I. Source
II. My Code
课程官网提供的 Lab 代码下载地址,我没有访问成功,于是我从 Github 其他用户那里 clone 到干净的源码,有需要可以访问我的 Gitee 获取
III. Motivation
MapReduce 是经典的分布式计算模型,想要搞清楚何如 MapReduce?首先需要明白何为分布式计算模型以及为什么需要分布式计算模式
不论做什么事,最重要的是有 Motivation!那么问题来了,我们为什么需要分布式计算模型呢?难道单线程的处理程序不行嘛?
答案是肯定的,仅有单线程程序还是不够的,特别是在数据量很大的情况下。举个例子,现在需要对一个 1 MB 的 .txt 文件进行词频统计,在单线程情况下,一眨眼的功夫就能完成,表现还算优异;但如果需要统计 1 GB 的 .txt 文件,那么可能会等上一段时间才能完成,可能是 10 s,也可能更久
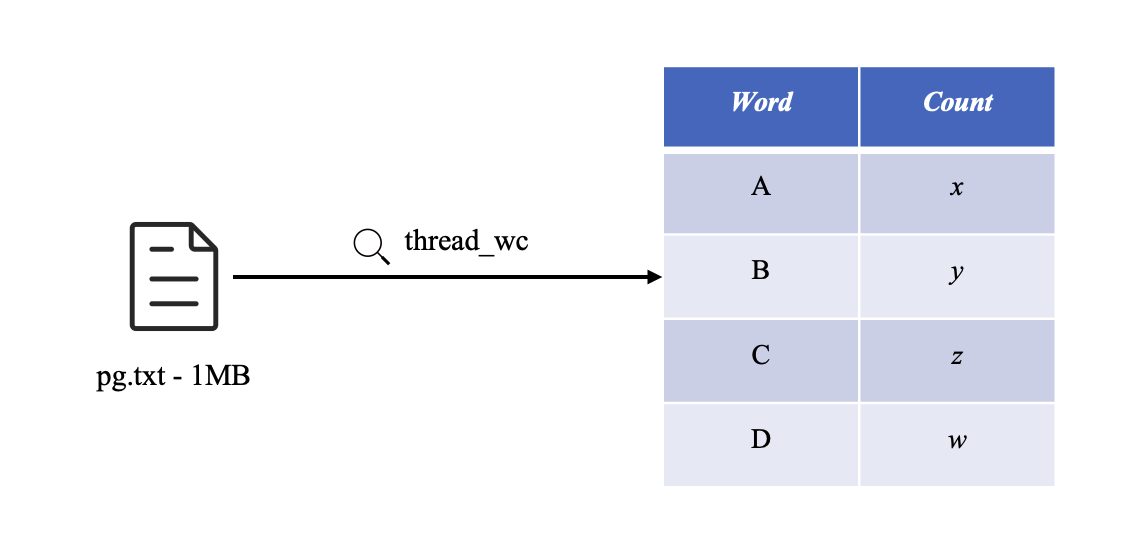
现在需求来了,我们希望加快解析速度,使统计 1 GB 的 .txt 也像 1 MB 那样快?能不能做到呢?同样,答案也是肯定的
我们现在手头上有很多闲置的机器(在现代硬件资源过剩的情况下很常见),可不可以把这些闲置的机器也派上用场呢,让它们也参与到解析 1 GB 大文件的流程中
这就引出了分布式计算模式的概念,将 1 GB 的 .txt 切割成 1000 份 1 MB 的 .txt,然后分发给集群中的闲置机器进行并行处理,最后再合并每台机器的子文件处理结果,得到 1 GB 的 .txt 文件最终的词频统计结果
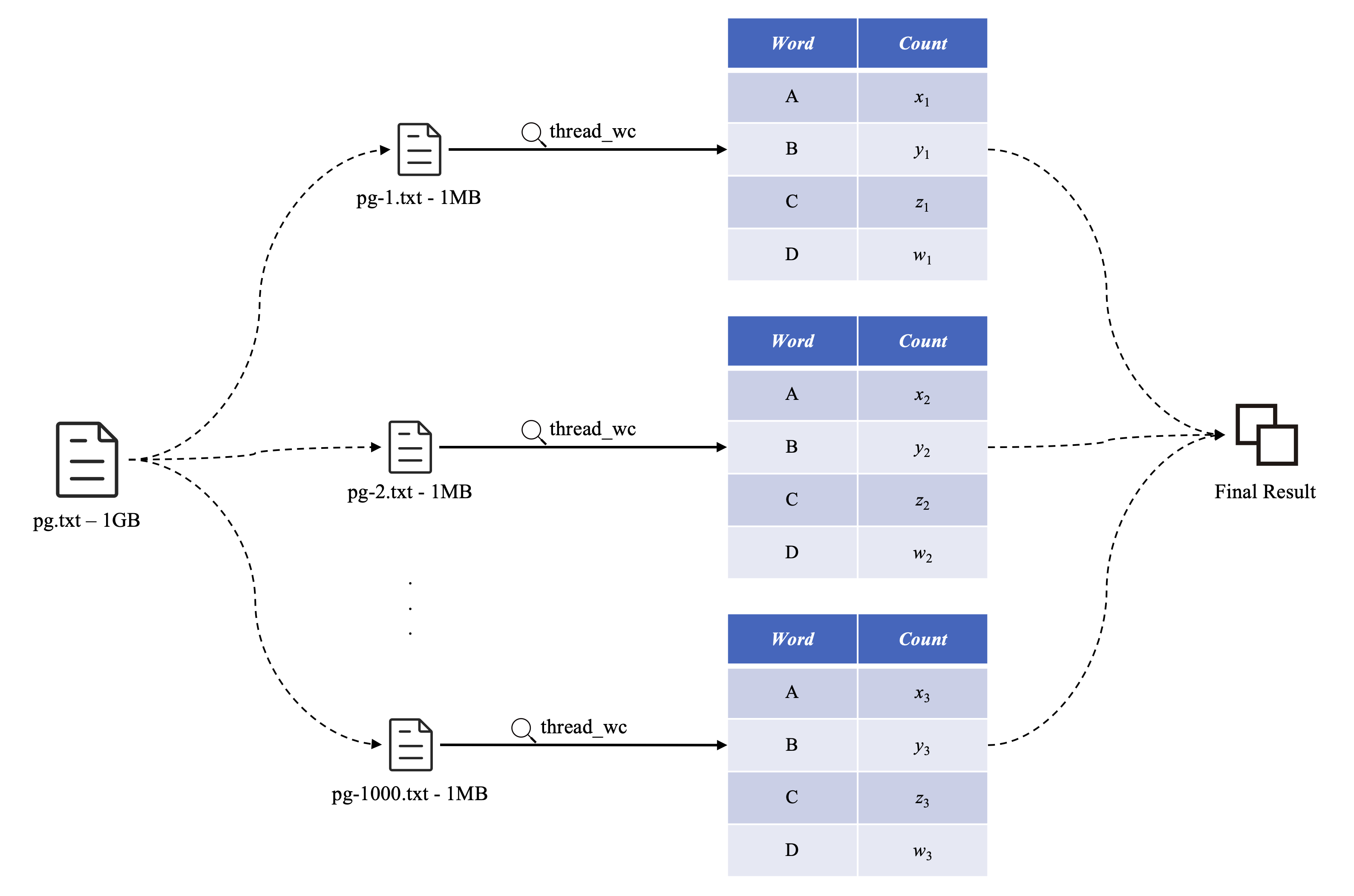
这是个不错的主意,是分布式计算模式的雏形。虽然这种方法可行,但是还是不够快,没有将分布式的特点发挥到淋漓尽致
其实,我们完全可以针对上述词频统计问题进行再一次的划分,把词频统计任务分为单词输出任务( MapTask )和单词计数任务( ReduceTask ),先扫描 .txt 执行输出任务,在明确有哪些单词之后,再执行计数任务,最后合并结果
