PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
阅读笔记(11.2)
摘要:优化MSE指标通常会导致模糊,特别是在高方差(详细)区域。我们提出了一种基于创建正确降尺度的真实SR图像的超分辨率问题的替代方案。我们提出了一种新的超分辨率算法,PULSE(通过潜在空间探测的照片上采样),它生成高分辨率的真实图像,分辨率在文献中从未见过。它以一种完全自监督的方式完成这一点,并且不局限于训练过程中使用的特定退化算子,不像以前的方法(需要在LR-HR图像对数据库上进行监督学习)。PULSE不是从LR图像开始,然后慢慢添加细节,而是遍历高分辨率的自然图像流形,搜索缩小到原始LR图像的图像。这是通过“降尺度损失”来形式化的,它指导通过生成模型的潜在空间进行探索。通过利用高维高斯函数的性质,我们限制了搜索空间,以保证我们的输出是真实的。因此,PULSE生成的超分辨率图像既真实又准确。我们展示了大量的实验结果,证明了我们的方法在人脸超分辨率(也称为人脸幻觉)领域的有效性。我们还讨论了该方法的局限性和偏差,目前使用附带的带有相关指标的模型卡实现。我们的方法优于最先进的方法在更高的分辨率和比例因子比以前可能的感知质量。
- 介绍
在这项工作中,我们的目标是将模糊的、低分辨率的图像转化为清晰的、真实的、高分辨率的图像。在这里,我们专注于面部图像,但我们的技术是普遍适用的。在许多领域(如医学、天文学、显微镜和卫星图像),由于成本、硬件限制或内存限制等问题,很难获得清晰的高分辨率图像。这将导致捕捉到模糊、低分辨率的图像。在其他情况下,图像可能是旧的,因此模糊,甚至在现代背景下,图像可能是失焦的,或者一个人可能在背景中。除了在视觉上不吸引人之外,这还损害了下游分析方法(如图像分割、动作识别或疾病诊断)的使用,这些方法依赖于高分辨率的图像。此外,随着近年来笔记本电脑、手机和电视屏幕分辨率的提高,对清晰图像和视频的普遍需求也大幅上升。这激发了最近对图像超分辨率的计算机视觉任务的兴趣,即创建一个给定的低分辨率(LR)输入图像可以对应的真实的高分辨率(HR)图像。
虽然图像超分辨率方法的好处是显而易见的,但HR和LR图像之间的信息含量差异(特别是在高比例因子下)阻碍了这类技术的发展。特别是LR图像固有地拥有较少的高方差信息;细节可以模糊到视觉上无法区分的程度。恢复由LR输入描述的真实HR图像的问题,相对于生成一组潜在的这样的HR图像,本质上是病态的,因为这些图像的总集合的大小以比例因子[3]的指数增长。也就是说,许多高分辨率图像可以与完全相同的低分辨率图像相对应。
传统的监督超分辨率算法训练一个模型(通常是卷积神经网络,或CNN),以最小化生成的超分辨率(SR)图像和相应的地面真实HR图像[15][8]之间的像素均方误差(MSE)。然而,这种方法已经被注意到忽略了感知相关的细节,对HR图像的摄影现实主义至关重要,如纹理[16]。优化HR和SR图像之间像素空间的平均差异有模糊效果,鼓励SR图像的细节区域被平滑,平均而言,更(像素)正确。事实上,在均方误差(MSE)的情况下,理想的解决方案是一组真实图像的(加权)像素平均,适当缩小到LR输入(稍后详细说明)。不可避免的结果是在高变化的区域平滑,例如图像中具有复杂图案或纹理的区域。因此,MSE不应该单独用作超分辨率图像质量的度量。
一些研究人员试图扩展这些基于MSE的方法,以进一步优化旨在鼓励现实性的指标,作为反对MSE项平滑拉的力量。这实际上是将基于mse的解决方案拖向自然图像流形(R M×N的子集,表示高分辨率图像集)的方向。这种折衷虽然比纯粹的基于mse的解决方案提高了感知质量,但不能保证生成的图像是真实的。用这些技术生成的图像在图像的高方差区域仍然显示出模糊的迹象,就像在纯基于mse的解决方案中一样。
