1. Abstract
经过预训练的语言模型(PLM)表现出在通用领域理解文本的出色能力,同时在特定领域中表现不佳。尽管在大型领域特定语料库上继续预训练是有效的,但调整领域上的所有参数是昂贵的。在本文中,我们研究了是否可以通过只调整几个参数来有效地调整PLM。具体来说,我们将Transformer架构的前馈网络(FFN)解耦为两部分:原始的预训练FFN以维护旧的领域知识,以及我们的新的领域特定适配器以并行注入领域特定知识。然后,我们采用混合适配器门来动态融合来自不同域适配器的知识。
2. Introduction
预训练语言模型(PLM)在自然语言理解中取得了大量成功的应用(Devlin et al,2018;刘等人,2019;何等人,2021b)和生成(Lewis et al,2019;张等人,2020;杨等人,2020年;Brown等人,2020)。领域适应的主要方法是对标记的领域特定数据或对未标记的领域特定数据的持续预训练(Gururangan等人,2020)。尽管有效,但微调和持续的预培训方法都需要调整PLM的所有参数,这增加了许多机构无法承受的高昂成本。为了缓解这种情况,提出了多参数有效微调(PEFT)方法,包括基于提示的调整(Gao et al,2021;刘等人,2021b;Schick和Schütze,2021;李和梁,2021;Liu等人,2021a),以及基于适配器的调整(Houlsby等人,2019;Pfeiffer等人,2020b;Hu等人,2021)。然而,他们更关心任务适应,目前尚不清楚如何定期、廉价地将领域知识注入不同领域特定任务的PLM中。此外,使用PEFT方法在特定领域语料库上直接调整PLM将导致灾难性的遗忘问题(Y ogatama等人,2019;Gururangan等人,2020)。这些局限性突出了一个重要的研究问题:how to adapt PLMs with the new domain knowledge while keeping the old-domain knowledge unmodified?
受最近研究(Geva等人,2021;Cao等人,2021年;Meng等人,2022)的启发,发现知识存储在前馈网络中,我们将前馈网络解耦为两部分:原始的预训练的前馈网络以保持旧的领域知识,以及我们的新的领域特定适配器以并行注入领域特定知识。具体来说,我们提出了混合域适配器(MixDA),这是几个域适配器的混合,用于在不影响旧域知识的情况下注入特定于域的知识。我们的模型有两个阶段:针对未标记数据的领域特定调整多个知识适配器,然后针对标记数据的任务特定调整适配器。在第一阶段,我们在保持原始前馈网络不变的情况下,同时在特定领域语料库和预训练语料库上训练几个领域适配器。在第二阶段,我们训练一个混合适配器gate,以动态选择所需的知识适配器和用于任务自适应的任务特定适配器。
我们在广泛的任务上进行了实验,包括4个域外数据集、9个域内数据集和2个知识密集型数据集。我们的实验结果证明了MixDA在生物医学、计算机科学出版物、新闻和评论等15个数据集上的有效性。进一步的分析显示了我们提出的方法的三个关键特性:可靠性:它在域内和域外任务上都表现出优异的性能。可扩展性:它可以很好地扩展到不断增加的域数量。效率:它只为每个域添加少量参数。我们声称,这些属性有助于将语言模型作为一种服务,其中提供冻结的PLM,并插入多个适配器来支持不同的定制服务。
3. Related Work
在本节中,我们将回顾与将领域知识注入预训练语言模型相关的四条研究路线:知识注入、领域自适应、参数有效微调和适配器混合。
knowledge injection, domain adaptation, parameter-efficient fine-tuning, and mixture-of-adapters.