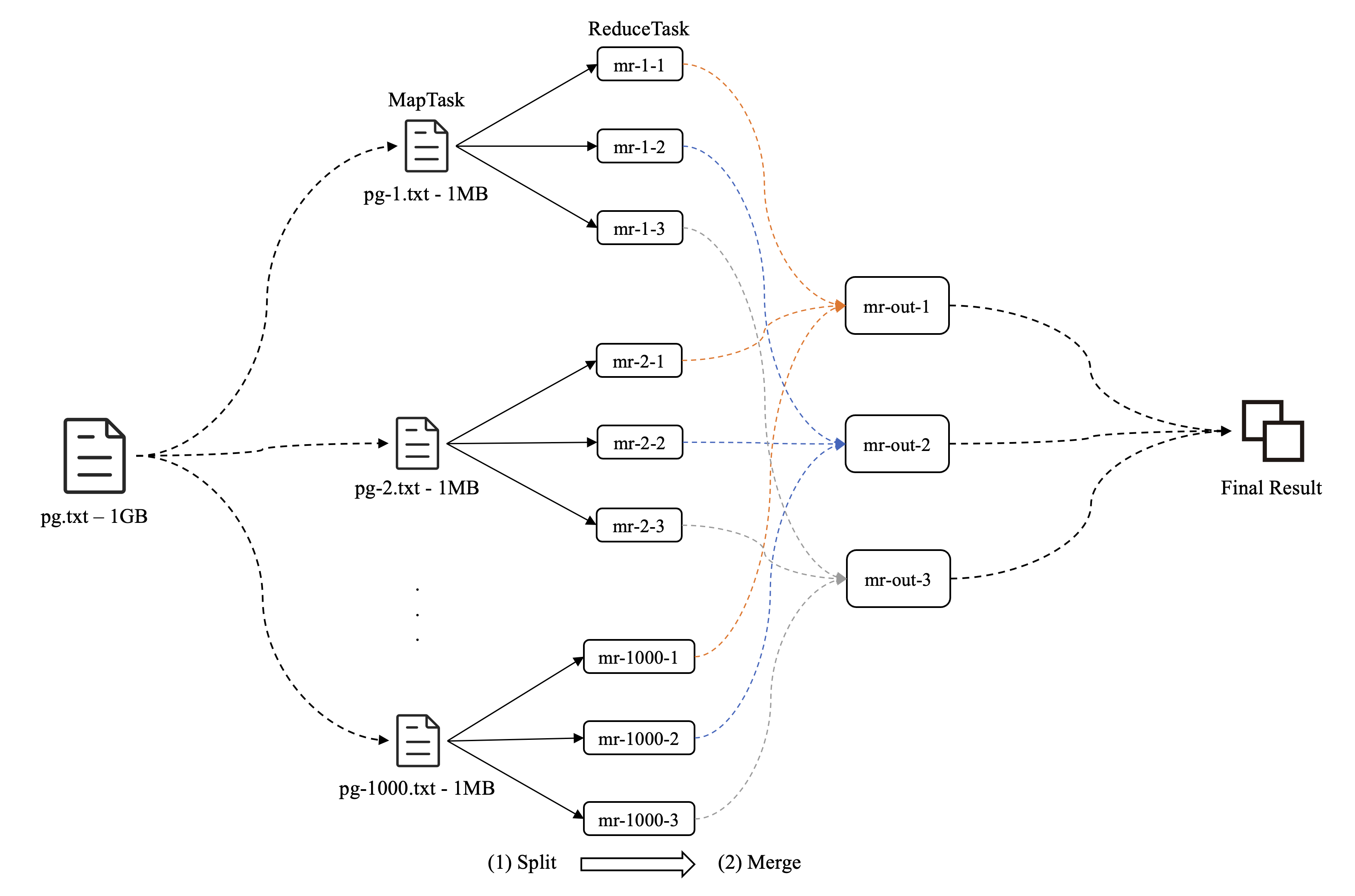
如此设计,简化了业务逻辑,明确了分工,同时也大大提高了产出(解析)效率
IV. Solution
我们知道了 MapReduce 是什么以及它可以解决什么样的问题后,就可以开始动手设计与实现这套流程了
因为 6.824-golabs-2020 采用的是 Go 语言,所以我们还需要有点 Go 的基础,特别是 goroutine 的知识,如果学习过 C 语言,那么掌握 Go 还是比较容易的
当然,如果想深入理解 Go ,特别是它的内存机制( slice、map、channel 以及深浅拷贝...),那么还需要花大精力的
Lab1: MapReduce 实验主页 给出的提示还是比较清晰明了的,我来大致提炼一下。MapReduce 模型由两个角色组成,分别是 Master 和 Worker ,如果想玩转 MapReduce ,那么模型中至少有一个 Master 和一个 Worker
在现实世界中,MapReduce 分布式计算模式都是运行在不同机器上的,即都是远程的。但 6.824-golabs-2020 为了方便起见,用多进程来模拟分布式的效果,同样也是通过 RPC(远距离过程调用,Remote Process call)来实现各对象之间的通信
Your job is to implement a distributed MapReduce, consisting of two programs, the master and the worker. There will be just one master process, and one or more worker processes executing in parallel. In a real system the workers would run on a bunch of different machines, but for this lab you'll run them all on a single machine. The workers will talk to the master via RPC.