为了避免这些问题,我们提出了一种超分辨率的新范式。目标应该是在一组可行的解决方案中生成真实的图像;也就是说,找到真正位于自然像流形上的点,并正确地缩小尺寸。由于前面描述的原因,由MSE产生的可能解决方案的(加权)像素平均通常不满足这一目标。
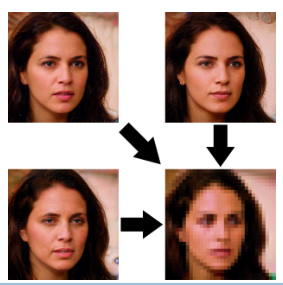
我们在图2中对此进行了说明。
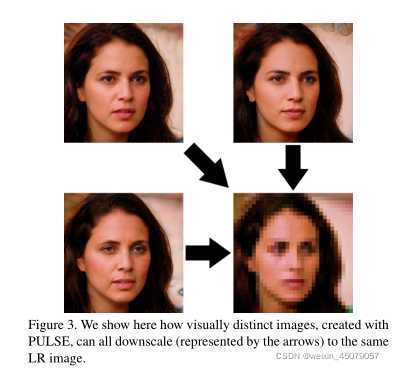
我们的方法使用(预训练的)生成模型生成图像,近似于考虑的自然图像的分布。对于一个给定的输入LR图像,我们遍历由生成模型的潜在空间参数化的流形,以找到正确降尺度的区域。在这样做的过程中,我们找到了一些适当降尺度的真实图像的例子,如1所示。
这种方法也避免了监督训练的需要,完全是自监督的,在超分辨率推理时不需要“训练”(非监督生成模型除外)。该框架提供了多个实质性的好处。首先,它允许相同的网络用于具有不同退化算子的图像,即使没有对应的LR-HR对的数据库(因为没有对这样的数据库进行训练)。此外,与以前的方法不同,它不需要超分辨率的任务特定网络架构,这需要大量的时间在研究人员的部分开发,而不提供对问题的真正洞察;相反,它与生成建模中最先进的技术一起进行,不需要再培训。
我们的方法适用于任何带有可微分生成器的生成模型,包括基于流的模型、变分自编码器(vais)和生成式反式网络(GANs);具体的选择取决于每个人在接近数据流形时所做的权衡。对于这项工作,我们选择使用GANs,因为最近的进展可以产生高分辨率、清晰的图像。
图像超分辨率的一个特殊子域处理的是人脸图像的情况。这个子域——被称为“面部幻觉”——在消费摄影、照片/视频还原等领域得到了应用。因此,它作为一项计算机视觉任务本身就引起了人们的兴趣。我们的工作重点是面部幻觉,但我们的方法延伸到更广泛的背景下。
因为我们的方法总是产生一个解决方案,既基于自然图像流形,又正确地下采样到原始低分辨率图像,我们可以提供一系列有趣的高分辨率可能性,例如,利用许多生成模型中固有的随机性:我们的技术可以创建一组图像,每个图像在视觉上都令人信服,但看起来彼此不同,其中(没有基本事实)任何图像都可能是低分辨率输入的来源。
我们的主要贡献如下。
- 图像超分辨率的新范式。以前的工作采取了传统的、不合理的视角,试图从LR输入“重建”人力资源图像,产生的输出实际上平均了许多可能的解决方案。这种平均引入了不必要的模糊。我们介绍了一种超分辨率的新方法:超分辨率算法应该创建真实的高分辨率输出,向下缩放到正确的LR输入。
- 一种求解超分辨率任务的新方法。根据我们的新视角,我们提出了一种新的超分辨率算法。传统工作的核心是使用监督学习(特别是使用神经网络)近似LR→HR映射,而我们的方法集中于使用HR数据的非监督生成模型。使用生成对抗网络,我们探索潜在空间,以找到映射到现实图像的区域,并正确地缩小比例。不需要再培训。我们的具体实现使用StyleGAN,允许创建任意数量的真实SR样本,正确地映射到LR输入。
- 高维高斯先验下潜在空间搜索的一种新方法。在我们的任务和许多其他任务中,通常需要在生成模型的潜在空间中找到映射到现实输出的点。直觉上,这些应该与训练中看到的样本相似。起初,通过潜在先验的传统对数似然正则化似乎可以实现这一点,但我们观察到“肥皂泡”效应(高维高斯分布的大部分密度靠近超球表面)与此相反。传统的对数似然正则化实际上倾向于将潜在向量从超球体中抽离,而转向原点。因此,我们将搜索空间限制在超球体的表面,以确保在高维潜在空间中的真实输出;这样的空间在其他方面很难搜索。
(我看不懂这一块,感觉自己以前完全没有接触过)
FSRNet倾向于适当降尺度的图像的平均值。FSRGAN中的鉴别器损耗将其拉向自然图像流形的方向,而PULSE总是沿着这个流形移动。

图3。我们在这里展示了使用PULSE创建的视觉上截然不同的图像如何缩小(用箭头表示)到相同的LR图像。
