误差分析 Error Analysis
如果你的机器学习算法表现得还不够好,那么通过手工去检查算法所犯的错误,这个过程称为错误分析(Error Analysis)。
举例如下,团队开发的识别猫咪的分类器,在dev set上准确率为90%。此时我们希望提升算法的性能,通过分析算法的错误样本,发现其中有一些狗的图片被识别为了猫咪,那么是否需要针对狗的图片进行专门的优化呢?也许对狗这方面进行算法优化会需要很多时间,是否有价值去做这件事儿?
此时我们需要做Error Analysis,再决定如何优化。
统计100个识别错误的样例,计算其中为狗的图片占比多少。如果其中只有5错误样本为狗,那么我们在这方面优化算法,最多也只是将错误率从10%降低到9.5%,显然这样做的成本比较高效果比较差。如果有50%为狗图,那我们再去做优化,就可以把错误率下降5%,这样才更有价值。
因此,对算法进行调整前,最好进行错误分析,然后再决定算法优化的方向。
具体做法也很简单,通过建立表格,统计分析产生错误的原因的占比,从结果来判断比较好的优化方向。总之,通过统计不同错误类型占总数的百分比,可以帮助发现那些问题需要解决,或者给你构思新优化方向的灵感。
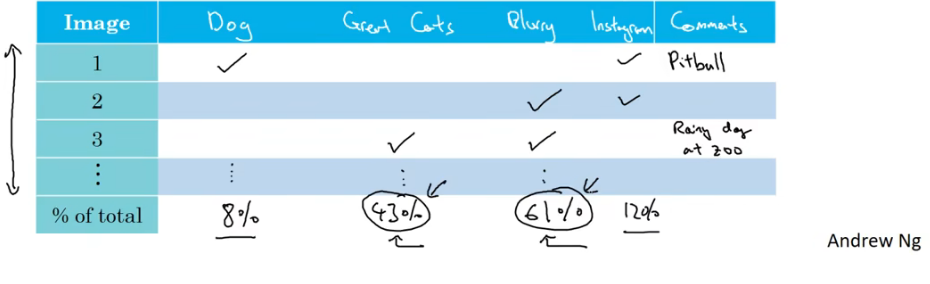
清除标注错误的数据
在数据集里可能有标注错误的,比如误将狗标记成了猫,这样是否会对我们的算法产生影响?又该怎么处理这些错误的标注呢?
对于训练集中的错误标注
- 如果在训练集中出现了一些随机的错误(标注员没注意弄错了),其实这对算法产生的影响并不大,尤其是在有大量数据的情况下。深度学习的算法对于训练集中的随机误差(random erros)是非常健壮的(robust,看弹幕还有说应该翻译成鲁棒的,很怪)。
- 产生的error是随机误差,那就大可不必担心,不用去修正。如果产生的错误是系统性的错误(systematic errors),比如总是将白色的狗标记成猫,这就对算法的学习结果产生了一ing想,需要进行清除。
对于dev/test sets中的错误标注
-
此时我们可以利用上文中提到的误差分析的方法,去权衡错误标注。在误差分析的表格中添加一行“Incorrected labeled”分析因为错误标注引发error的比例。
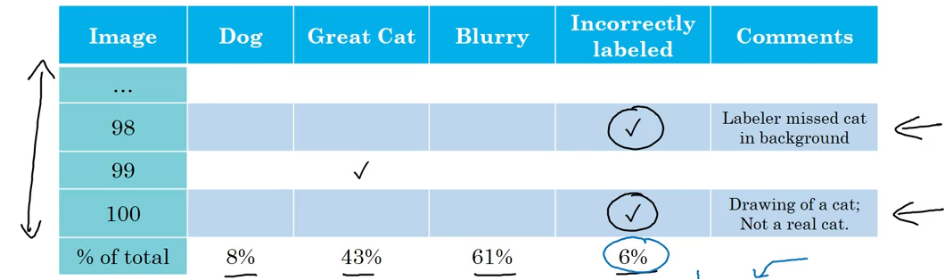
-
与表格中其他选项比较,如果影响比较大,就优化这个问题,否则可以不考虑这个问题(不是首要问题呢)。或者说这个选项影响到了判断两个算法谁更好这块,也需要去清除错误标注。
-
