概述
提出MOO: Manipulation of Open-World Objects
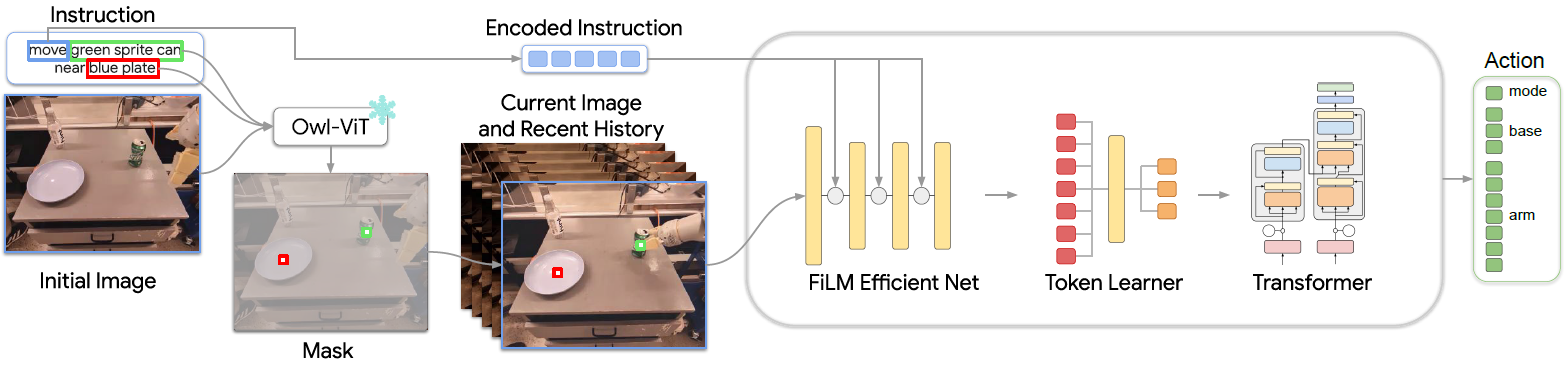
用预训练的VLM在图像中标记instruction的object的坐标,传入policy进行控制,可以zero-shot泛化到novel object,还支持手指、点击输入指令。
问题
机器人泛化到训练中没有见过或者操作过的object。
- perception-planning-control的pipline支持robots处理很多object
- 这样的pipline太脆弱,因为物体操作依赖精准的物体定位
- 预训练的图像和语言embedding构造policy,对novel semantic concept没有grounding能力
总之,一些方法可以泛化到很多object但是流程太脆弱,另一些方法没那么脆弱但是泛化能力不足