- 相关工作
虽然在卷积神经网络(CNNs)出现之前,有很多关于图像超分辨率的工作,但基于cnn的方法已迅速成为该领域的最新技术,并与我们的工作密切相关;因此,我们将重点放在基于神经网络的方法上。通常,这些方法使用一个管道,其中通过下采样高分辨率(HR)图像创建的低分辨率(LR)图像将通过具有卷积层和上采样层的CNN输入,生成超分辨率(SR)输出。然后使用该输出使用所选的损失函数和原始HR图像计算损失。
目前的趋势:
最近,监督神经网络已经成为当前超分辨率工作的主导。Dong等人[9]提出了第一个CNN架构,使用HR-LR图像对学习这种非线性LR到HR映射。几个小组已经尝试利用亚像素卷积和转置卷积[22]来改进上采样步骤。此外,ResNet架构对超分辨率的应用(由SRResNet[16]启动)比传统的卷积神经网络架构有了实质性的改进。特别是,利用残余结构可以训练更大的网络。目前,存在两个总体趋势:一是网络主要更好地优化SR和HR之间的像素平均距离,二是网络关注感知质量。
损失函数:
传统上,图像超分辨率任务的损失函数是在每像素的基础上运行的,通常使用地面真实值和重建图像之间的L2范数,因为这直接优化了PSNR(超分辨率任务的传统度量)。最近,一些研究人员开始使用L1范数,因为使用L1损失训练的模型似乎在PSNR评估中表现更好。SR和HR图像之间的L2规范(以及一般的像素平均距离)因与人类观察到的图像质量[16]不太相关而受到严重批评。在人脸超分辨率方面,最先进的测量方法是FSRNet[8],它使用人脸先验来实现以前从未见过的PSNR。
然而,感知质量并不一定随着更高的PSNR而增加。因此,人们开发了不同的方法,特别是目标函数,以提高感知质量。特别是,产生高PSNR的方法会导致细节模糊。细节所需要的信息通常不存在于LR图像中,必须在图像中“想象”出来。演示了一种避免直接使用标准损失函数的方法,它从卷积网络的结构中提取先验。这种方法产生的图像与专注于PSNR的方法相似,缺乏细节,特别是在高频区域。因为这种方法不能利用学习到的关于真实图像是什么样子的信息,它不能填补缺失的细节。尝试从LR图像学习映射到HR图像的方法可以尝试利用学习到的信息;然而,如前所述,在PSNR上优化的网络仍然会因为试图对不确定的细节产生幻觉而受到明显的惩罚,因此在PSNR剧照上优化会导致模糊和细节缺乏。
为了解决这个问题,一些人尝试使用基于生成模型的损失条款来提供这些细节。神经网络在各种类型的生成模型(特别是生成对抗网络-从[10])中的应用,在一般的图像重建任务中,以及最近的超分辨率中。Ledig等[16]利用深度生成模型(特别是GANs)中的这些进步,为单幅图像上采样创建了SRGAN体系结构。他们的一般方法是使用生成器提升低分辨率的输入图像,然后鉴别器试图将其与真实的HR图像区分开来,然后将损失传播回两个网络。本质上,这优化了一个监督网络,就像基于mse的方法一样,附加了一个损失项,对应于鉴别器认为生成的图像的伪造程度。然而,这种方法从根本上是有局限性的,因为它基本上会导致基于mse的解决方案和基于gan的解决方案的平均,我们将在后面讨论。在人脸的背景下,该技术已被纳入FSRGAN中,导致当前感知的最先进的人脸超分辨率为×8,放大系数可达128 × 128的分辨率。尽管这些方法使用GANs中的“生成器”和“鉴别器”,但它们是在完全监督的方式下训练的;它们不使用无监督生成模型。
生成网络:
我们的算法不是简单地使用gan风格的训练;相反,它使用了真正的无监督GAN(或者更广泛地说,生成模型)。它搜索生成模型的潜在空间,寻找映射到正确降尺度图像的潜在空间。因此,尖端生成模型的质量是我们感兴趣的。
