devnet
\(\phi(x;\Theta)\) 输出异常分数。
\(dev(x)\) 是经过 Z-Score 之后的 分数。
正常样本的异常分数尽可能的靠近 \(\mu_\mathcal{R}\) ,异常样本的异常分数,尽可能的在边界 \(a * \sigma_\mathcal{R} + \mu_\mathcal{R}\) 右侧

PIA-WAL
-
对边缘样本的实例学习不足,可能会导致较高的假阳性。
-
提出方法用少量样本来指导对抗训练
-
应用加权生成模型生成边缘正常实例作为补充,以更好地学习正常类的特征,同时减少假阳性。
模型主要是下面两个模块
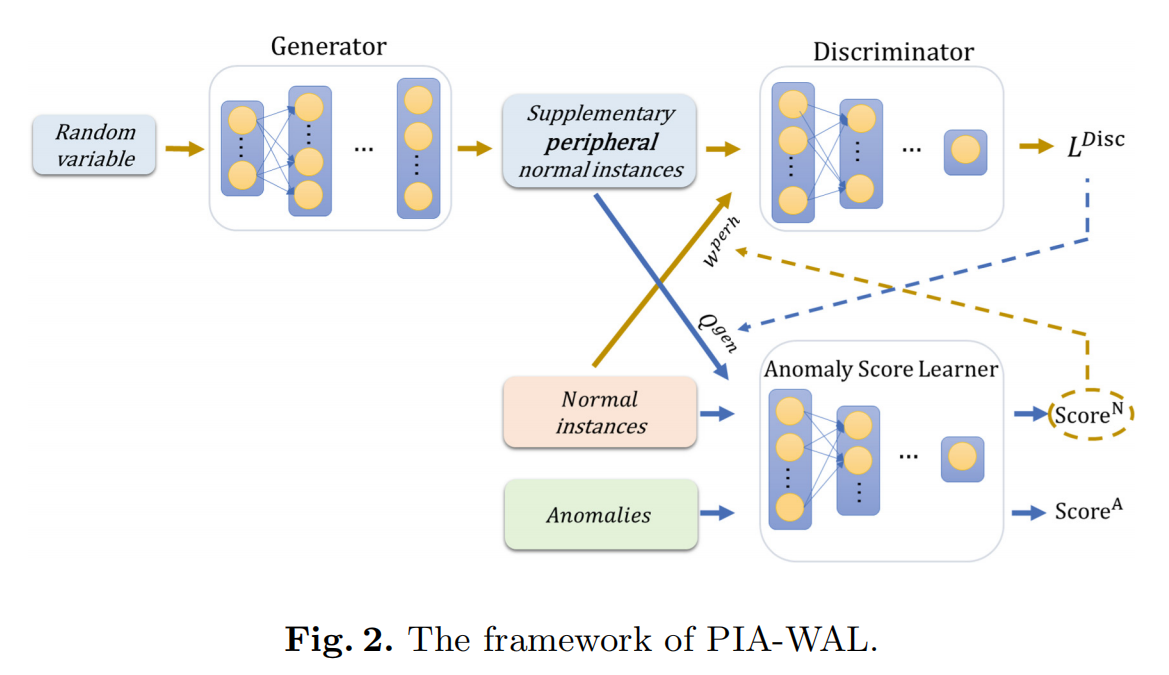
Anomaly Score Learner
用于产生异常分数。其中异常分数高的正常实例表明它可能是Learner难以检测到的外围正常实例,或者是一个噪声。因此,我们利用异常分数来指导后续生成模型的学习过程。
WGAN-GP
损失函数中涉及Learner输出的异常分数,导致外围正常样本在生成器中发挥更大的作用,目的是指导WGAN生成边缘样本。
WGAN的损失函数与生成是实例的质量存在良好的相关性,将WGAN的输出用于指导Anomaly Score Learner的学习。即生成质量较好的样本,在Learner中占的权重相对较高
Deep IForest
使用无优化深度神经网络进行表征提取,然后输入到IForest进行异常检测。
关键思想
-
利用神经网络强大的表示能力将原始数据映射到一组新的数据空间中。在这些新创建的数据空间上执行简单的轴平行分区可以很容易地实现非线性隔离(相当于在原始数据空间中不同大小的子空间上进行非线性分区)。
-