修正dev/test sets中错误样本的指导原则
- 对dev和test集合使用相同的处理方案,保证他们始终来自于相同的分布。
- 检查算法预测正确的样本中,是否存在错误标注和错误预测同时出现的情况(比如一个图片不是猫,但dev/test集被人员错误标注为了猫,同时算法也预测这个样本为猫)。这一部分数据其实就表明算法预测的正确率其实没那么高。一般被可以进行这项操作,成本比较高,并且正确预测的样本肯定比错误预测的样本多得多。
- 针对dev/test set的修正,会导致其与training set分布略有不同,但问题不大。
老师建议,在构建系统时,通常需要更多的人工错误分析和加入人类的见解来构造系统。亲自去查看错误样本,统计数量,找到需要优先处理的问题。
快速搭建第一个系统,并进行迭代
机器学习的程序可能会有很多方向可以前进,并且每个方向都是相对合理的,可以改善系统。如果想搭建一个全新的机器学习程序,要做的就是快速搭好第一个系统,然后开始迭代。
快速的设立dev/test sets 和评估指标,这样就设定好了目标,即使目标错了后面也可以改。然后构建初始版本,在dev/test sets 评估算法的表现,是使用bias/variance分析、误差分析来决定下一步的优化方向。
使用来自不同分布的数据,进行训练和测试
在实践中,train sets 和 dev/test sets可能来自不同的分布。
这是因为没有那么多需要程序最终去处理的数据样本,所以我们需要通过其他方式获得的数据来填充训练集。通过下面两个例子来说明在实践中如何分配train、dev/test sets。
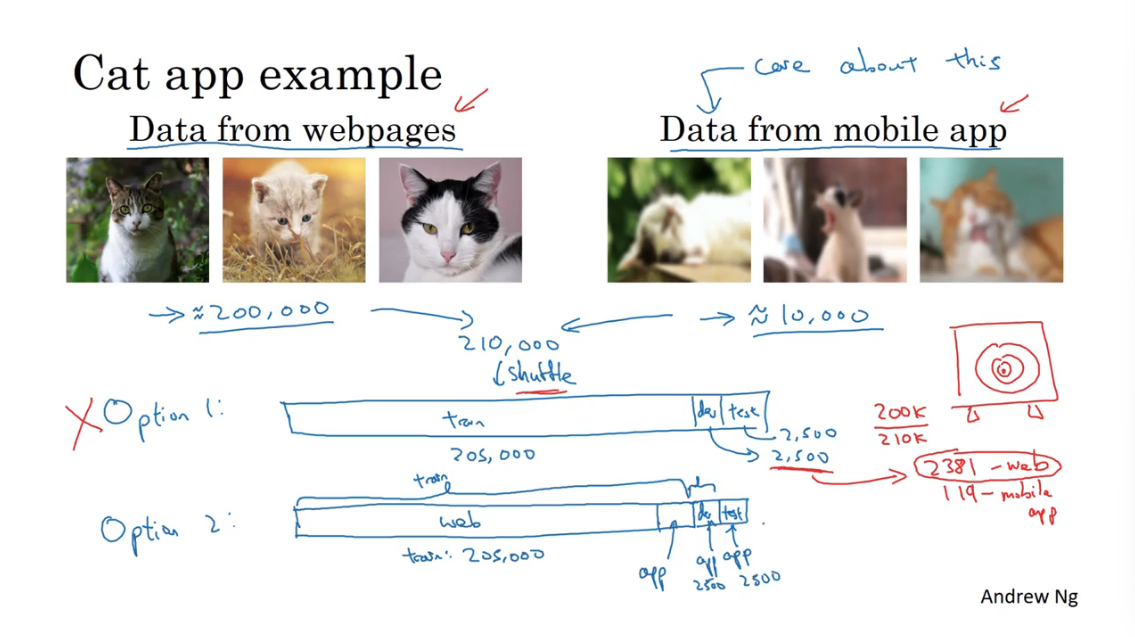
这个猫咪识别程序,最终程序需要处理的数据是来自用户上传的不清晰的图像。这种不清晰的图像样本有1万张。此外还有从网络上爬取清晰的专业的猫咪图片20万张。
所以比较好的分配方案是把来自用户的1万张图片,其中5000张分给train set,另外5000张均分为dev/test set。这样做的好处是,首先保证了dev/test来自相同的分布,其次dev/test set都是算法需要处理的真实的目标,最后train set也有这些模糊的样本。虽然trian set和dev/test set的分布不同,但是实践表明这样做在长期能带来更好的系统性能。
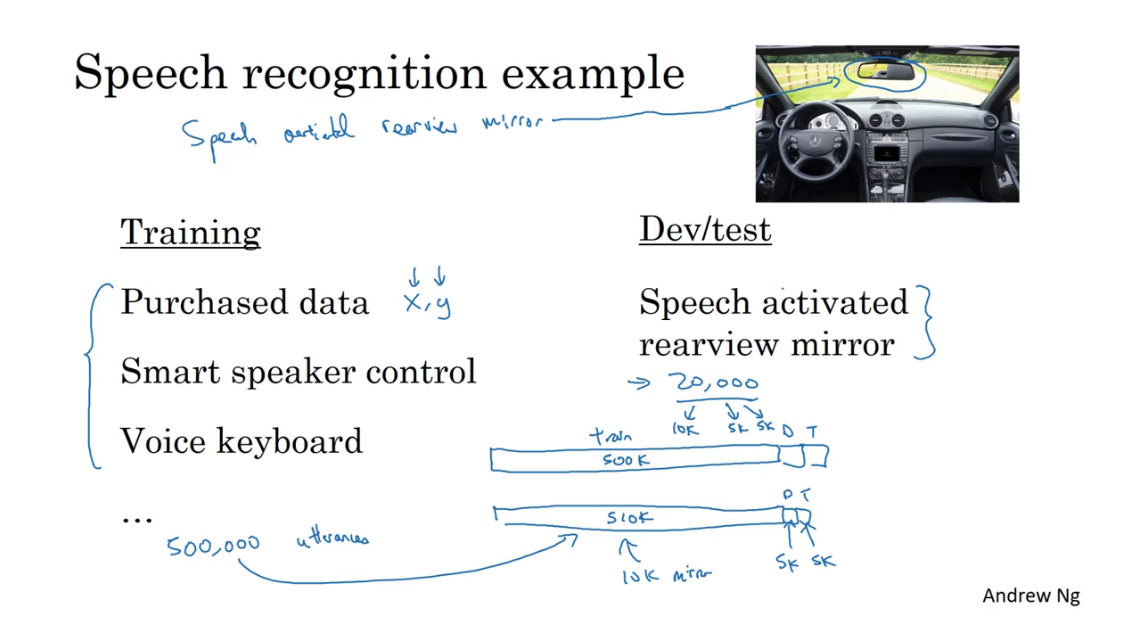
对于这个汽车后视镜语音系统也是一样的。
总结来说,不论数据来自哪里,dev/test set最好都来自于实际的应用场景中的数据。