3.1 Knowledge Injection
知识可以通过预训练或微调注入到PLM中,每一个都对应于一个单独的研究方向。在预训练过程中,知识图(Zhang et al.,2019;何等人,2020)、实体(Sun et al.,2019Xiong et al.,2020),n-gram(Diao et al.,2020),知识嵌入(Wang et al.,2021 b),WordNet中的同义词和同义词-超名关系,知识库(Peters等人,2019)可以通过提供知识输入和设计新目标来注入PLM。然而,基于预训练的方法成本高昂,使得无法应用于大型PLM(例如,具有1750亿个参数的模型)。基于微调的方法只需要额外的微调过程。一些研究将额外的信息注入到输入句子中,如知识图中的知识三元组(Liu et al,2020)和知识上下文(Faldu et al.,2021),而其他研究则探索了特定的模型和训练设计,如知识适配器网络(Wang et al,2021a)、图卷积网络和LSTM(Lin et al,2019)以及元学习(Sinitsin et al.,2020)。朱等人(2020)通过添加对未修改事实损失的约束,将知识注入公式化为一个约束优化问题。最近的研究(Geva等人,2021;Cao等人,2021年;Meng等人,2022)表明,知识存储在PLM的前馈网络中。受这些研究的启发,我们提出了一种新的高效调谐方法,以最小的成本将领域知识注入前馈网络。
3.2 Domain Adaptation
领域适应性先前的研究观察到,在领域转换过程中,语言模型的性能会显著下降(Beltagy等人,2019;Alsentzer等人,2019年;Huang等人,2019,Lee等人,2020;Ke等人,2022b)。介绍了可以弥合领域差距的有效策略。从头开始的预训练语言模型是有效的,但成本高昂,如SciBERT(Beltagy等人,2019)、BioBERT(Lee等人,2020)和ClinicalBERT(Alsentzer等人,2019年)。最近的研究探索了持续预训练(Gururangan等人,2020)和适配器网络(Diao等人,2021),通过对未标记的下游任务数据进行训练来节省时间。在本文中,我们介绍了用于领域自适应的插入式领域适配器,由于其明确的学习策略和高效的模型架构,这些适配器是有效的,可以缓解灾难性遗忘问题。
3.3 Parameter-Efficient Fine-tuning
另一个相关的研究方向是参数有效微调(PEFT),它只对少量参数进行微调。现有的工作从两个角度解决了这个问题:基于提示的调谐(Gao等人,2021;刘等人,2021b;Schick和Schütze,2021;李和梁,2021;Liu等人,2021a)和基于适配器的调谐(Houlsby等人,2019;Pfeiffer等人,2020b;胡等人,2021)。基于适配器的调优中的一些工作密切相关受T-REx三元组训练的限制,并且缺乏对非结构化知识进行训练的灵活性。与MixDA类似,CPT(Ke等人,2022a)将领域知识集成到LM中,但它采用了不同的方法。MixDA使用域适配器来代替FFN层和任务适配器来执行最终任务,而CPT则添加了学习域知识的CL插件。何等人最近的工作(2021a)提出了一个统一的框架,该框架建立了不同PEFT方法之间的联系。我们的工作可以利用任何PEFT方法并对其进行补充。