下面是重点,为了方便起见,实验采用了 Worker 主动的通信策略,即是 Worker 不停地向 Master 要任务,Worker 拿到任务后开始工作,最后再将结果交给 Master 汇总
Each worker process will ask the master for a task, read the task's input from one or more files, execute the task, and write the task's output to one or more files. The master should notice if a worker hasn't completed its task in a reasonable amount of time (for this lab, use ten seconds), and give the same task to a different worker.
这样的通信模式确实很简洁,因为 Master 无需知道 Worker 的存在,也无需知道每一次与它通信的 Worker 的相关信息。总之,Master 什么都不需要知道,更不需要维护 Worker 列表
Master 只要做一件事,那就是开机,响应 Worker 的任务请求。需要实现的业务逻辑就是分配任务( assign task )和汇总结果( gather result )
另外,Lab1: MapReduce 还考虑到了容错机制,即是集群中有 Worker 忽然掉线的情况,在掉线的情况下,还能保证任务的顺利完成,这也是考察的重点
Lab1: MapReduce 实验主页 给出的提示,如果 Worker1 掉线了,那么就将已经分配给它的任务再分配给其他在线的 Worker,比如 Worker2
就这么简单,唯一的难点,应该就是 Master 如何得知 Worker1 已经掉线了。这有好多种做法,有正规的、非常合理的做法,也有简单粗暴的做法
前者类似于 HTTP 的心跳包机制,即是每隔一个时间段,Master 就向 Workers 发送应答报文,如果 Worker1 没有在合理的时间内恢复,则认为它已经掉线了。这是最正确的做法,但是也是最烦人的做法。如果要实现这种机制,那么 Master 就需要维护 Worker 列表,需要记下每个 Worker 的通信地址...,维护的工作又是一大笔开销,有舍有得!
我采用的是后者,即 Master 仍然不需要维护 Worker 列表。它自己有个计时器,如果已经分配出去的任务,在计时器结束时还没有向其交付,那么 Master 就认为该 Worker 已经掉线了
这种方法的关键点在于设置计时器的值,太大了不行,太小了更不行。说实话,该方法不是通用的方法,其时间的取值完全取决于 MapTask 和 ReduceTask 的用时。可以说,其值的设定完全靠经验
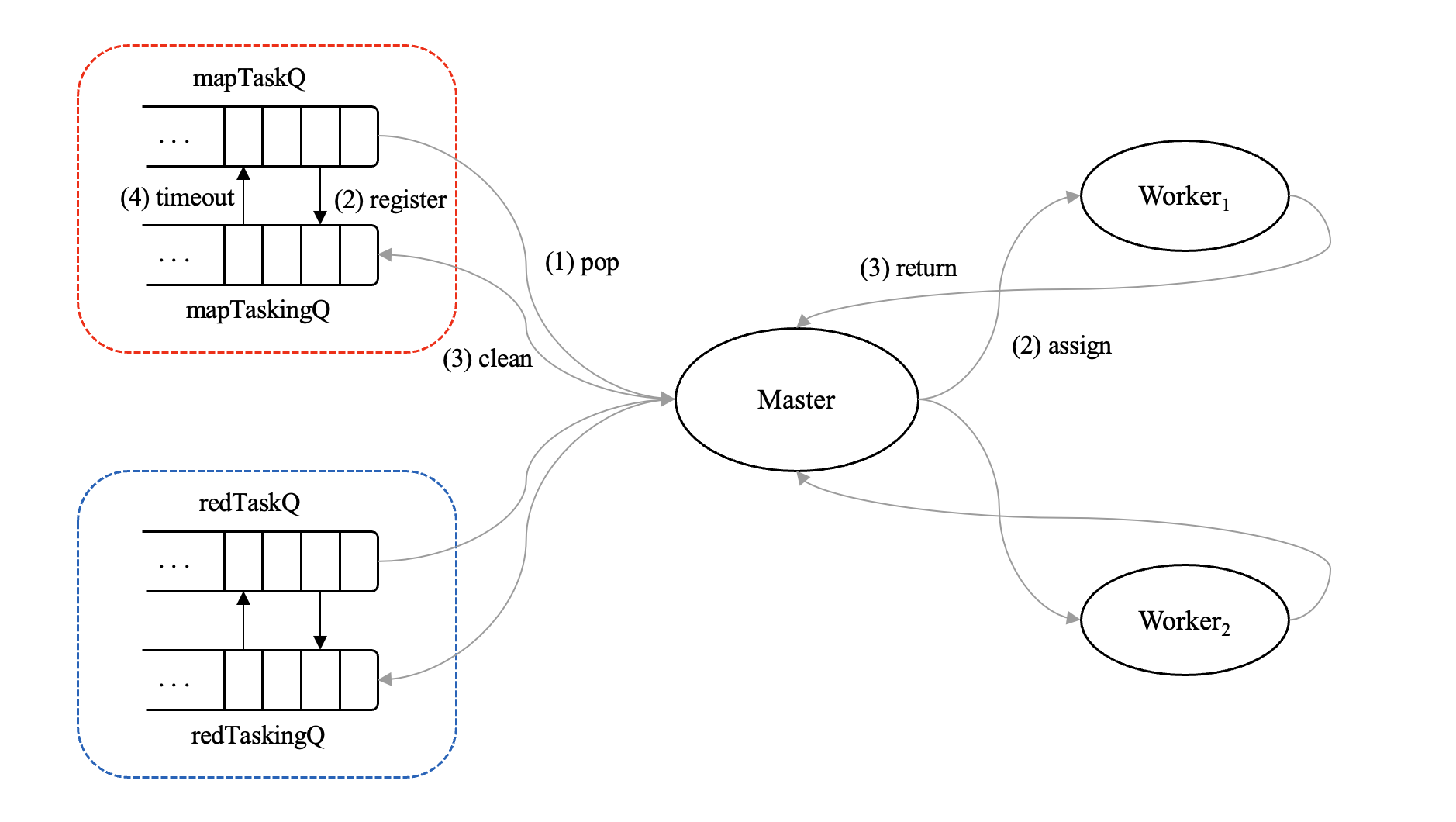
但是,从理论上来说,简单粗暴的方法也能实现容错机制。正常情况下,Master 和 Worker 之间的通信流程是这样的,

一般是 Worker 开口向 Master 要任务,接着 Master 从任务队列中挑一个任务回应;当任务都已经完成时,对应图中的最后两根虚线,Master 会向 Worker 发送信号 TaskDone ,表示已无任务需要完成,可以下班了。Worker 在收到结束回复后,关机!结束 MapReduce 流程
S1 - defs.go约定俗成
首先,在 src/mr 目录里新建 defs.go,将一些约定俗成的变量定义好,比如说信号的种类和任务的类别,分为 MapTask 和 ReduceTask,
package mr
import (
"fmt"
)
const (
TaskMap = 1
TaskReduce = 2
TaskWait = 3
TaskEnd = 4
FixedTimeOut = 15
)
/* debug 模式值为 1,release 模式值为 0 */
var Debug int
type MetaTask struct {
FileName string
FileIdx int /* File 编号 */
}
type MapTask struct {
MetaTask
NReduce int /* 要划分成多少份 ReduceTask */
}
type ReduceTask struct {
MetaTask
PartIdx int /* ReduceTask 的合并编号 */
}
func DPrintf(format string, data ...interface{}) {