由于GANs已经生成了迄今为止深度生成模型的最高质量高分辨率图像,因此我们选择将重点放在实现这些图像上。在此,我们简要回顾了相关的高分辨率GAN方法。Karras等人[12]在他们的ProGAN算法中首次展示了深度生成模型的一些高分辨率输出,该算法以渐进的方式增长生成器和鉴别器。。卡拉等[13]在StyleGAN的基础上进一步建立了这个想法,旨在允许在图像合成过程中进行更多的控制,相对于之前出现的黑箱方法。输入潜码嵌入到中间潜空间中,然后通过在每个卷积层应用自适应实例归一化来控制合成网络的行为。该网络有18层(从4 × 4到1024 × 1024每个分辨率各2层)。每隔一层,分辨率逐渐增加2倍。在每一层,通过高斯输入随机引入新的细节到自适应实例归一化层。在不干扰鉴别器或损失函数的情况下,该体系结构可以选择特定比例的混合和控制图像中各种高级属性和变化的表达(例如姿势、头发、雀斑等)。因此,StyleGAN提供了非常丰富的潜在空间来表达不同的特征,特别是与脸有关的特征。
- 方法
用ILR表示低分辨率的输入图像。目标是学习一个条件生成函数G,当应用到ILR时,产生一个更高分辨率的超分辨率图像ISR。形式上,让ILR∈Rm×n。那么我们的期望函数SR是一个映射Rm×n→RM×N,其中M > m, N > n。定义超分辨图像ISR∈RM×N.
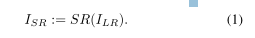
在传统的超分辨率方法中,人们认为低分辨率图像可以表示与理论高分辨率图像IHR∈RM×N相同的信息。然后,目标是在ILR条件下最好地恢复这一特定的《国际卫生条例》。因此,这种方法将问题简化为一个优化任务:拟合一个最小化的函数SR:
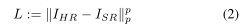
P表示p范数。
在实践中,即使训练正确,这些算法也不能增强高方差区域的细节。要知道这是为什么,修复一个低分辨率的图像ILR。设M为RM×N中的自然图像流形,即RM×N中与自然真实图像相似的子集,设P为描述图像在数据集中出现的可能性的概率分布除以M。最后,设R为正确降尺度的图像集,即R = {I∈RN×M: DS(I) = ILR}。当数据集的大小趋于无穷大时,当算法输出一个固定的图像ISR时,我们的期望损失为:
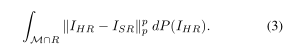
当ISR是IHR / M∩R的p范数平均值时。这是最小值,事实上,当p = 2时,当
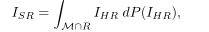
所以最佳ISR是一组适当降尺度的高分辨率图像的加权像素平均。因此,仅依靠lp规范的算法缺乏细节的问题不能简单地通过改变网络的体系结构来解决。问题本身必须重新表述。
因此,提出了一种新的单幅图像超分辨率框架。设M, DS定义如上。那么对于给定的LR图像ILR∈Rm×n和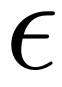 > 0,我们的目标是找到一个ISR∈M在
> 0,我们的目标是找到一个ISR∈M在
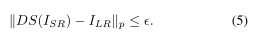
特别地,我们可以让R?⊂RN×M是一组适当缩小的图像,即,
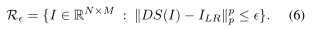
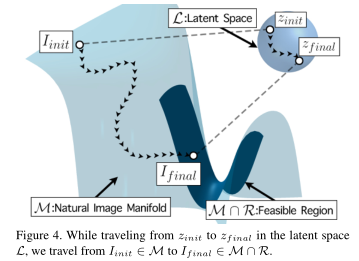
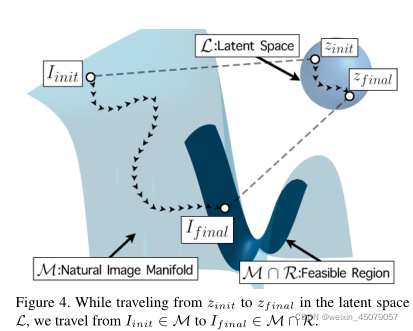
图4。当我们在潜空间L中从zinit走到zf末端时,我们从Iinit∈M走到If inal∈M∩R。
那么我们正在寻找一个图像ISR∈M∩R?集合M∩R?是可行解决方案的集合,因为如果一个解决方案没有适当地缩小规模并看起来真实,它就不是可行的。
同样有趣的是,交叉点M∩R?特别是M∩R0保证不为空,因为它们必须包含原始的HR图像(即传统方法旨在重构的图像)。