3.4 Mixture-of-Experts
专家混合(MoE)(Shazeer等人,2017)介绍了几种专家网络、门控网络和负载平衡技术。以下研究改进了MoE的初始化和训练方案(Fedus等人,2022)、路由机制(Zuo等人,2021;Yang等人,2021)和负载平衡问题(Lewis等人,2021,Roller等人,2021年)。AdaMix(Wang等人,2022)提出了一种混合适配器来提高下游任务性能。我们的领域适配器不是混合不同设计的适配器,而是专门为领域知识设计的前馈网络。
4. Approach
我们模型的总体架构如图1所示。培训过程分为两个阶段。在阶段1(图1(a))中,我们在一些Transformer层中注入了与原始预训练的前馈网络并行的新的前馈网络(FFN)(即域适配器),作为键值存储器。新注入的域适配器在域特定的未标记数据和原始预训练未标记数据上进行训练,以存储新的事实关联,同时保留旧的域关联。在此阶段,除域适配器外,所有模块都被冻结。
在第2阶段(图1(b)),我们在带有标记数据的下游任务上训练适配器(MoA)门和任务适配器的混合物,并且只有这两个新模块被更新。MoA门接收来自旧域FFN和域适配器的输出,然后输出它们的加权和。在每个Transformer块中插入一个额外的任务适配器,以便于执行下游任务。图1(c)显示了域适配器和MoA门的结构。
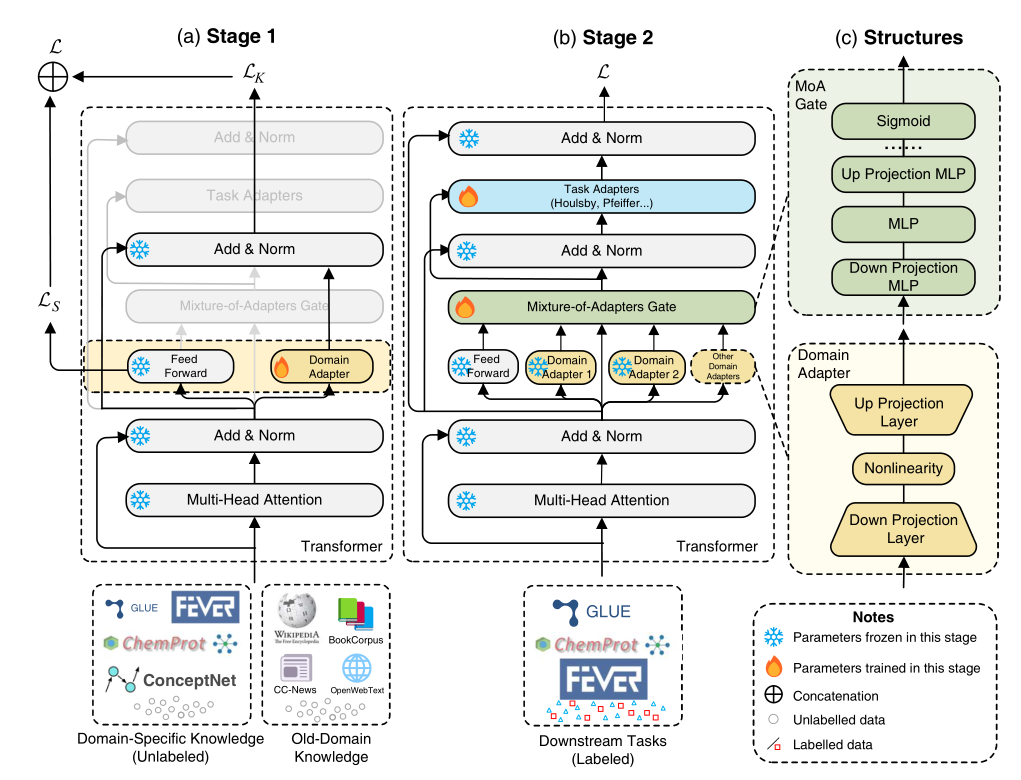
在本节中,我们首先介绍domain adapter,它学习和存储领域特定的知识,然后描述执行下游任务的任务适配器。最后,我们讨论了MoA门如何集成来自FFN和域适配器的输出。
4.1 Domain-Adapter
先前的研究(Geva等人,2021;Cao等人,2021年;Meng等人,2022)表明,事实关联存储在一些Transformer层的FFN中。为了帮助模型学习特定领域的知识,我们提出了一种与FFN并行工作的轻量级领域适配器,以及一种在保留旧领域知识的同时学习特定领域知识的训练方法。域适配器有一个简单的瓶颈架构,由向下投影层、非线性(如ReLU(Agarap,2018))和向上投影层组成。这有助于保持较低的参数大小(Houlsby等人,2019),并具有竞争力的性能。
在阶段1中,域适配器在一批中使用域特定的和旧的域数据集进行训练。请注意,在此阶段,除域适配器外,所有其他参数都被冻结。设LK表示与领域特定知识相关的知识损失,LS表示与旧领域知识相关的采样损失。知识损失是预测掩蔽令牌的交叉熵损失,采样损失旨在对齐旧领域知识和新领域特定知识的潜在空间。总损失L由二者的加权和给出,即
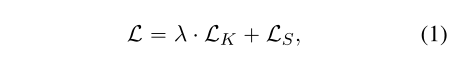

结构化知识如果知识数据集是结构化的(例如ConceptNet(Speer等人,2016)),我们将每个关系翻译成一个句子,然后掩盖它的对象。例如,关系“埃菲尔铁塔–/r/LocatedAt–Paris”被翻译为“埃菲尔铁塔位于巴黎”,然后“巴黎”被[MASK]取代,模型被训练来填充面具。
