配置JAVA_HOME环境变量】
ssh免密码登录
下载地址,这里我们使用1.11.1版本
启动Flink集群
bin/start-cluster.sh
访问Flink的web界面 http://bigdata01:8081
停止集群,
bin/stop-cluster.sh
Standalone集群核心参数
参数 解释
jobmanager.memory.process.size 主节点可用内存大小
taskmanager.memory.process.size 从节点可用内存大小
taskmanager.numberOfTaskSlots 从节点可以启动的进程数量,建议设置为从节可用的cpu数量
parallelism.default Flink任务的默认并行度
slot vs parallelism
- slot是静态的概念,是指taskmanager具有的并发执行能力
- parallelism是动态的概念,是指程序运行时实际使用的并发能力
- 设置合适的parallelism能提高程序计算效率,太多了和太少了都不好
Flink ON YARN
Flink ON YARN模式就是使用客户端的方式,直接向Hadoop集群提交任务即可。不需要单独启动Flink进程。
注意:
- Flink ON YARN 模式依赖Hadoop 2.4.1及以上版本
- Flink ON YARN支持两种使用方式
Flink ON YARN两种使用方式
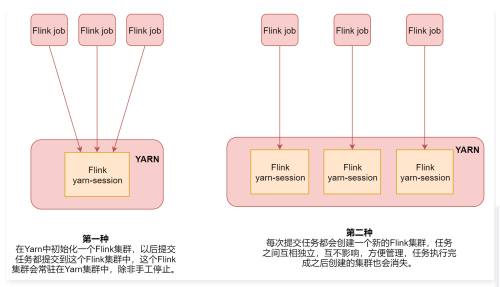
在工作中建议使用第二种方式。
Flink ON YARN第一种方式
- 第一步:在集群中初始化一个长时间运行的Flink集群 使用yarn-session.sh脚本
- 第二步:使用flink run命令向Flink集群中提交任务
注意:使用flink on yarn需要确保hadoop集群已经启动成功
接下来在执行 yarn-session.sh 脚本之前我们需要先设置 HADOOP_CLASSPATH 这个环境变量,否则,执行yarn-session.sh 是会报错的,提示找不到hadoop的一些依赖
在 ~/.bash_profile 中配置 HADOOP_CLASSPATH
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`
接下来,使用 yarn-session.s h在YARN中创建一个长时间运行的Flink集群
bin/yarn-session.sh -jm 1024m -tm 1024m -d
这个表示创建一个Flink集群, -jm 是指定主节点的内存, -tm 是指定从节点的内存, -d 是表示把这个进程放到后台去执行。
启动之后,会看到类似这样的日志信息,这里面会显示flink web界面的地址,以及这个flink集群在yarn中对应的applicationid。
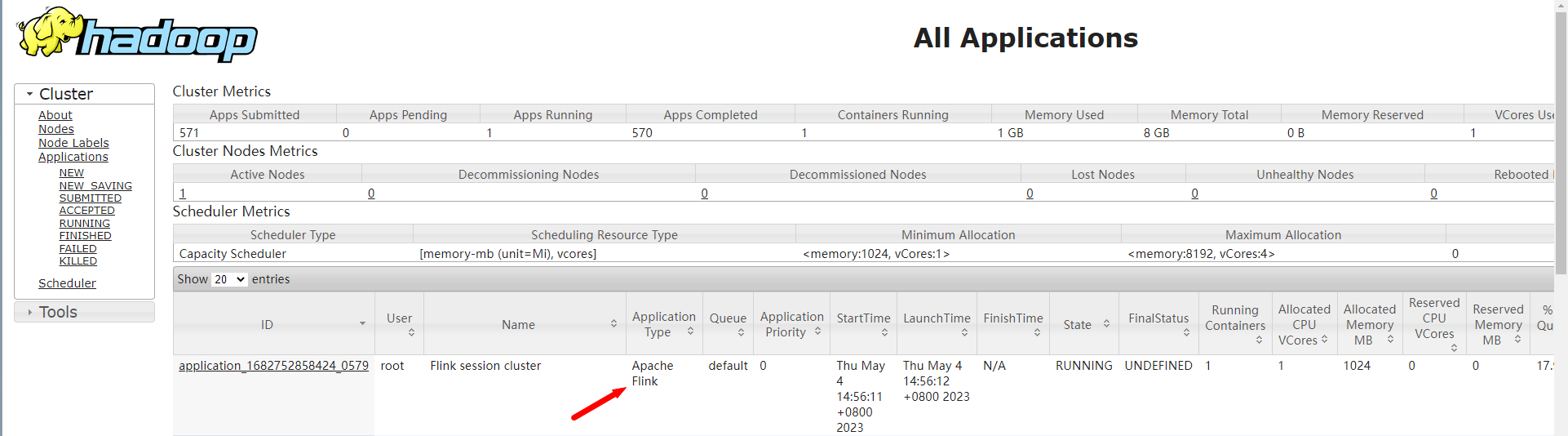
此时到YARN的web界面中确实可以看到这个flink集群。可以使用屏幕中显示的flink的web地址或者yarn中这个链接都是可以进入这个flink的web界面的
接下来向这个Flink集群中提交任务,此时使用Flink中的内置案例
bin/flink run ./examples/batch/WordCount.jar
注意:这个时候我们使用flink run的时候,它会默认找这个文件,然后根据这个文件找到刚才我们创建的那个永久的Flink集群,这个文件里面保存的就是刚才启动的那个Flink集群在YARN中对应的applicationid。
任务提交上去执行完成之后,再来看flink的web界面,发现这里面有一个已经执行结束的任务了。
注意:这个任务在执行的时候,会动态申请一些资源执行任务,任务执行完毕之后,对应的资源会自动释放掉。
最后把这个Flink集群停掉,使用yarn的kill命令
针对 yarn-session 命令,它后面还支持一些其它参数,可以在后面传一个 -help 参数

Flink ON YARN第二种方式
flink run -m yarn-cluster (创建Flink集群+提交任务)
使用flink run直接创建一个临时的Flink集群,并且提交任务
此时这里面的参数前面加上了一个 y 参数
Flink ON YARN的好处
- 提高大数据集群机器的利用率
- 一套集群,可以执行MR任务,Spark任务,Flink任务等
查看历史任务的执行信息
咱们之前在学习spark的时候其实也遇到过这种问题,当时是通过启动spark的historyserver进程解决的。
flink也有historyserver进程,也是可以解决这个问题的。