随机表征和基于随机分区的隔离之间独特的协同作用,为整个基于集合的异常估计过程带来了良好的随机性和期望的多样性。
Deep SVDD
所有样本尽可能的靠近球心 \(c\) 。主要是通过最小化所有数据表示到中心的平均距离来收缩球。
Deep SAD
无标签样本靠近球心 \(c\),异常样本以倒数的形式远离球心 \(c\)。
Kernel-based
使用labeled anomaly来矫正 无标签数据中的异常样本带来的影响
ECOD
以表格数据为例。假设各个维度都是独立同分布的。
对于单个维度,计算该维度上的ECDF。
- 考虑左尾ECDF,即 \(\widehat{F}^{(j)}_{left}(z):=\frac{1}{n}\sum_{i=1}^n{\mathbb{1}\{X_i^{(j)} \leq z \}}\ \ \ \ \ for\ z \in\mathbb{R}\)
- 考虑右尾ECDF,即 \(\widehat{F}_{right}^{(j)}(z):=\frac{1}{n}\sum_{i=1}^n{\mathbb{1}\{X_i^{(j)} \geq z \}}\ \ \ \ \ for\ z \in\mathbb{R}\)
对于一个样本,计算它的三种异常分数,以对数的方式进行累加:
-
只考虑左尾。\(O_{\text {left-only }}\left(X_i\right):=-\log \widehat{F}_{\text {left }}\left(X_i\right)=-\sum_{j=1}^d \log \left(\widehat{F}_{\text {left }}^{(j)}\left(X_i^{(j)}\right)\right)\)
-
