AlexNet
? 研究主题
提出使用GPU进行模型训练
采用比LeNet更深的卷积层搭建模型
采用更大数据集ImageNet防止过拟合
✨创新点:
采用ReLU激活函数对每个卷积层进行处理
- 加快梯度下降训练时间;
- Linear rectification function:f(x) = max(0, x)
“In terms of training time with gradient descent, these saturating nonlinearities are much slower than the non-saturating nonlinearity f (x) = max(0, x).” (Krizhevsky 等, 2012, p. 3) ?就梯度下降的训练时间而言,这些饱和非线性比非饱和非线性 f (x) = max(0, x) 慢得多。?
采用多块GPU进行训练
重叠池化
- 一般池化(平均池化、最大池化、随机池化等)只作用于不重叠的领域,此时步长s=窗口大小z;
- 重叠池化:相比于正常池化,重叠池化(步长s=2,窗口z=3) 降低了误差率;
? 设计与实现
整体结构:
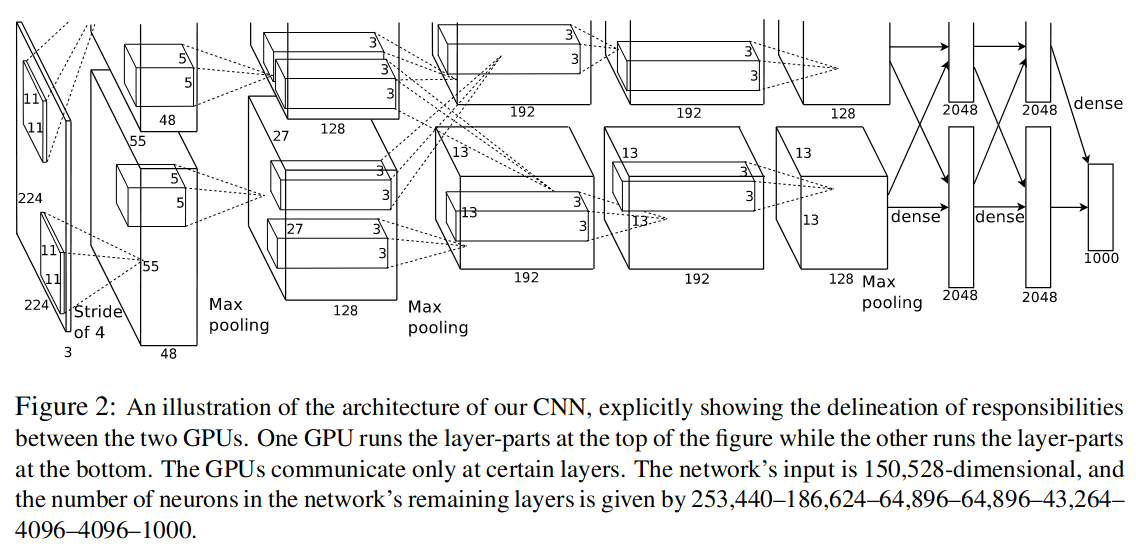
- 最后的FC层与Softmax层连接;
- LRN位于第1、2层Conv后;
- MaxPooling(重叠最大池化)位于LRN与第5个Conv后;
- Relu位于每个Conv与FC后;
- 输入图像大小为224x224x3;
- 前2个FC层使用Dropout,防止过拟合;
训练设置:
- 采用SGD,batch=128,动量=0.9,衰减=0.0005;
- 采用标准差为0.01的零均值高斯分布初始化每层;
- 学习率初始化为0.01,当不在提高时rate/10,重复3次;
? 训练技巧
数据增强
- 图像平移和水平映射,通过从256x256大小图像中随机提取224x224大小图像进行训练,从而防止过拟合
- 采用PCA色彩增强,改变RGB通道强度
“At test time, the network makes a prediction by extracting five 224 × 224 patches (the four corner patches and the center patch) as well as their horizontal reflections (hence ten patches in all), and averaging the predictions made by the network’s softmax layer on the ten patches.” (Krizhevsky 等, 2012, p. 5) 在测试时,网络通过提取五个 224 × 224 补丁(四个角补丁和中心补丁)及其水平反射(因此总共十个补丁)来进行预测,并对网络的 softmax 层做出的预测进行平均在十个补丁上。
采用Dropout
“The recently-introduced technique, called “dropout” [10], consists of setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in backpropagation.” (Krizhevsky 等, 2012, p. 6) 最近推出的技术称为“dropout”[10],包括以 0.5 的概率将每个隐藏神经元的输出设置为零。以这种方式“丢弃”的神经元不会对前向传播做出贡献,也不参与反向传播。
“At test time, we use all the neurons but multiply their outputs by 0.5, which is a reasonable approximation to taking the geometric mean of the predictive distributions produced by the exponentially-many dropout networks.” (Krizhevsky 等, 2012, p. 6) 在测试时,我们使用所有神经元,但将它们的输出乘以 0.5,这是采用指数多丢失网络产生的预测分布的几何平均值的合理近似值。
Referred in 图像分类网络