数据不匹配时,偏差与方差的分析
前面学习过了在train set和dev/test set来自相同数据分布时的方差、偏差分析。如果这两个集合的数据来自不同的分布该如何对结果进行分析呢?
还是以猫咪分类器为例子,其中人类水平error粗略设置为0%,此时train error = 1%,而 dev error=10%,在训练集和开发集来自相同的分布,我们可以得知,这里的方差比较大。但如果训练集和开发集来自不同的分布,不能简单地推荐出方差比较大结论。此时还需要考虑数据不匹配的问题。
data mismatch(数据不匹配):算法擅长处理的数据分布和你关心的数据分布不一致。
此时我们需要把训练集中的一部分数据取出来,设置为training-dev set。train set和training-dev set具有相同的分布。
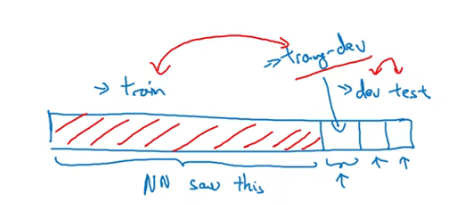
那么此时又得到了一个新的误差training-dev error,training-dev error和dev error之间的差距就反映了数据不匹配。
还是上面猫咪分类器的例子,train error =1%,training-dev error=9%,dev error =10%,那么根据这样的记过技能得出这里存在方差大的问题。又如果train error =1%,training-dev error=1.5%,dev error =10%,那么这里就存在数据不匹配的问题。
那么可以得到下图这样的关系(还加入了test error):

| 一般语音识别任务中得到的数据 | 来自实际车辆后视镜的语音数据 | |
|---|---|---|
| 人类表现 | 4% | 6% |
| 在训练过的样本上的error | train error=7% | 6% |
| 在没有训练过样本上的error | training-dev error =10% | dev/test error =6% |
上表是识别车辆后视镜语音算法中不同数据error情况,我们可以得出结果,算法在车辆后视镜语音的识别水平已经达到了人类水平,所以数据集的分布已经不错了。
通过上表的分析不一定能指明优化的方向,但是可以洞察到一些特征,比如后视镜的语音数据实际上比一般的语音数据更难识别,以及偏差、方差和数据不匹配问题的程度。
我们学习如何处理偏差和方差的手段,那么该如何处理数据不匹配的问题呢? 特别是训练集和开发集来自不同的分布。实际上没有很通用方法或者说没有系统的去解决数据不匹配的方法。
解决数据不匹配的问题