只考虑右尾。\(O_{\text {right-only }}\left(X_i\right):=-\log \widehat{F}_{\text {right }}\left(X_i\right)=-\sum_{j=1}^d \log \left(\widehat{F}_{\text {right }}^{(j)}\left(X_i^{(j)}\right)\right)\)
-
根据偏度选择左尾或右尾ECDF。
-
如果是负偏度,则左尾偏长,选择左尾ECDF
-
如果是正偏度,则右尾偏长,选择右尾ECDF
-
\[\begin{aligned} O_{\text {auto }}\left(X_i\right)=-\sum_{j=1}^d \left[\mathbb{1}\left\{\gamma_j<0\right\} \log \left(\widehat{F}_{\text {left }}^{(j)}\left(X_i^{(j)}\right)\right) +\mathbb{1}\left\{\gamma_j \geq 0\right\} \log \left(\widehat{F}_{\text {right }}^{(j)}\left(X_i^{(j)}\right)\right)\right] \end{aligned} \]
-
最后考虑最大的作为异常分数 \(O_i=\max\{O_{\text{left-only}}(X_i),O_{\text{right-only}}(X_i),O_{\text{auto}}(X_i) \}\)
Real NVP
给定一个观测数据变量 \(x \in X\)。一个隐变量 \(z \in Z\) 上的简单先验概率分布 \(p_Z\),一个双射 \(f:X\rightarrow Z(g = f^{-1})\),变量变换公式定义了 \(x\) 上的模型分布:
其中 \(\frac{\partial f(x)}{\partial x^T}\) 是函数 \(f\) 关于 \(x\) 的的雅克比矩阵
在隐空间中绘制了一个样本 \(z \sim p_Z\),它的逆的像 \(x=f^{-1}(z)=g(z)\) 生成了一个原空间的样本。计算点 \(x\) 上的密度,可以通过计算它的像 \(f(x)\) 密度并乘以相关的雅克比行列式 $ \text{det} \left( \frac{\partial f(x)}{\partial x^T} \right)$ 得到。
RobustRealNVP
Real NVP模型估计的密度函数可能被异常破坏。因此在Real NVP的基础上,通过以下方法,增加Real NVP的鲁棒性:
- 对于存在异常的情况,根据Real NVP输出的概率大小,从小到大排序,丢弃密度概率小的样本,再用剩余的样本进行梯度下降,减小异常样本的影响。
- 为了符合Lipschitz假设,在基于流的模型中加入谱归一化,保证模型是k-smoothness的,可以解决异常聚集的情况。
MOCO
提出了动量对比(MoCo)作为一种构建具有对比损失的无监督学习的大型一致字典的方法
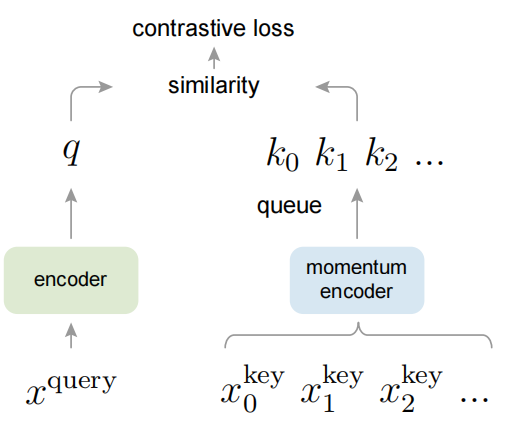
我们将字典维护为数据样本队列:当前mini-batch的编码表示入队,最旧的被踢出queue。队列将字典大小与mini-batch大小解耦,使字典能够很大。此外,由于字典键来自于前面的几个mini-batch,因此提出了一种缓慢更新的键编码器以保持一致性,具体实现为查询编码器的基于动量的移动平均,即\(\theta_k\leftarrow m\theta_k+(1-m)\theta_q\)