if Debug > 0 {
fmt.Printf(format, data...)
}
}
信号 TaskWait 表示 Master 手头上暂时没有可以分配的任务,如果此时有 Worker 前来申请任务,那么 Master 就向其回复信号 TaskWait,让该 Worker 等等再来,等待一会说不定 Master 就会任务可以分配了。具体如何等待,我将会在 S3 - worker.go实现ask和doing Task机制 中详细展开
信号 TaskEnd 表示所有任务都已经完成了,如果此时有 Worker 前来申请任务,那么 Master 就向其回复信号 TaskEnd,Worker 收到该信号之后就会明白:已经到了下班的时刻
定义 FixedTimeOut 主要是为了容错机制,即是过了 15 秒之后,如果运行队列还有任务的话,则 Master 判定当前有 Worker 掉线了,并将处理到一半的任务重新分配给其他的 Worker,具体我会在 S4 - master.go实现assign和gather Task机制 中详细展开
Debug 和 DPrinf() 是配套的,我用其替代 fmt.Prinf() ,这样以来,调试和测试都比较方便,在执行 sh test-mr.sh 测试时,只需将变量 Debug 设为 0 即可,这样程序就不会在控制台输出一些我们不 care 的调试信息了
紧接着就是 Task 的定义,因为 MapTask 和 ReduceTask 有一些共性的地方,所以我将其提炼出来,形成了 MetaTask
在我看来,共性的部分也要适当地提炼,不能太过头。太过头了,虽然从代码角度上来说,少打了几个字符,但是易读性大打折扣。我的意思是,很多事情都是要博弈的,是要有取舍的,不要为了优雅而优雅,由心而发的那才是真本事
两类任务的共同部分是它们都需要记录下各自的文件名( FileName )和文件编号( FileIdx ),MapTask 独有的部分应该就是:它需要知道这一个 .txt 文件应该被划分成多少份 ReduceTask,对应变量 NReduce ,也对应图 3 中的 mr-x-1 的 \(x\)
而 ReduceTask 需要清楚自己是第几号分片,对应变量 PartIdx ,也对应图 3 中的 mr-1-y 的 \(y\)
S2 - rpc.go定义通信接口
Lab1: MapReduce 的 src/mr/rpc.go 中提供了一对 RPC demo,一问一答的模式,如下,
type ExampleArgs struct {
X int
}
type ExampleReply struct {
Y int
}
注意,其中的 X 和 Y 都是大写,这是 Go 规定的,结构体中首字母小写的变量相当于 C++ Class 中的 private 成员变量,其他对象是无法访问的,只有该结构体才行;反过来,大写就是 public 成员变量,是全局的
RPC 是全局下的 RPC,Worker 发出的 RPC,只有 Master 能够访问,那这个 RPC 才有存在的意义。如果改成小写 x ,那么 Master 将无权访问此 RPC ,同时它也不再通用,属于废了
我们照葫芦画瓢,AskTaskArgs 对应图 4 中的 step1. Ask Task,我这里写成了空,这是因为 Worker 只是申请任务而已,相当于举手,无需携带相关的条件信息;而 AskTaskReply 对应图 4 中的 step2. Assign Task,它是定义些变量的,这些变量主要是用来存放 Master 分配的任务信息,比如任务是何种类型( MapTask 或 ReduceTask ),如果是 MapTask,那么将通过变量 MapTask 返回任务信息;反之,利用切片 RedTasks 返回结果
package mr
import "os"
import "strconv"
// Add your RPC definitions here.
/* I. worker 向 master 要任务 */
type AskTaskArgs struct {}
/* II. master 回复 worker 的请求 */
type AskTaskReply struct {
TaskType int
MapTask MapTask
RedTasks []ReduceTask
}
/* III. worker 完成任务,将结果返回给 master */
type TaskDoneReply struct {
TaskType int
MapTask MapTask
RedTasks []ReduceTask
}
...