在启动historyserver进程之前,需要先修改flink-conf.yaml配置文件
jobmanager.archive.fs.dir: hdfs://bigdata01:9000/completed-jobs/
historyserver.web.address: 120.48.109.142
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9000/completed-jobs/
historyserver.archive.fs.refresh-interval: 10000
然后启动flink的historyserver进程
bin/historyserver.sh start
注意:hadoop集群中的historyserver进程也需要启动
运行出错
执行bin/flink run出错
Caused by: java.lang.Error: Failed to find GC Cleaner among available providers: [Legacy (before Java 9) cleaner provider, New Java 9+ cleaner provider]
at org.apache.flink.util.JavaGcCleanerWrapper.findGcCleanerManager(JavaGcCleanerWrapper.java:149)
at org.apache.flink.util.JavaGcCleanerWrapper.<clinit>(JavaGcCleanerWrapper.java:56)
at org.apache.flink.core.memory.MemoryUtils.createMemoryGcCleaner(MemoryUtils.java:111)
at org.apache.flink.core.memory.MemorySegmentFactory.allocateOffHeapUnsafeMemory(MemorySegmentFactory.java:175)
at org.apache.flink.runtime.memory.MemoryManager.lambda$allocatePages$0(MemoryManager.java:237)
at org.apache.flink.runtime.memory.MemoryManager$$Lambda$534/70727321.apply(Unknown Source)
at java.util.concurrent.ConcurrentHashMap.compute(ConcurrentHashMap.java:1853)
at org.apache.flink.runtime.memory.MemoryManager.allocatePages(MemoryManager.java:233)
at org.apache.flink.runtime.memory.MemoryManager.allocatePages(MemoryManager.java:192)
at org.apache.flink.runtime.operators.chaining.SynchronousChainedCombineDriver.openTask(SynchronousChainedCombineDriver.java:115)
at org.apache.flink.runtime.operators.BatchTask.openChainedTasks(BatchTask.java:1392)
at org.apache.flink.runtime.operators.DataSourceTask.invoke(DataSourceTask.java:157)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:721)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:546)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.flink.util.FlinkRuntimeException: Legacy (before Java 9) cleaner provider: Failed to find Reference#tryHandlePending method
需要依赖jdk11,修改conf/flink-conf.yaml
env.java.home: /root/test_jdk/jdk11
修改了还是报错,暂时还不管它了。