数据不匹配是由于数据分布不一致引起的,所以要解决这一问题最好是找到,训练集的数据和开发集的数据到底哪里差距比较大,然后想办法解决这一差距。
在车辆后视镜语音识别,比如通过对训练集和开发集的分析,我们发现开发集的数据有比较大的车辆噪音,而训练集的数据比较清晰,那么这里的解决方案可以是将车辆的噪音和训练集的数据通过处理结合在一起,然后再去训练可能在一定程度上解决数据不匹配的问题。或者说我们发现开发集中有大量的街道名称而训练集中没有,那可以通过收集更多的街道语音数据作为训练集。
在进行人工处理数据的时候要注意,避免算法对我们处理方案过拟合。比如,在将车辆噪音结合到训练集的时候,只用了1小时的噪音与十万小时的训练集数据结合那就可能导致算法对这一小时的噪音产生比较高的拟合。
总之,当你认为存在数据不匹配的问题,建议先做误差分析或者看看训练集和开发集,试图了解这两个数据的分布到底有什么不同,然后看看是否可以收集到更到像开发集的数据来训练,其中一种方法是人工合成数据,但要注意算法对人工处理过拟合的情况。
迁移学习
迁移学习(Transform Learning)是指将在一个已学习的神经网络结构应用到另外一个任务上。这也是深度学习最强大的思想之一。
举个例子,可以将猫咪识别的模型迁移到X光片疾病的检测。
对于猫咪识别,输入图片,输出1为猫咪,0为没有猫咪
对于X光片疾病监测,输入图片,输出1为有疾病,0为没有疾病
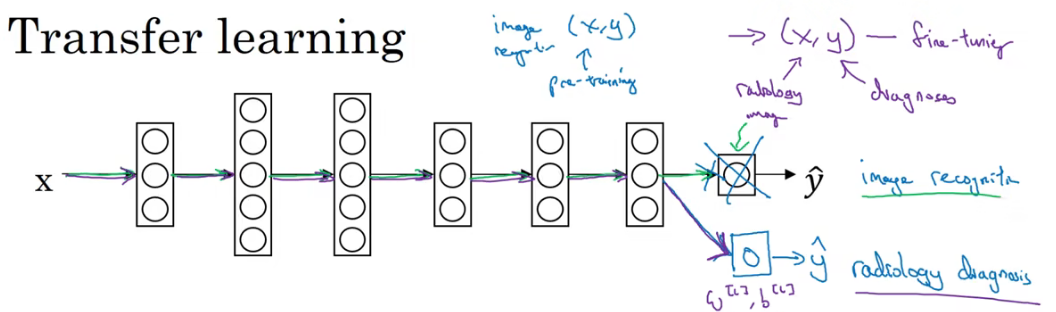
把已经学习好的猫咪识别神经网络迁移到X片疾病监测,你可以进行的操作是,把作为最后一层的输出层和输入到最后一层的权重删掉,并给最后一层赋予随机的权重(对W[l],b[l]n进行随机初始化),然后把X光片数据输入到神经网络中重新训练。
如果X光片的数比较少,可以之训练最后一层的参数或最后两层的参数;如果X光片的数据比较多也可以训练神经网络中全部层。
如果重新训练整个神经网络中所有参数,那么迁移前的训练也称为预训练(pre-training),因为使用图像识别数据去预训练或者预初始化神经网络中的参数,而不是随机初始化。
如果只用数据重新训练后一层或者后两层的参数,这个过程也叫做微调。
为什么把图像识别中中的模型迁移到X光片诊断上有效果呢?
在很多底层次特征,比如边缘检测、曲线检测、阳性对象检测(positive objects),模型从非常大的图像识别数据库中学到了很多有用的结构信息,图像形状的信息、点线面这些知识,这些可以帮助X光片诊断模型学习的更快一些,或者说需要更少的学习数据。
迁移学习应该应用于什么场景下呢?