为什么 RedTasks 是切片呢?因为 ReduceTask 一定是由很多个小片段组成的,如果仅仅分配给 Worker 一个 mr-y-1 文件,它是不能工作,还缺少业务逻辑的其他信息,比如 mr-x-1、mr-z-1...
只有将所有的 mr-?-1 文件都分配给 Worker,它才能够开始解析,这是 MapReduce 的关键。还有一个关键的地方,即是 Reduce 流程开始之前,必须处理完所有的 MapTask
同理,TaskDoneReply 的定义也是如此,这里我就没有提炼,虽然它与 AskTaskReply 的定义相同!当然,你也可以拔高一层。TaskDoneReply 对应图 4 中的 step3. Task Done,Master 响应 Worker 的任务请求
S3 - worker.go实现ask和doing Task机制
首先,我们需要了解 Worker 工作的具体业务逻辑,即是向 Master 要任务,然后做任务,最后交任务。以此往复,一直循环地在做这件事,
看一下代码,
// main/mrworker.go calls this function.
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
for {
reply := CallAskTask()
switch reply.TaskType {
case TaskMap:
doMapTask(mapf, reply.MapTask)
break
case TaskReduce:
doReduceTask(reducef, reply.RedTasks)
break
case TaskWait:
time.Sleep(1 * time.Second)
break
case TaskEnd:
DPrintf("mission complete! I'm closing...\n")
return
default:
DPrintf("Unknown fault\n")
return
}
}
}
Worker 会调用 CallAskTask() RPC 联络 Master,向其申请任务,变量 Reply 存放任务的具体信息。接着根据任务的类别,做具体不同的解析工作,体现在代码中分别是 doMapTask() 和 doReduceTask()
如果 Worker 收到的回复是信号 TaskWait,这就说明此时 Master 手头上没有任务可供分配,需要等待一会,等待正在解析的 MapTask 完成。我在代码中用 Sleep() 的方式实现等待的效果
同理,Worker 收到信号 TaskEnd,意味着所有任务已完成,可以下班了,此时 Worker 跳出循环,结束业务逻辑
目光集中在 CallAskTask() 上,这是一个请求任务的 RPC 方法,
/* 对应 I. worker 向 master 要任务 */
func CallAskTask() AskTaskReply {
args := AskTaskArgs{}
reply := AskTaskReply{}
/* 对应 II. master 回复 worker 的请求 */
call("Master.AskTask", &args, &reply)
return reply
}
很简单,就是去调用 Master 的 AskTask() ,具体会在 S4 - master.go实现assign和gather Task机制 中讲到。需要注意的是,call() 的参数应该是 pass-by-pointer 的,因为只有这样,Master 对其的修改,Worker 才能看到,这点跟 C 语言一样
接着,我们来看一看具体的 doMapTask 业务,
/* 对应 II. 处理 master 回复的 mapTask */
func doMapTask(mapf func(string, string) []KeyValue, mapTask MapTask) {
DPrintf("doing MapTask, fileName..%v, fileIdx..%v, nReduce..%v\n",
mapTask.FileName, mapTask.FileIdx, mapTask.NReduce)
fileName := mapTask.FileName
file, err := os.Open(fileName) /* 试图打开 pg-x.txt */
if err != nil {
log.Fatalf("cannot open %v", fileName)
}
content, err := ioutil.ReadAll(file) /* 读取文件的内容 */
if err != nil {
log.Fatalf("cannot read %v", fileName)
}
file.Close()
/* 首先通过 map 方法输出每个单词,即遇到一个单词就将其压入 kvs 键值对集合中 */
kvs := mapf(fileName, string(content))
sort.Sort(ByKey(kvs))
/* 以下 map 的切片逻辑也是借鉴 src/main/mrsequential.go 的 */
reduces := make([][]KeyValue, mapTask.NReduce)
for _, kv := range kvs { /* 将集合打散,按照最大上限数,生成 NReduce 个哈希桶 */
idx := ihash(kv.Key) % mapTask.NReduce
reduces[idx] = append(reduces[idx], kv)
}
/* 只是为了模拟工作的效果,time.Sleep 尽量不与 io 操作存在与同一循环中,尤其是 io 写操作 */
//for idx, _ := range reduces {
// DPrintf("split MapTask to ReduceTask, fileName..%v, fileIdx..%v, partIdx..%v\n",
// mapTask.FileName, mapTask.FileIdx, idx)
// time.Sleep(1 * time.Second) /* 休眠久一点,为的是方便 debug */
//}
redTasks := []ReduceTask{}
for idx, reduce := range reduces { /* 将每个哈希桶中的 '单词-次数' 键值对内容保存至 mr-fileIdx-partIdx.csv 中 */
redTask := ReduceTask{
MetaTask: mapTask.MetaTask,
PartIdx: idx,
}
redTasks = append(redTasks, redTask) /* 并将桶中的内容作为 mapTask 的计算结果返回给 master */
output := "mr-" + strconv.Itoa(redTask.FileIdx) + "-" + strconv.Itoa(redTask.PartIdx) + ".csv"
file, err = os.Create(output)
if err != nil {
log.Fatalf("cannot create %v", output)
}
w := csv.NewWriter(file)
for _, v := range reduce {
w.Write([]string{v.Key, v.Value})
}
w.Flush()
file.Close()
}
DPrintf("MapTask to ReduceTask done, fileName..%v, fileIdx..%v\n", mapTask.FileName, mapTask.FileIdx)
/* 在 doMapTask 中 redTasks 才是返回结果,而 mapTask 只充作默认参数 */
CallTaskDone(TaskMap, mapTask, redTasks)
}
作为函数参数的 mapf 就是具体负责解析的程序,这是由 Lab1: MapReduce 的框架指定的,我们无需操心。我们只需要做好,除了 mapf 之外的工作,比如如何分片
我先通过一些 IO 操作,读取了指定文件的内容(第 6~15 行),接着调用 mapf 方法输出每个单词,并将其存放至 kvs 键值对集合中以及从小到大排序。其中的 ByKey() 是借鉴 src/main/mrsequential.go 的,Lab1: MapReduce 实验主页 的原话,
You can steal some code from
mrsequential.gofor reading Map input files, for sorting intermedate key/value pairs between the Map and Reduce, and for storing Reduce output in files.