Prototypical contrastive learning
将对比学习与聚类相结合的无监督表示学习方法。
引入原型作为潜在变量,以帮助在EM(Expectation-Maximization)框架中找到网络参数的最大似然估计。
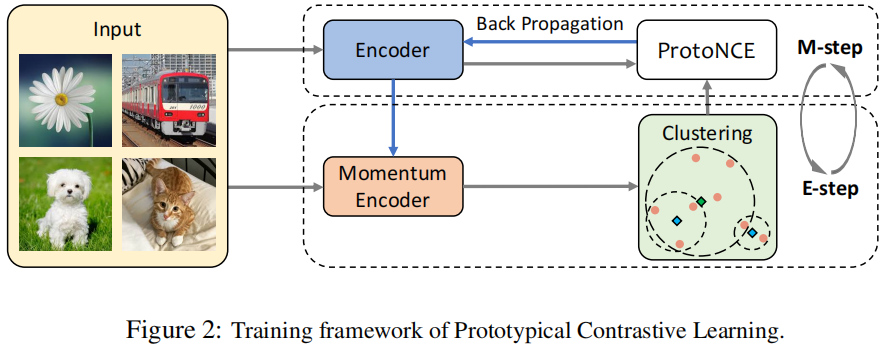
执行E步骤,即通过聚类找到原型分布;
该方法与MOCO一样,使用队列来存储之前的特征。对这些特征使用k-means进行聚类,得到其聚类中心 \(c_i\)。
执行M步骤,即通过对比学习优化网络。
主要通过下面这个损失函数,同时在 样本层级 和 类别层级 上进行对比学习
Learning Semi-supervised Gaussian Mixture Models for Generalized Category Discovery
使用原型对比学习来学习表征,使用GMM来获得更好的原型。
第一轮先用样本级别的损失函数来进行对比学习。对于学习到的表征,用k-means进行聚类。
E步:对于聚类到簇,按照一定概率对其进行拆分和合并。
M步:根据E步得到的聚类中心,使用原型对比学习来进行表征学习。
损失函数中一开始只有样本级别的对比损失函数,后续慢慢增加原型级别的对比损失函数。主要是考虑到一开始的时候,原型可能学习的不够好。
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Supervised Anomaly Detection