- 任务A和B都有相同的输入,比如都是音频或者图像等。
- 任务A拥有远多于B的数据量。(可能B没那么多数据)
- 任务A的底层特征能帮助任务B学习,那么迁移学习的就更有意义。
迁移学习最有用的场合是,你需要尝试优化任务B的性能,但B的数据相对较少。此时可以找一些相关但不同的任务,并从中学到很多底层特征,来帮助B做得更好。
多任务学习Multi-task learning
Transfer learning 是一个串行学习的过程,在学习完A之后再迁移到B上面。而多任务学习是并行学习的,使用一个神经网络的同时学习多个任务目标。
例如在无人驾驶中,需要识别多个物体:行人、车辆、路标、红绿灯等。当然可以训练多个神经网络来达到识别多个和目标的目的。但是在这种情况下,一个神经网络同时训练多个任务的性能要更好。因为这些并行训练的任务,在浅层网络具有共性的底层特征。从原理上来看,与迁移学习是相似的。
此外,多任务学习也可以处理图像只有部分任务被标记的情况。
比如有的图片有人,但是没有加人的标签,还有一些是问号,但是没关系,算法依然可以在上面进行训练(求和的时候会忽略问号)
多任务学习的应用场景:
- 并行的任务拥有共同的底层特征,比如在识别图片中的行人、汽车和红绿灯。
- 并行训练的每一项任务的数据量要求基本一样。每一项人任务都会受益于其他所有任务的学习结果。而且其他任务的数据量之和要远大于单独的一项数据。
- 最训练足够大的神经网络,这样才能在多任务学习上取得比较好效果。
总结:在实践中,使用比较多的是迁移学习,但是无论是迁移学习还是多任务学习都是有力的工具。在计算机视觉领域多任务学习用得比较多。
什么是端到端得深度学习
以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。它需要很多的数据来训练,才可能有好的效果。
End-to-end deep learning对传统的deep learning有一定的挑战,传统的deep learning中的中间步骤非常重要,对此有很多研究人员做了很多研究工作,比如特征工程(engineering feature).


但End-to-end deep learning的一个重要挑战是,必须有大量的数据,才能表现出好的性能。当数据量小的时候,传统的pipeline会表现的更好。但当数据量足够大,而且neural network足够复杂,End-to-end deep learning要好于传统的pipeline。
如果数据量中等,折中的End-to-end deep learning,可以只跳过pipeline中的一部分,比如例子中跳过extract features:
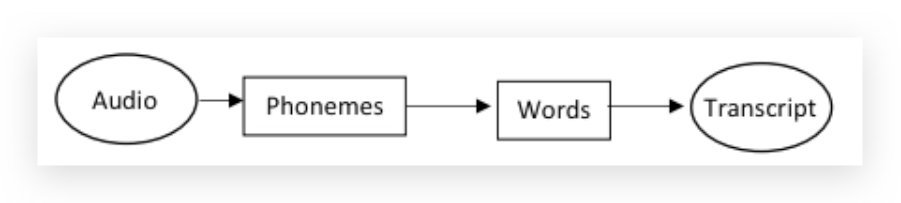
人脸识别,你可以让你的算法直接学习图像x到人物身份y的函数映射,但这并不是一个好方法。因为人可能从不同角度接近门禁,所以不会把原始照片喂给算法去识别身份。
比较好的做法是一个多步做法,先找到人脸的位置,然后放大图片进行比对。(因为没有做够多的数据去解决端到端学习的问题,但是有够多的数据去解决两个子问题。)
总结: end-to-end learning的优点:可以简化构建过程,省去了构建很多手工设计的组件的过程,而且可以捕捉到比人类认知更丰富的信息。缺点是需要大量的数据,因此并不是对所有场景都适合。 目前比较适合场景有:音频转文字、图像捕捉、图像合成、机器翻译等。
是否要应用到端到端的深度学习
要不要应用end-to-end deep learning的关键原则是:是否有足够的数据学习一个复杂的函数映射X到Y。(还要考虑你机器的性能)
优点:
- 让数据说话。纯粹的机器学习过程,让neural network找到数据里隐含的统计信息,而不是被强迫使用人为的先入为主的偏见。
- 更少的手工设计组件(less hand-designing of components),简化设计流程。
缺点:
- 需要大量的标记数据。
- 摒弃了可能很有用的手工设计组件。learning algorithm的知识两大来源:1. Data 2. hand-design。如果数据量较小,hand-desgin是注入人类知识到算法的途径之一。
老师认为:纯粹的端到端深度学习方法,前景不如更复杂的多步方法(比如人脸识别,人脸每次的位置是变化的,先识别出有人脸,然后把人脸区域截取出来,再对其进行预测,分步进行)。因为目前能收集到的数据,还有我们现在训练神经网络的能力是有局限的