/* 以下的功能函数都是从 src/main/mrsequential.go 中抄过来的 */
// for sorting by key.
type ByKey []KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
/*******************************************************************/
然后就是分片环节,其实也是借鉴 src/main/mrsequential.go 的,主要就是要将集合中的元素分成 NReduce 块,具体怎么分,我们可以调用 Lab1: MapReduce 提供的 ihash() 函数,求出哈希值(第 21~26 行)
之后,将每个子集合中的 kv 键值对写到对应的 mr-fileIdx-partIdx.csv 中,相当于保存工作结果,对应代码中的第 35~57 行
最后待完成解析 MapTask 后,调用 CallTaskDone() RPC 方法将结果交给 Master 汇总
其中的 28~33 行通过让进程休眠来模拟 MapTask 工作的场景,这在调试中非常有用,但如果要执行测试脚本,请注释掉这段话
另外,在 Go 语言里最好不要将 IO 操作与 time.Sleep() 放在同一循环中,尤其是写操作,会带来意想不到的 bug,比如写失败...
下面,再来讲讲 doReduceTask 的业务逻辑,其实和 doMapTask 大同小异,无非也是读文件内容,然后一通解析,保存结果,最后交由 Master 汇总,
func doReduceTask(reducef func(string, []string) string, redTasks []ReduceTask) {
oname := "mr-out-" + strconv.Itoa(redTasks[0].PartIdx)
ofile, _ := os.Create(oname)
defer ofile.Close()
kvs := []KeyValue{}
/* 以下 reduce 的合并逻辑也是借鉴 src/main/mrsequential.go 的 */
for _, v := range redTasks {
DPrintf("doing ReduceTask, fileName..%v, fileIdx..%v, partIdx..%v\n", v.FileName, v.FileIdx, v.PartIdx)
fileName := "mr-" + strconv.Itoa(v.FileIdx) + "-" + strconv.Itoa(v.PartIdx) + ".csv"
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("cannot open %v", fileName)
}
defer file.Close()
r := csv.NewReader(file)
context, _ := r.ReadAll() /* 读取所有编号为 partIdx 的 '单词-次数' 键值对内容 */
for _, u := range context { /* 并将其存放在 kvs 集合中 */
kv := KeyValue{Key: u[0], Value: u[1]}
kvs = append(kvs, kv)
}
//time.Sleep(2 * time.Second) /* 休眠久一点,为的是方便 debug */
}
sort.Sort(ByKey(kvs))
i := 0
for i < len(kvs) {
j := i + 1
for j < len(kvs) && kvs[j].Key == kvs[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, kvs[k].Value)
}
output := reducef(kvs[i].Key, values)
fmt.Fprintf(ofile, "%v %v\n", kvs[i].Key, output) /* 将合并结果写到 mr-out-x 中 */
i = j
}
DPrintf("ReduceTask done, fileName..%v, fileIdx..%v\n", redTasks[0].FileName, redTasks[0].FileIdx)
/* 在 doReduceTask 中只需返回将传进来的 redTasks 参数原封不动返回即可,而 MapTask{} 只充作默认参数 */
CallTaskDone(TaskReduce, MapTask{}, redTasks)
}
其中的合并过程也是借鉴 src/main/mrsequential.go 的(第 30~45 行)。值得注意的是,休眠模拟的工作场景这次我是放在循环里的,因为这与读操作不大冲突
至此,理顺了 Worker 的相关工作
S4 - master.go实现assign和gather Task机制
在 src/mr/master.go 中,MapReduce 服务开启之前,首先需要创建 Master 对象,
// create a Master.
// main/mrmaster.go calls this function.
// nReduce is the number of reduce tasks to use.
func MakeMaster(files []string, nReduce int) *Master {
m := Master{}
// Your code here.
m.mapTaskingQ = make([]MapTask, 0)
m.nReduce = nReduce
for i, file := range files {
task := MapTask{
MetaTask: MetaTask{
FileName: file,
FileIdx: i,
},
NReduce: nReduce,
}
m.mapTaskQ = append(m.mapTaskQ, task)
}
m.isDone = false /* 请勿关闭 Master 服务 */
DPrintf("Master working...\n")
go m.tasking2task()
m.server()
return &m
}
第 9~20 行,初始化 Master 的 MapTask 队列,根据文件名向量 files 为每个 MapTask 取名并赋上编号。其中 Master 结构如下,
type Master struct {
// Your definitions here.
mtx sync.Mutex
mapTaskQ []MapTask
redTaskQ []ReduceTask
mapTaskingQ []MapTask
redTaskingQ []ReduceTask
nReduce int
isDone bool
}
主要有四个队列,分别是 MapTask 和 ReduceTask 队列以及 MapTasking 和 ReduceTasking 队列,后两者表示正在解析的任务
为了更精确和方便地汇总 Worker 返回的结果,Master 有必要记录下已经分配出去的 Task 信息,我选用了运行队列来解决这个问题
以及最关心的切片数量,对应代码的变量 nReduce 和完成标志 isDone ,其主要用于判断 Master 是否可以关闭服务,对应 master.go:Done() ,
// main/mrmaster.go calls Done() periodically to find out
// if the entire job has finished.
func (m *Master) Done() bool {
// Your code here.
