偏差-方差困境(the bias-variance trade-off)
举个例子
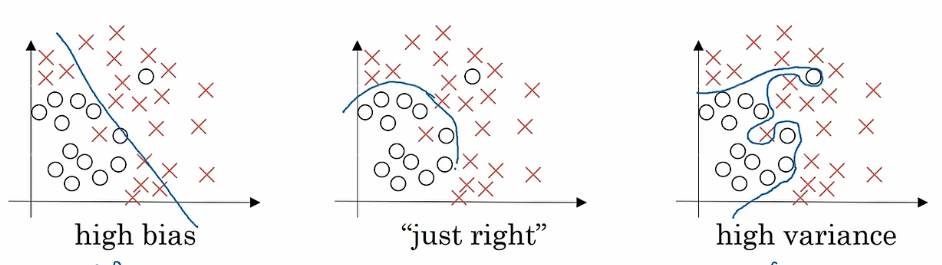
左边这个如果用单层神经网络,逻辑回归的话,就是这样一条直线,没有很好的将数据集分类,我们把这种情况称为欠拟合(underfitting)高偏差
中间这个不那么复杂但是能正确分类的算法,对数据进行了合理的处理,正正好好
右边这个可能使用了一种强大的多元神经网络,达到了这种特别好的区分效果,我们把这种情况称为过拟合(overfitting) 高方差
再举个例子,比如说我们通过一个算法能够识别图片是不是猫
以下对bias和varience的判断都是基于人的出错率是0%(这个东西我们称之为理想误差Optimal Error)
Train set error:1%#在训练集中,识别猫出错的概率是1%
Dev set error: 11%#在开发集中,识别猫出错的概率是11%
造成这种11%出错率的原因可能是在处理训练集的时候过拟合了,也就是训练集具有高方差。
模型可能会在训练集中记住了训练集中数据的某些特殊特征而不是学习到了普遍的分辨猫的特征,这就造成了模型在开发集这种未见过的数据中的表现不好。
这种情况就是high variance
---------------------------------------
Train set error: 15%
Dev set error: 16%
这种情况可以得到:这个模型如果应用上了去处理审核图片是否是猫,那么出错率认为是15.5%。
那么这种工作交给人工去做,出错率基本上是0%,这个模型就属于欠拟合了。
我们说这种情况是high bias
---------------------------------------
Train set error: 15%
Dev set error: 30%
high variance&&high bias
-------------------------------------
Train set error: 0.5%
Dev set error: 1%
low variance&&low bias
--------------------------------------
在下一章,会教给我一种方法----机器学习的基本准则