源码地址:https://github.com/xcyao00/BGAD
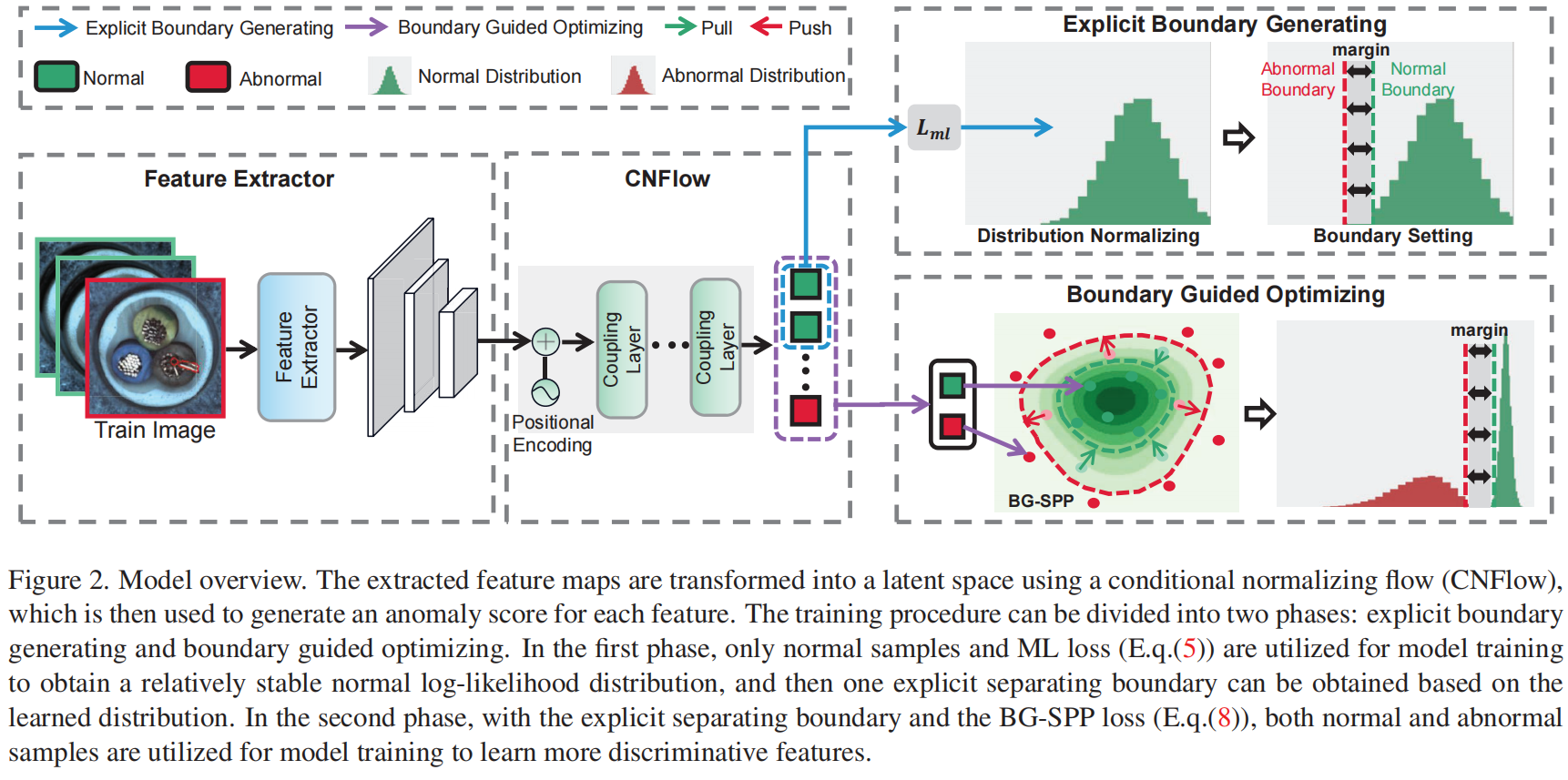
采用与 real NVP 相同的思路。利用real NVP的可逆性来对提取好的特征 \(\mathcal{X}\) 进行密度估计。
由于 CNFlow 生成的对数似然可以等效地转换为异常分数,因此在对数似然分布上选择边界。选择排序后的正常样本的对数似然分布的 \(\beta\)-th百分位数作为正常边界 \(b_n\),引入了一个边缘超参数 \(\tau\),并定义了一个异常边界 \(b_a=b_n - \tau\) 。
利用边界 \(b_n\) 作为对比目标,只将对数似然小于 \(b_n\) 的正常特征拉到一起(半拉),而将对数似然大于 \(b_a\) 的异常特征推到 \(b_n\) 之外至少超过边界 \(\tau\) (半推)。
半推拉的方式,一定程度上缓解了labeled anomaly导致的模型biases。
Anomaly Detection with Score Distribution Discrimination
源码地址:https://github.com/Minqi824/Overlap
直接优化分数的分布,让正常样本与异常样本的分数分布重合的区域尽可能的小。
先使用kde来估计正常样本和异常样本的分数分布。
然后使用下面这个公式来计算任意分数分布的重叠区域,同时确保异常分数的正确顺序。
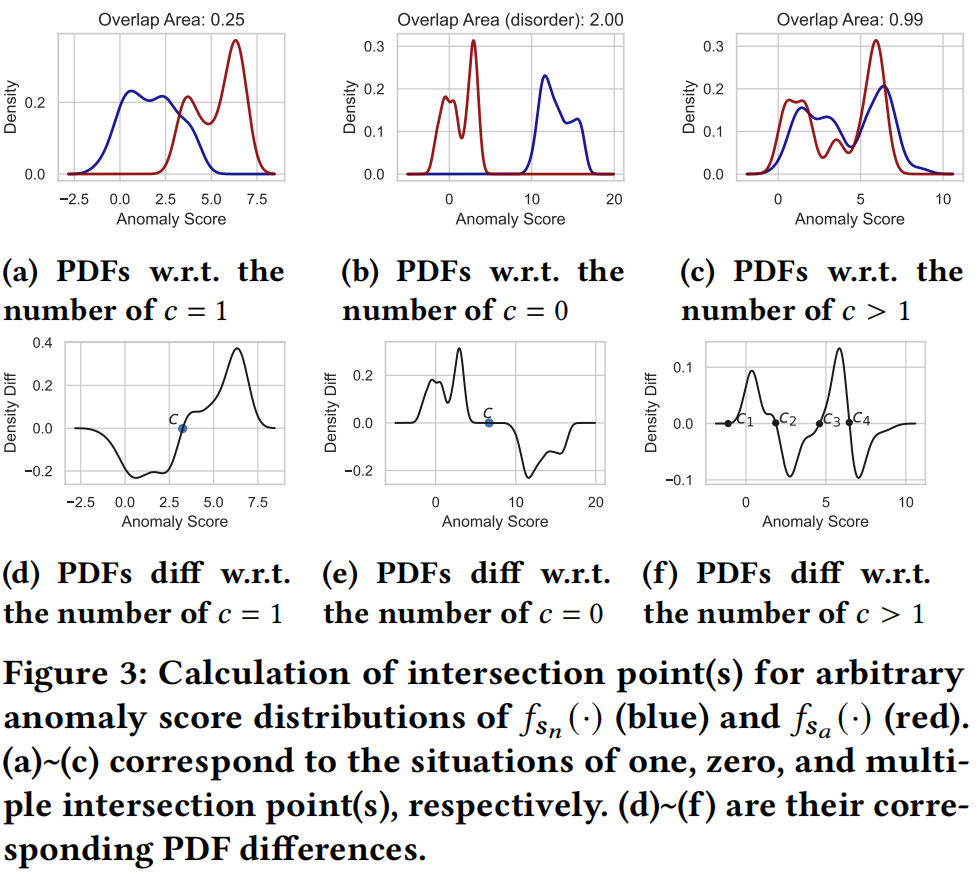
其中 \(c\) 为两个分布的交点。当 \(c\) 存在多个的时候,我们随机选择其中一个作为 \(c\)。
