NEURAL SUBGRAPH MATCHING
总结
问题定义
给定一个查询图,判断该图是不是一个大图的子图。如果图中有点和边的特征,就要都匹配上。
动机
同构问题是NP完全的,已有的方法虽然能匹配很大的target图,但query图会很小。
模型框架
分为embedding部分和query部分。embedding部分用GNN学点特征(target采样k-hop邻居,query只学邻居),query部分比较所有点对的embedding。
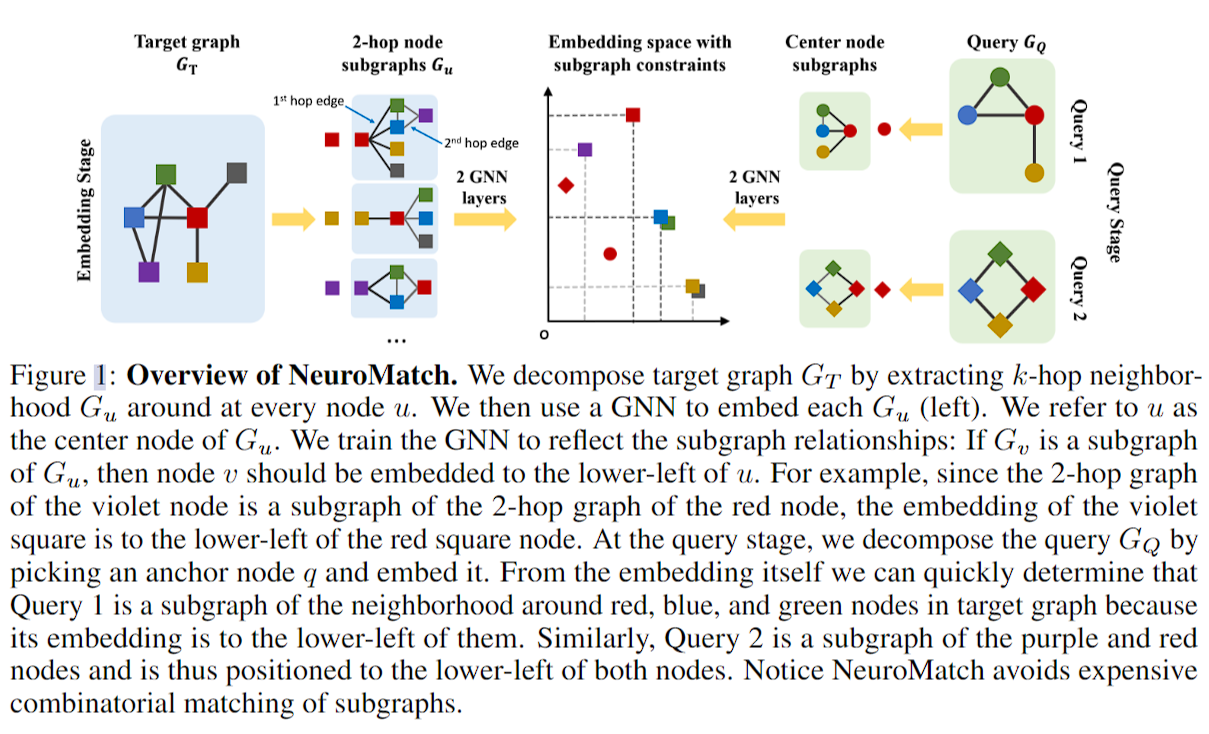
embedding部分
虽说对于target图要做k-hop的子图再embedding,但实际上这样的效果和直接做k层gnn是一样的。文章车轱辘话挺多。
query部分
这里第二行应该打错了,不是\(Z_T\)是\(Z_u\)。
大致就是解释了下可以把问题转为两个点的邻居情况相似度可以作为匹配的评判标准,进而将图级别的问题转为点级别的
实际操作
理应将query图大小作为k,但实际实验发现k=10就足够了,而GNN则是可以随意,文中选择了GIN的变体(有skip layers来encode query图和邻居点)。因为GIN在WL测试外存在能力上的限制,因此作者使用特征来区分锚点,从而提高模型区分d-正则图方面的能力。
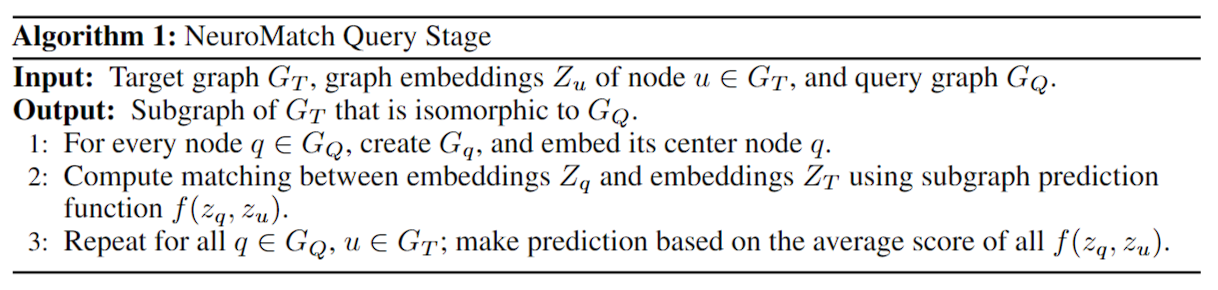
算法
具体实现
其实就是比较两点之间距离的公式。
首先,文章的想法是进行顺序嵌入,让子图的关系在嵌入空间中进行正常反应,而这个顺序嵌入的理想结果是点q的嵌入必须是点u的嵌入的左下角:
这里的D是特征维度。
因此,损失函数定义为:
其中\(E(z_q, z_u) = ||\max\{0, z_q - z_u\}||^2_2\),P是positive examples,N是negative examples。为了让模型更加完美,\(E(z_q, z_u)\)会从一个比0大的值变得趋向于0,而对于负样本,则是他们的差要尽可能比一个\(\alpha\)要大。
很明显,有个不太好解决的问题是样本如何生成。作者的思路很巧妙,说为了泛用性,训练数据集自己生成,这样就直接解决了正负样本的问题了。至于测试集,为了提高说服力,文中提到了用三种不同的方法来生成。
此外,算法还会从小图开始训练,然后不断加大图。
复杂度
embedding部分只涉及GNN,复杂度为\(O(K(|E_T| + |E_Q|))\),其中K是GNN层数。对于query部分,复杂度为\(O(|V_T||V_Q|)\)。由于精准算法是指数级增长的,所以这个时间复杂度作者认为非常快。
实验
数据集
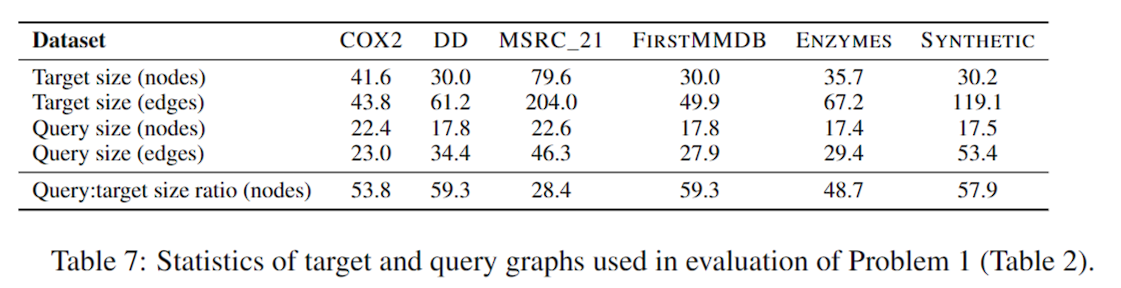
上面有说现在的算法难以解决大图,但实际上他们解决的图也很小。
精度实验
实验不管阈值如何获取,只报AUROC
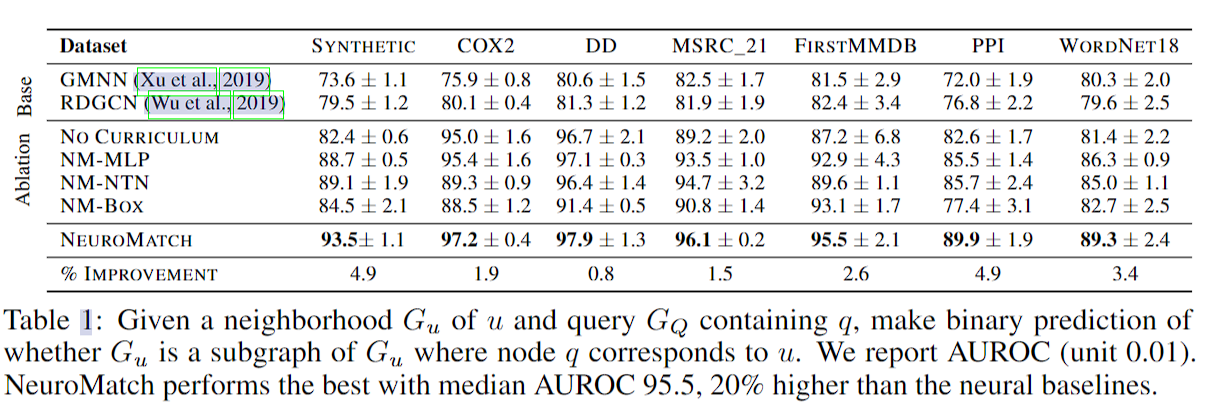
这个实验是抽了target里的一个点和邻居做了小图,靠和q的特征比距离,判断这个图和查询图的关系。所以实际上这个实验不是真正的子图同构。