动机
为了提高对新语义概念的泛化能力,采用open-vocabulary预训练VLM,而不是单modality的模型。
方法
instruction的5种固定模板:pick X, move X near Y, knock X over, place X upright, place X into Y
- 用Owl-ViT来提取object位置信息,将得到的bounding box的中点pixel置1.0(另一个obj置0.5),作为image的一个channel
- 采用pixel而不是bounding的好处:对任何大小的可见物体都work,且和各种视觉的方法都适配(都能改成pixel形式)
- (为了提高及时性)只对第一帧图片进行提取,对位置变化的处理由policy进行
- 用颜色、大小、形状等信息进行标定,例如:An image of a small blue elephant toy
- 设置一个统一的threshold对bounding box的score进行筛选
- 将image序列输入RT-1的policy结构中
- image序列用EfficientNet处理,结合FiLM对动作embedding的处理
- 接入Token Learner,再接入一个Transformer
注意instruction的encode只包含verb信息
实验
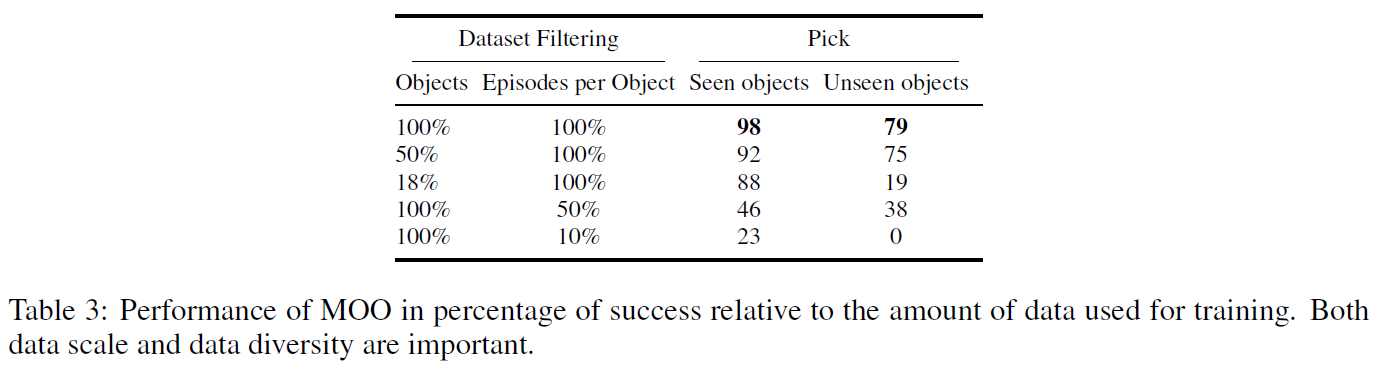
训练数据
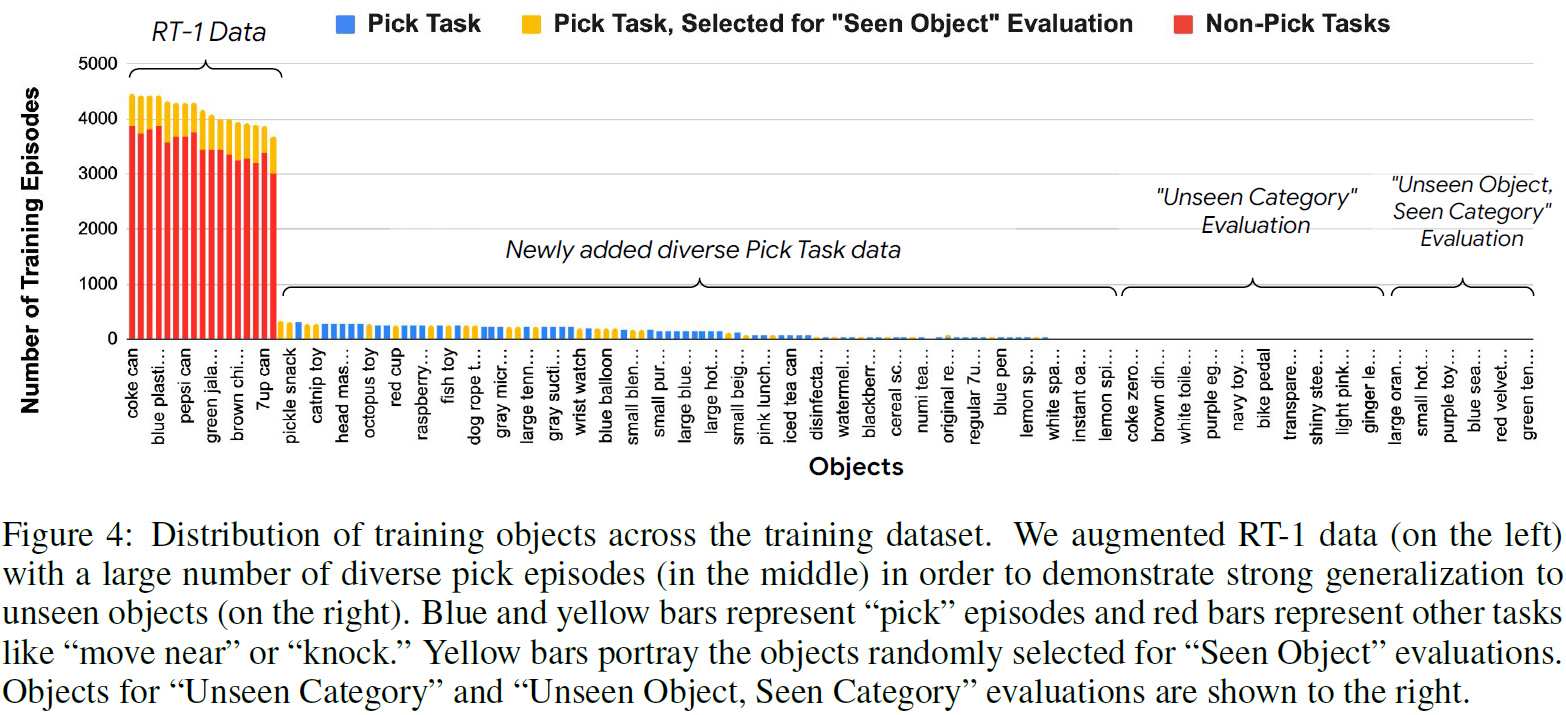
对RT-1的数据进行了增广,主要是增加了“pick”技能的object。作者表示只选择pick是因为这个简单,数据收集效率高,方便展现出对各种object的泛化(真会说)。

演示数据的分布:
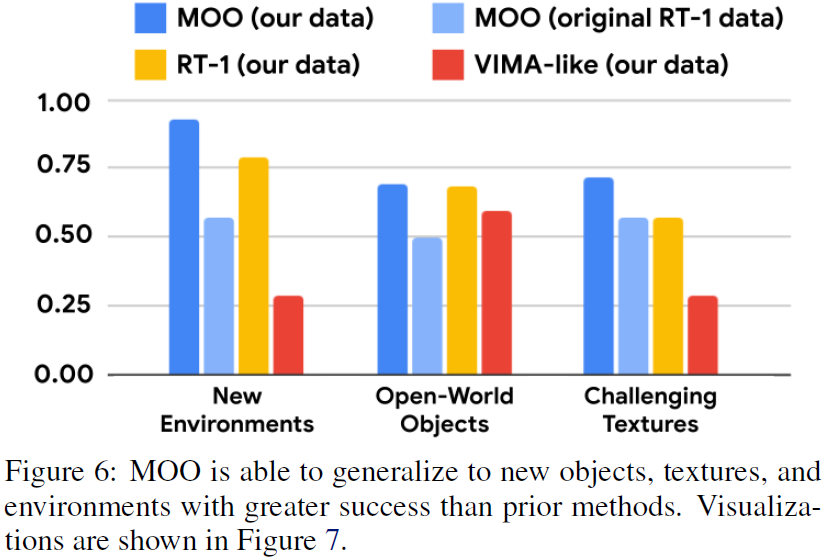