return m.isDone
}
在 src/main/mrmaster.go 中,循环不停地询问是否能够结束 MapReduce,其中的第 8 行,
func main() {
if len(os.Args) < 2 {
fmt.Fprintf(os.Stderr, "Usage: mrmaster inputfiles...\n")
os.Exit(1)
}
m := mr.MakeMaster(os.Args[1:], 10)
for m.Done() == false {
time.Sleep(time.Second)
}
time.Sleep(time.Second)
}
言归正传,讲一讲 Worker 与 Master 交互的两个重要函数,AskTask() 和 TaskDone() ,先看前者的定义,
/* 对应 II. master 接收到 worker 的请求后 */
func (m *Master) AskTask(args *AskTaskArgs, reply *AskTaskReply) error {
m.mtx.Lock()
defer m.mtx.Unlock()
if len(m.mapTaskQ) > 0 {
reply.TaskType = TaskMap
reply.MapTask = m.assignMapTask()
return nil
}
if len(m.mapTaskingQ) > 0 {
reply.TaskType = TaskWait
DPrintf("some MapTasks are not completed, please wait...\n")
return nil
}
/* 只有当所有的 mapTasks 完成后,才可以开始 reduceTask */
if len(m.redTaskQ) > 0 {
reply.TaskType = TaskReduce
redTasks := m.assignRedTask()
reply.RedTasks = append(reply.RedTasks, redTasks...)
return nil
}
if len(m.redTaskingQ) > 0 {
reply.TaskType = TaskWait
DPrintf("some ReduceTasks are not completed, please wait...\n")
return nil
}
reply.TaskType = TaskEnd
m.isDone = true
DPrintf("All tasks done, msg: closing -> worker...\n")
return nil
}
Master 在接收到申请任务的请求之后,会先在 MapTask 队列中寻找是否有合适的任务(第 6 ~11 行),有则调用 assignMapTask() 分配任务;反之,则检查一下是否有 MapTask 正在运行
如果确有其事,需要停止分配,回复 Worker 过会再来(第 13~18 行)。还记得嘛?MapReduce 的一大要点,所有 MapTask 必须在 ReduceTask 执行之前完成。这就意味着我们只能先把 MapTask 都做完,才能开始 ReduceTask
如果 MapTask 都完成了,那么开始 ReduceTask 的解析工作(第 21~27 行),同样调用 assignRedTask() 分配任务;如果还有 RedTask 正在运行,则回复 Worker 让其等待。这与之前分配 MapTask 是同样的道理
最后,如果任务都完成了,就修改变量 isDone ,告诉 src/main/mrmaster.go :可以结束 MapReduce 服务啦
其中的 assignMapTask() 的定义如下,
/* 从 mapTaskQ 任务队列里挑一个 task 分配给 worker */
func (m *Master) assignMapTask() MapTask {
task := m.mapTaskQ[0]
m.mapTaskQ = append(m.mapTaskQ[:0], m.mapTaskQ[1:]...) /* Go slice 出队操作 */
m.mapTaskingQ = append(m.mapTaskingQ, task) /* 将 task 的状态标记为正在计算中... */
DPrintf("assign MapTask, fileName..%v, fileIdx..%v, nReduce..%v\n", task.FileName, task.FileIdx, task.NReduce)
return task
}
不难理解,从 MapTask 队列中获取合适的任务(默认第一个),然后将其加入运行队列中;同理 assignRedTask() 也一样,
/* 从 redTaskQ 任务队列里挑选出编号为 partIdx 的 redTasks 分配给 worker */
func (m *Master) assignRedTask() []ReduceTask {
redTasks := make([]ReduceTask, 0) /* 把选中的 redTask 放入其中 */
partIdx := m.redTaskQ[0].PartIdx
for i := 0; i < len(m.redTaskQ); {
if m.redTaskQ[i].PartIdx != partIdx {
i++
continue
}
/* 已定位到编号为 partIdx 的 redTask */
task := m.redTaskQ[i]
m.redTaskingQ = append(m.redTaskingQ, task) /* 将其状态标记为正在计算中... */
redTasks = append(redTasks, task)
m.redTaskQ = append(m.redTaskQ[:i], m.redTaskQ[i+1:]...)
DPrintf("assign ReduceTask, fileName..%v, fileIdx..%v, partIdx..%v\n",
task.FileName, task.FileIdx, task.PartIdx)
}
return redTasks
}
只不过它是挑选编号为 partIdx 的 RedTask 而已。目光转移到 TaskDone() ,
/* 对应 III. worker 完成任务,将结果返回给 master */
func (m *Master) TaskDone(args *TaskDoneReply, reply *ExampleReply) error {
m.mtx.Lock()
defer m.mtx.Unlock()
switch args.TaskType {
case TaskMap:
m.mapTaskingQDeleter(args.MapTask, args.RedTasks)
break
case TaskReduce:
m.redTaskingQDeleter(args.RedTasks)
break
default:
break
}
return nil
}
这个 RPC 方法主要负责的即是汇总任务的工作,Worker 处理完成交给 Master,Master 收到后根据任务的类型( TaskMap 或 TaskReduce )来做相应的汇总工作。具体分为汇总 TaskMap 的 mapTaskingQDeleter() 和 TaskReduce 的 redTaskingQDeleter()
故名思义,两者都是从运行队列中移除已经完成的任务,前者的定义如下,
/* 汇总 worker 返回的 mapTask 切片结果 */
func (m *Master) mapTaskingQDeleter(mapTask MapTask, redTasks []ReduceTask) {
DPrintf("MapTask done, fileName..%v, fileIdx..%v, nReduce..%v\n",
mapTask.FileName, mapTask.FileIdx, mapTask.NReduce)
for i := 0; i < len(m.mapTaskingQ); i++ {
if m.mapTaskingQ[i].FileIdx == mapTask.FileIdx { /* 已彻底完成之前分配的 mapTask */
m.mapTaskingQ = append(m.mapTaskingQ[:i], m.mapTaskingQ[i+1:]...)
break
}
}
for _, v := range redTasks { /* 并将其转化为二阶段 reduceTask */
m.redTaskQ = append(m.redTaskQ, v)
DPrintf("add ReduceTask, fileName..%v, fileIdx..%v, partIdx..%v\n", v.FileName, v.FileIdx, v.PartIdx)
}
}
Worker RPC 方法回复的是解析后的结果,自然保存在切片 redTasks 中,以及需要根据原来的 MapTask 的文件编号,相应的也要从运行队列中移除
后者的定义,同样如此,
/* 处理 worker 返回的 redTask 合并结果 */
func (m *Master) redTaskingQDeleter(redTasks []ReduceTask) {
for i := 0; i < len(redTasks); i++ {
task := redTasks[i]
DPrintf("ReduceTask done, fileName..%v, fileIdx..%v, partIdx..%v\n", task.FileName, task.FileIdx, task.PartIdx)
for j := 0; j < len(m.redTaskingQ); { /* 将编号为 partIdx 的 reduceTask 状态标记为已完成 */
if m.redTaskingQ[j].PartIdx == task.PartIdx {
m.redTaskingQ = append(m.redTaskingQ[:j], m.redTaskingQ[j+1:]...)
continue
}
j++
}
}
}
Worker RPC 方法并没有回复解析后的结果,而是原来的 RedTasks,所以只需进行移除操作即可。解析的结果存放在临时文件 mr-out-x 中,这在 Lab1: MapReduce 实验主页 有提示,
The worker implementation should put the output of the X'th reduce task in the file
mr-out-X.