这里有个很奇怪的地方,文中没题怎么取q点。
消融实验从上到下是不在训练时把图越挑越大、使用MLP、NTN替代GNN,使用BOX embedding loss。盒子嵌入是指图像的目标识别中让定位的位置和大小接近,而位置和尺寸能被编码,他们的欧氏距离就叫BOX embedding loss。
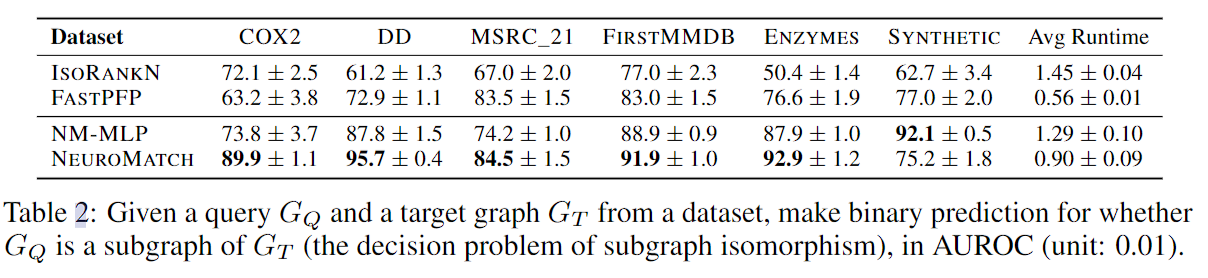
这里NTN难收敛,box没法用,因为不能保证两图之间的交集(为什么上一个实验就可以?应该还是因为实验结果有点爆炸了)
文中还提到了个voting的优化,其实就是增加了更多k跳邻居的匹配来进一步确保两个顶点的匹配。
- MATCHING SUBGRAPH NEURALmatching subgraph neural neural-symbolic subgraph symbolic neural efficient subgraph matching billion efficiency guaranteed matching subgraph in-memory matching in-depth subgraph distributed dataflow subgraph matching subgraph prediction sketching networks subgraph gpu-accelerated accelerated efficient subgraph representative metropolis algorithms subgraph