泛化能力
49种见过的obj,47种没见过的
作者专门强调了是完全没见过的obj,而不是没见过的instruction组合
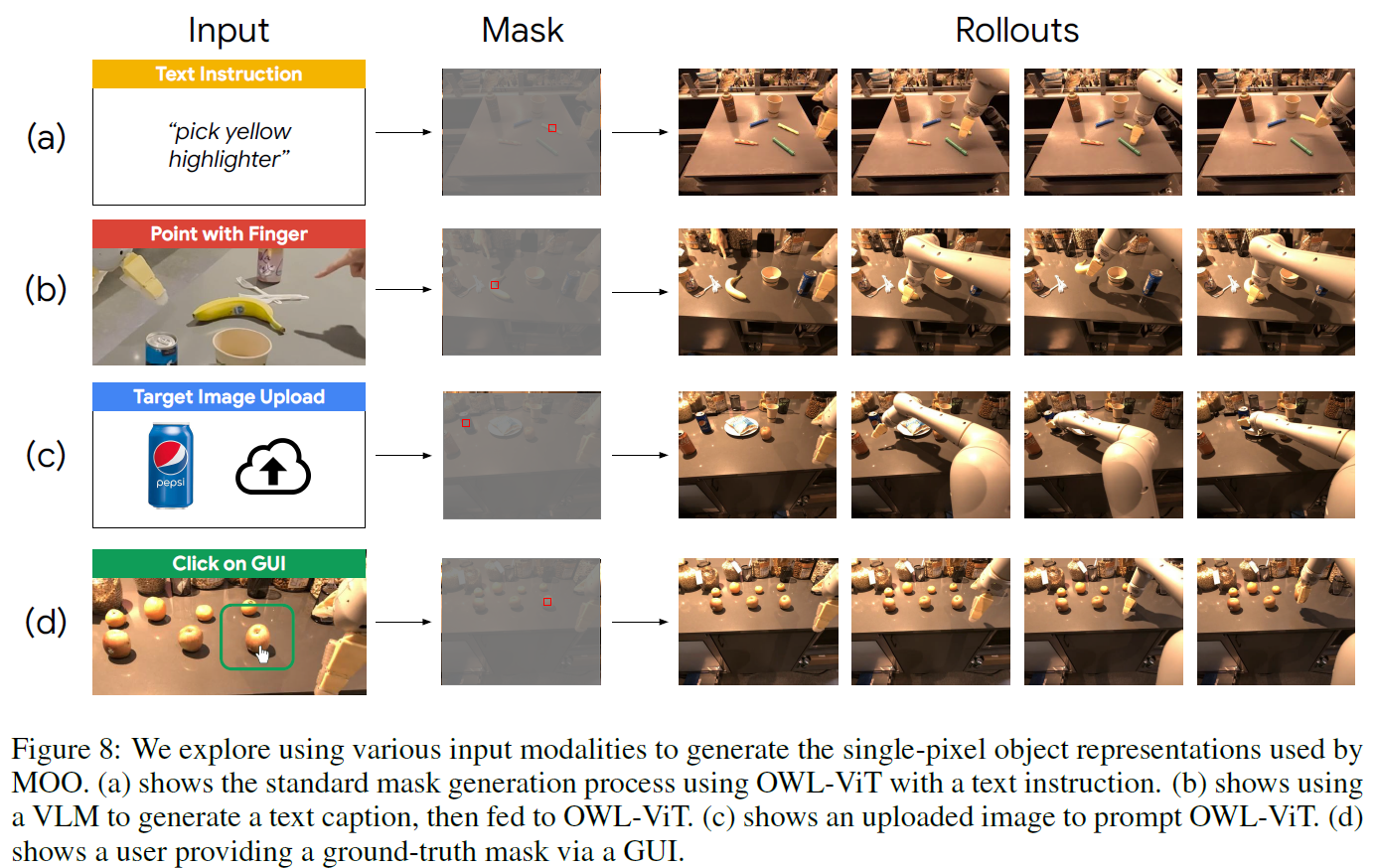
多种模态输入
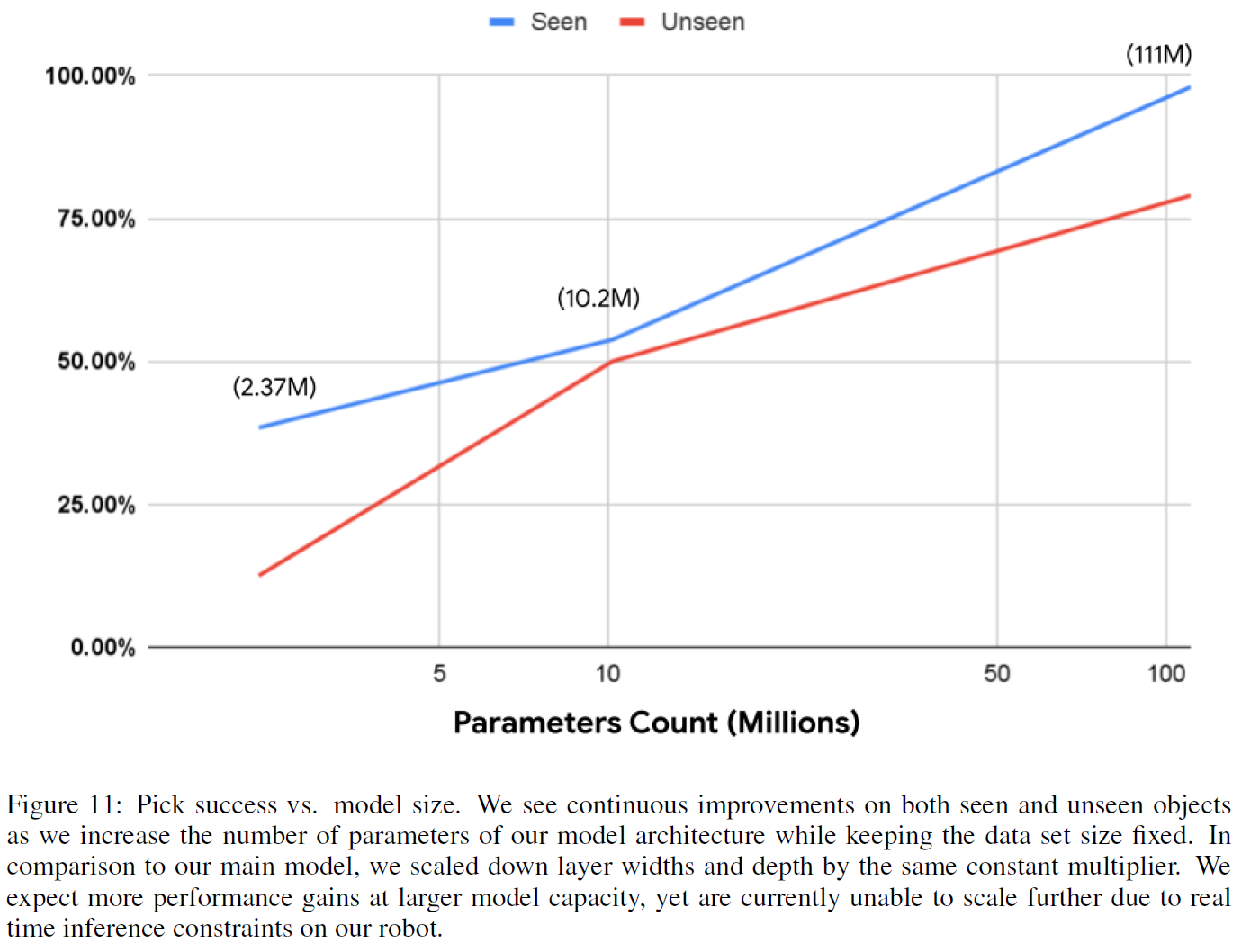
模型扩展性
总结和不足
利用了VLM的语义理解能力,实现novel object的泛化。
不足:
- object的表示在图像出现歧义(例如物体覆盖或者阻挡等)时不再好用
- skill的泛化仍然需要局限在training data中(对于完全不同的形状和大小的obj无能为力)
- instruction的格式需要简单清晰且固定化,尤其是对verb的定义。这个问题可能可以通过LLM解决
- 无法解决instruction中利用空间来定义的object,例如"the small object to the left of the plate"
- Vision-Language Manipulation Pre-trained Open-World Languagevision-language manipulation pre-trained open-world vision-language vision-language understanding enhancing advanced vision-language pre-training embodiedgpt embodied language vision-language模态vision manipulation语句language数据 manipulation language数据mysql 数据manipulation language语言 open-world pre-trained