非结构化知识对于非结构化知识(例如,下游未标记文本),我们使用类似于RoBERTa预训练的掩蔽语言模型(MLM)。从输入句子中随机抽取一些标记,并用特殊标记
对于旧的领域知识和抽样损失,我们在包括维基百科和图书语料库在内的通用语料库上训练模型(Zhu et al.,2015)。具体来说,对于每一批,将从数据集中随机采样的句子输入到模型中。给定安装了域适配器的L层,对于每个这样的层L,我们从FFN Fl收集令牌表示,从域适配器Kl收集表示。目标是使它们尽可能相似。因此,我们计算具有L2损耗的采样损耗LS:

4.2 Task-Adapter
在训练了域适配器之后,模型就知道了域知识,这与下游任务没有直接关系。因此,我们在域适配器的顶部添加任务适配器,以适应下游任务。例如,受过生物医学知识培训的领域适配器可以支持在域中移植不同的任务,而在一个任务上训练它将其能力限制在特定任务上。任务适配器可以是任何适配器架构或其他参数有效的微调方法,如Houlsby适配器(Houlsby等人,2019)、Pfeiffer适配器(Pfeiffr等人,2020b)、前缀调整(Li和Liang,2021)等。在第2阶段,除任务适配器和MoA门(第3.3节)外的所有参数都被冻结。尽管添加了域适配器,但适配器的训练仍遵循相应的方法。例如,对于文本分类任务,我们在模型顶部添加一个分类层,冻结除分类层、MoA门和任务适配器之外的所有参数,将输入文本输入到模型中,并使用交叉熵作为损失。
4.3 Mixture-of-Adapters Gate
在下游任务中,FFN的输出或两者的加权和可能会产生更好的结果。因此,在第二阶段,我们同时训练一个额外的适配器(MoA)门的混合物。MoA门接收来自关注层q、域适配器K 和 FFN F的输出。q首先被发送到多层感知器(MLP)中:
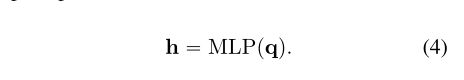
MLP由下投影层Wd和上投影层Wu组成,其中σ是非线性函数。然后,h被输入到Sigmoid层中,以生成FFN和其他域适配器的权重:
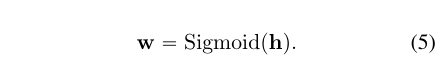
最终输出o是FFN和域适配器的输出的加权和:
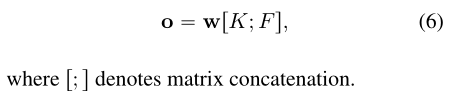
- Domain Mixture-of-Domain-Adapters Pre-trained Decoupling Injectingdomain mixture-of-domain-adapters pre-trained mixture-of-domain-adapters injecting decoupling injecting hijacking process remote decoupling networks neural depth recommendation empowering decoupling long-tail pre-trained vision-language manipulation pre-trained open-world perl contextualized pivot-based pre-trained