3.1下降损失
与一般图像生成不同,超分辨率问题的核心是准确性的概念。传统上,这被解释为通过应用超分辨率算法SR对低分辨率输入ILR“恢复”特定的地面真相图像IHR的效果如何,如上面的相关工作部分所述。这通常是通过ISR和IHR基础真理之间的某些lp规范来衡量的;这样的算法看起来只像真实的图像,因为最小化这个度量会使解更接近流形。然而,他们没有办法确保ISR接近M。相反,在我们的框架中,我们从来没有偏离M,所以这样的度量是不必要的。对我们来说,正确的关键概念是生成的SR图像ISR与ILR的对应程度。
我们通过降尺度损失将其形式化,以明确地惩罚偏离LR输入的SR图像([2]、[25]中提出了类似的损失项)。这是受以下启发:对于提议的SR图像表示与给定LR图像相同的信息,它必须缩小到该LR图像。也就是说:
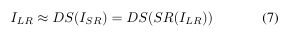
其中DS(·)表示降尺度函数。
因此,我的当他的输出越违反下面公式,我们的降尺度损失越惩罚SR
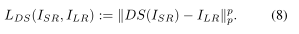
值得注意的是,降尺度损失可用于超分辨率的有监督和无监督模型;它不依赖于HR参考图片。
3.2潜在空间探索
我们如何在降尺度算子下找到映射到正确LR图像的自然图像流形M的区域?如果我们对流形有一个可微的参数化,我们可以通过使用降尺度损失来指导我们的搜索,沿着流形前进到这些区域。在这种情况下,找到的图像将被保证是高分辨率的,因为它们来自HR图像集合,同时也是正确的,因为它们将缩小到LR输入。
在现实中,我们没有流形的这样方便、完美的参数化。然而,我们可以通过使用非监督学习的技术来近似这种参数化。特别是,深度生成建模(例如vais、基于流的模型和GANs)的许多领域都关注创建从一些潜在空间映射到给定兴趣流形的模型。通过利用生成建模的进步,我们甚至可以使用预先训练的模型,而不需要训练我们自己的网络。一些先前的工作旨在在生成模型的潜在空间中寻找向量来完成任务;参见[2]在压缩感知上下文中创建嵌入和[6]。(然而,正如我们后面所描述的,这项工作实际上并没有以一种产生预期的现实输出的方式进行搜索。)在这项工作中,我们将重点放在GANs上,因为最近在该领域的工作已经在无监督模型中产生了最高质量的图像生成。
不论其结构如何,设生成器为G,潜空间为L。理想情况下,我们可以用G的像近似M,这样我们就可以把上面的问题重新表述为:找到一个潜向量z∈L
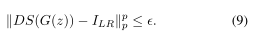
不幸的是,在大多数生成模型中,仅仅要求z∈L并不能保证G(z)∈M;相反,这种方法在L上使用一个强加的先验。为了保证G(z)∈M,我们必须在所选先验下L的一个高概率区域内。鼓励潜伏在高概率区域的一个想法是为先验的负对数可能性添加一个损失项。在高斯先验的情况下,这采取l2正则化的形式。事实上,这就是前面提到的[6]试图解决这个问题的方式。然而,这个想法实际上并没有达到目的。这样的惩罚迫使向量趋于0,但是高维高斯函数的大部分质量位于半径为√d的球面附近(见[26])。为了解决这个问题,我们观察到可以用√dSd−1上的均匀先验替换Rd上的高斯先验。这种近似可用于任何具有高维球高斯先验的方法。
我们可以令L0 =√dSd−1(其中Sd−1⊂Rd是d维欧氏空间中的单位球),将上面的问题简化为寻找一个满足式(9)的z∈L0。这样就将整个潜空间的梯度下降问题简化为球体上的投影梯度下降问题。
二:
作者指出:以往的SR方法是有监督的,往往是将SR到HR图像之间的平均距离作为训练目标,但是这样做会导致图片细节的缺失,尤其是在超分领域细节更加重要。
作者提出的新超分算法PULSE
1.以完全无监督实现,不需要成对的LR-HR图像进行训练。