通过下述公式中的非零元素 \(d_k^s\) 的相应 \(\mathrm{x}\) 值来获得交点 \(c\)。
即通过比较分数分布 \(s_a\) 和 \(s_n\) 之间的相邻点的PDF差获得交点 \(c\)。具体如下图所示
通过梯形法则近似计算 \(\mathrm{CDF}\ F_s(c)\) 的积分,如下述公式所示,其中 \(\Delta s_k\) 根据交点调整为 \(\Delta s_k=\left[c-\min \left(s_n, s_a\right)\right] / N\)。
综上所述,Overlap loss定义如下:
Anomaly detection via reverse distillation from one-class embedding
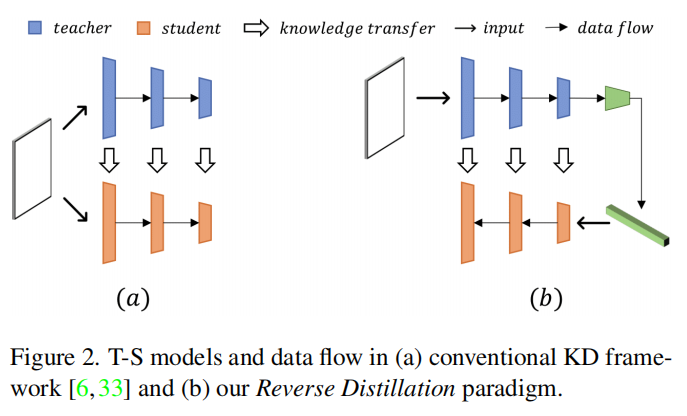
提出了反向蒸馏,使用学生网络来预测教师模型的表示。模型结构如下图所示。“反向”在这里既指的是教师编码器和学生解码器的反向形状,也指的是不同的知识蒸馏顺序,其中首先蒸馏高级别表示,然后是低级别特征。
具体模型如下图所示。
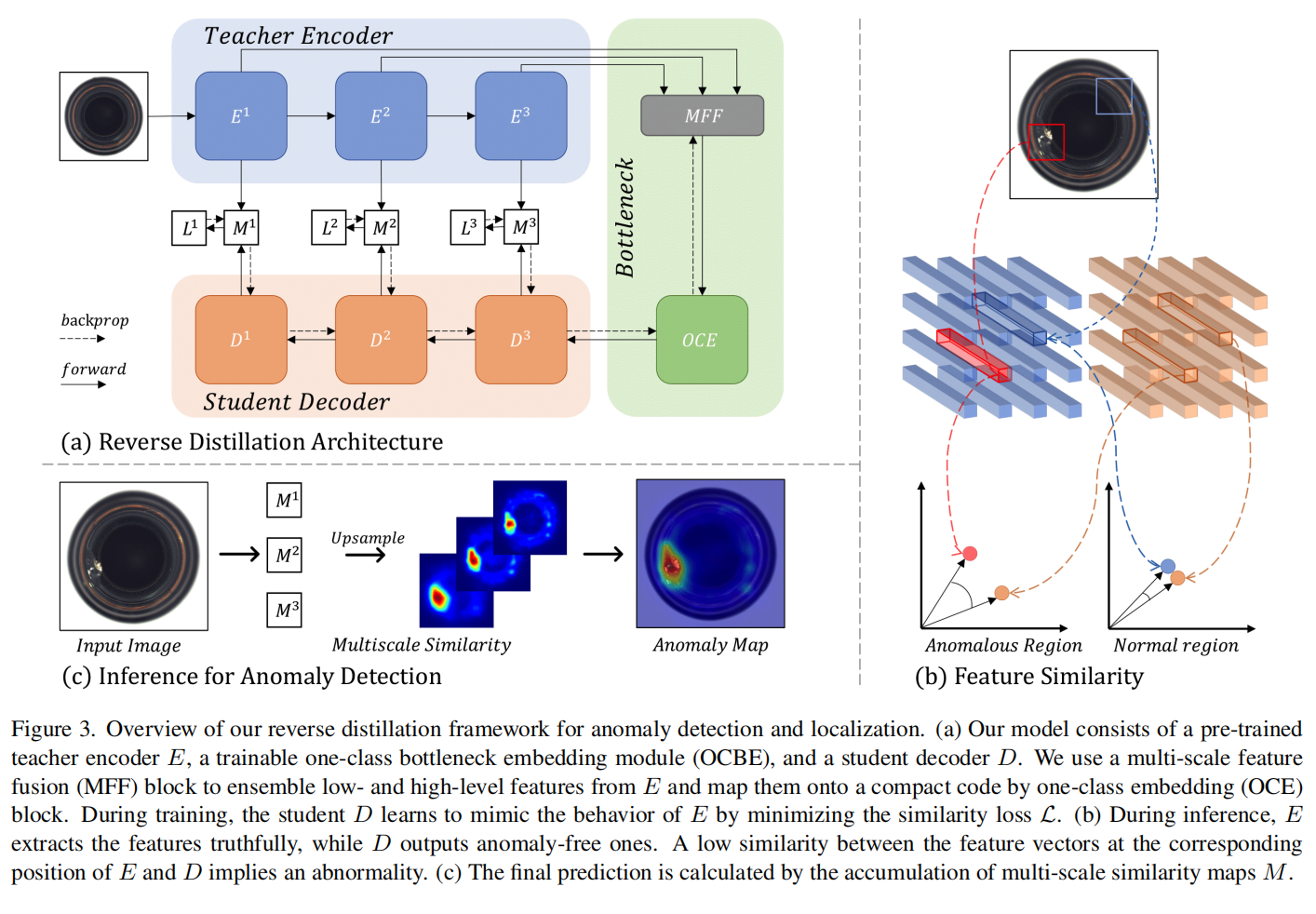
teacher E提取多尺度表征,student D从bottleneck的嵌入中还原特征。
在测试/推理过程中,教师E提取的表示可以捕获异常样本中异常的、分布外的特征。然而,学生解码器D无法从相应的嵌入中重建这些异常特征。在所提出的T-S模型中,异常表征的低相似性意味着较高的异常得分。
在第 \(k\) 层上的2-D异常图 \(M^k \in \mathbb{R}^{H_k \times W_k}\) 计算方式如下:(详情参考原论文)
学生优化的标量损失函数通过累积多尺度异常图得到。