S5 - master应对crash
现在,开始讲一下 Master 最重要的 crash 应对措施,它也是测试脚本中的最后一个测试点
上面实现的方案,在 Master 和 Worker 稳定在线的情况下, 能正常工作输出结果。但在现实世界中,我们是无法保证每个实体都稳定在线的,尤其是 Worker
试想,如果有一个正在解析 MapTask 的 Worker 忽然因为电源的原因自动关机了,那么 Master 将无法如期收到处理结果。待 Master 收回其他 Worker 的解析结果后,也无法开始 RedTask 的流程,因为 MapTask 还没有全部完成
这个时候就很苦恼了,Master 仅仅因为没有集齐一小部分的 MapTask 而无法进行下面的 RedTask 流程。这就是 crash 的主要病症,该如何解决?
我采取了较为粗暴的 TimeOut 重置法,思路是这样的,Master 每隔一段时间就会检查一下 MapTask 和 RedTask 两个运行队列,如果队列中还有任务,那么就将该任务移至分配队列中
这个方法的想法挺简单的,也比较有效,但是说实话,该方法玩的是一个绝对时间,能够凑效的话,很大程度上取决 TimeOut 的时间设定和 MapTask and RedTask 的业务处理时间
它不像 HTTP 或 Raft,实时通过心跳包来检测对方是否在线,而是通过轮询的法子,而且轮询的周期不宜控制。在这我将 TimeOut 设置成了 15 sec( src/mr/defs.go ),代码如下,
/* 重新分配超时的 task */
func (m *Master) tasking2task() {
for {
time.Sleep(FixedTimeOut * time.Second)
m.mtx.Lock()
if len(m.mapTaskingQ) != 0 {
for i, _ := range m.mapTaskingQ {
m.mapTaskQ = append(m.mapTaskQ, m.mapTaskingQ[i])
}
m.mapTaskingQ = []MapTask{}
}
if len(m.redTaskingQ) != 0 {
DPrintf("redTaskingQ..%v\n", m.redTaskingQ)
for i, _ := range m.redTaskingQ {
m.redTaskQ = append(m.redTaskQ, m.redTaskingQ[i])
}
m.redTaskingQ = []ReduceTask{}
}
m.mtx.Unlock()
}
}
关于为何不选择心跳包测试对方是否还在线的法子,我在 IV. Solution 开始的地方叙述过我的观点
至此,我已经讲完了整套的 MapReduce 流程
V. Result
在测试之前,我还想补充一下,在 src/mr/master.go 中,我添加了 init() 方法,这个方法是 Go 的特色,相当于进入 main() 之前的预处理函数,是无论如何都会率先执行的,可以去了解一下,网上应该资料很多,我就不展开了
且看定义,
func init() {
/* test-mr.sh 时要将值设为 0,同时要注释掉下面的 rm 命令 */
Debug = 0
///* bash -c 表示脚本命令为接着其后的字符串内容,即 "rm -rf mr-*" 且不容忽略通配符* */
//cmd := exec.Command("/bin/bash", "-c", "rm -rf mr-*")
//err := cmd.Run() /* 删掉上次运行的 mr-out 缓存文件 */
//if err != nil {
// log.Fatal("cmd.Run() failed with %v", err)
//}
}
我做的就是控制是否打印调试信息和关于删除临时文件的相关操作,都是用于调试的,大家视自己的情况而定
过程中的临时文件我是保存在 src/main 路径下的,在每一次 Master 启动时都会将上次运行所产生的临时文件清理掉
自己调试,我是通过 time.Sleep() 来控制流程的速度的,要不然处理的速度太快,看不清交互的细节
另外,我想说的是,多线程的程序,不比单线程,单线程在 Visual Studio 下可以通过单步跟踪的方式进入调试,可以肯定的说,这是最快的方式,比 prinf() 输出相关信息要快的多
但在多线程下,单步调试就不再适用,要让自己习惯于打桩测试,也就是 printf() ,通过这些输出信息来分析
调试一般是,先转到 src/main 路径下,
cd src/main
开一个 Master,
go run mrmaster.go pg-*.txt
编译一下词频统计插件,
go build -buildmode=plugin ../mrapps/wc.go
每一次的调试都需要重新编译插件,再开启两个 Worker,
go run mrworker.go wc.so
确定没有问题之后,可以执行测试脚本来看看是否真的没问题了,
sh test-mr.sh
VI. Evaluation
写在最后,一些我自己的感慨
其实 Go 语言对我来说,远远比不上 C/C++,我是因为 MIT 6.824 这个 Lab 才接触了这个比较坑的语言
说句难听的,不加指针的 Go 语言,程序执行的效率可能还比不上 JavaScript 等脚本语言;加上指针的 Go,代码没法看,太丑了,比 C/C++ 要丑的多
Go 我唯一觉得好用的地方就是它的 goroutine,其他的地方还是坑比较多的,不管是 IO 操作,还是 Timer 和切片哈希表,多得是,我没有一一踩完,自己可以试试
而且 Go 语言当前最好的 IDE 就是 GoLand,特别是 6.824-golabs-2020 ,这个实验框架比较怪,放在 VSCode 或 Vim 中可能识别不了相关的代码,而且不允许我们引用第三方的框架
所以,别跟自己较劲,我们的主要目标是学习分布式,而不是配置环境,选择最舒服的 GoLand 即可