2.通过遍历高分辨率图像流形的方法,寻找能够缩放到原始LR图像的图像,而不是从LR图像开始,慢慢增加细节。
3.通过利用high-dimensional Gaussians的特性,限制搜索空间,保证输出的真实性。
创新点:
针对SR的新范式:
传统的SR方法中,人们认为理论上,低分辨率图像和高分辨率图像蕴含相同的信息量,因此目标就鉴于给定的ILR(低分辨率图片)如何恢复为IHR(高分辨率图片),所以任务就是拟合函数SR,使其最小化。
传统方法中Lp规范化缺乏细节,并且这个问题不能通过改变网络结构来解决。
本文提出了一种针对单幅图像SR的新的框架,其目标是对于给定的ILR,在流形上找到一个ISR(超分辨率图像),使得
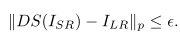
这里作者令

作为正确缩放的图片集合,然后再流形和集合的交集空间中寻找潜在的目标图像。
2.Downscling Loss
作者认为SR问题的核心是正确性,SR问题的准确性的关键是生成的超分辨率图像ISR与ILR必须相对应。即
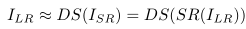
对此提出了降尺度损失(downscaling function)来对应上述概念,;利用降尺度损失来惩罚偏离ILR的ISR。
总的来说,当PULSE模型的生成网络提议以一张清晰图像作为输出时,判别网络会把这张清晰图像的分辨率降低到与输入图像相等的水平。然后,判别网络会对比降尺度损失图像与输入图像之间的相似性。只有在降尺度损失图像与输入图像相似性较高时,判别网络才会判定生成网络提议的清晰图片可以作为输出。
3.Latent Space Exploration
本文对流形进行了可微分的参数化,然后使用降尺度损失沿着流形搜索,这样的话,找到的图像来自高像素图像流形,同时能够保证为正确的图像,因为能多降尺度为LR输入图像。
本文使用无监督学习技术来近似流行的参数化,使用无监管模型中的GAN网络来生成图像。
这里作者引入生成器G潜在空间c理想情况下可以用生成器生成的图像来近似流形M,那么上述问题就可以重述为,从C中寻找一个潜在的向量z, 使之满足
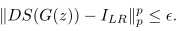
为了保证生成器的图像是在流形空间内的,潜在空间L的区域需要大概率在所选的先验条件下。
总结
这篇文章提出了图像超分辨率的新性表述方式,提出的方法有别于传统的监督学习方法,PULSE的确可以产生优质并且可以正确缩放的人脸图像,但是在自然环境图像的处理上有局限性。而且在实验部分的评价指标过于主观,还是缺少一定的说服性。
- Self-Supervised Exploration Generative Supervised Upsamplingself-supervised exploration generative supervised self-supervised interpretable adversarial generative self-supervised self-supervised transformers lightweight supervised self-supervised transformers supervised empirical self-supervised bidirectional supervised learning language-guided self-supervised segmentation self-supervised recommendation session-based self-supervised recommendation convolutional self-supervised quantization augmentation randomized