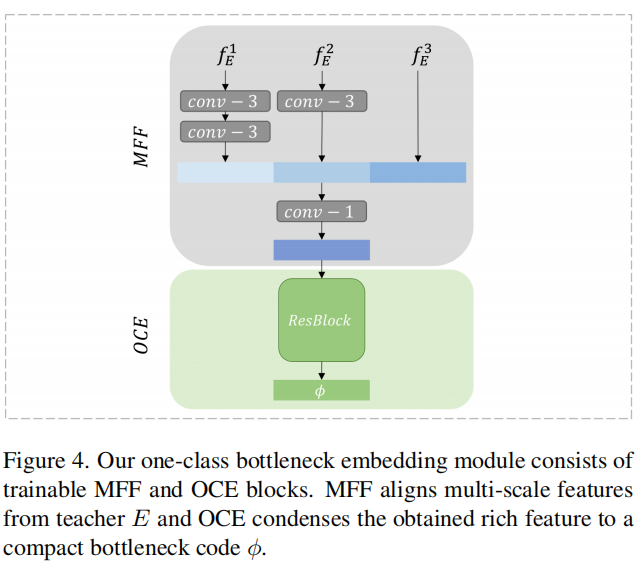
One-Class Bottleneck Embedding
- Teacher模型的输出可能包含较多的信息,存在较多的冗余,对于学生模型来解码关键的无异常特征是有害的。为了解决该问题,使用One-Class Bottleneck Embedding,将教师模型的高维表示投影到低维空间。同时这个紧凑的嵌入块充当了信息瓶颈,有助于阻止不寻常的扰动传播到学生模型,从而增强了T-S模型对异常的表示差异
- 为了解决解码器D中低级特征恢复的问题,MFF块在进行one-class嵌入之前将多尺度表示进行拼接。为了在拼接特征中实现表示对齐,我们通过一个或多个步长为2的3×3卷积层对浅层特征进行降采样,然后进行batch normalization和ReLU激活函数。接下来,我们利用一个步幅为1的1×1卷积层和一个带有ReLU激活的批量归一化层,以获得富含信息但紧凑的特征。
具体如下图所示
Anomaly Detection under Distribution Shift
源码地址:https://github.com/mala-lab/ADShift
该论文在《Anomaly detection via reverse distillation from one-class embedding》的基础上进行改进。
针对分布漂移的异常检测,generalized normality learning (GNL)
图3描述了我们方法的两个主要组成部分:(a)用于训练的分布不变正常性学习,以及(b)测试时间增强方法。
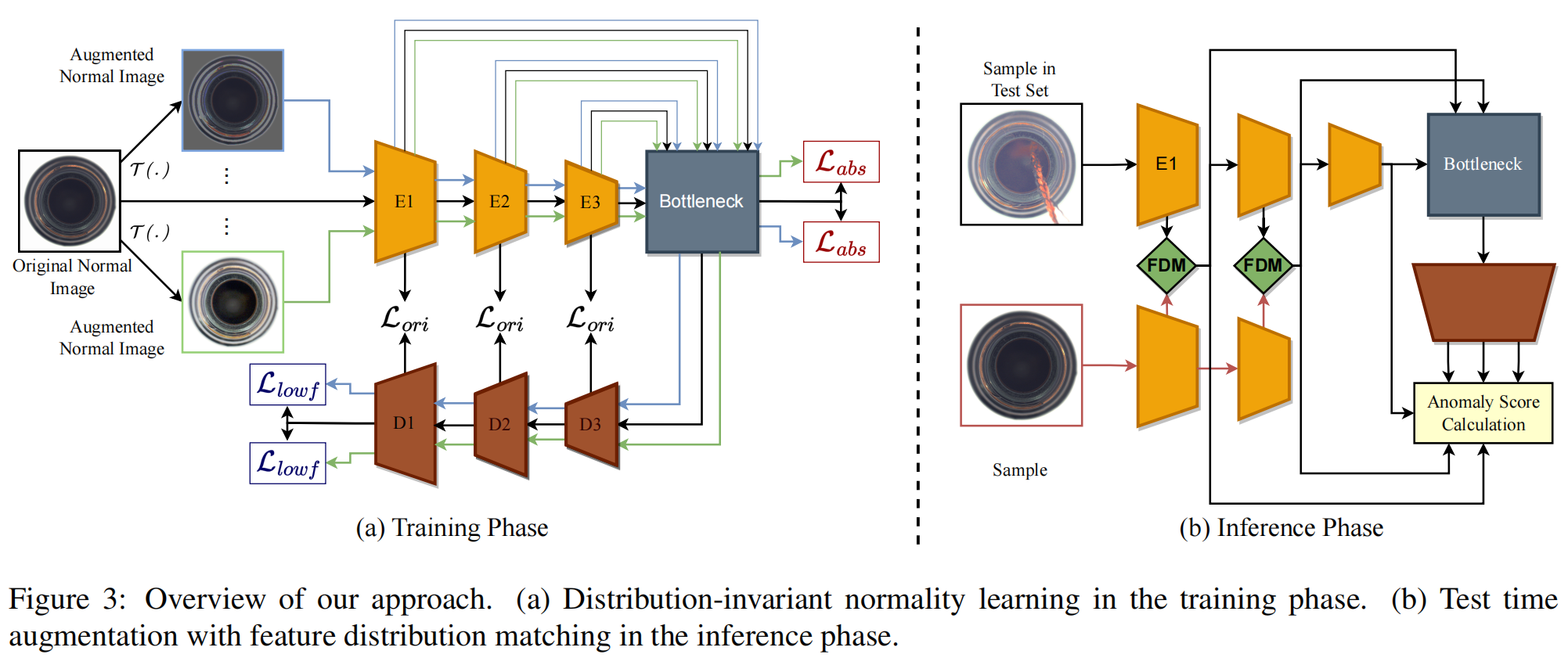
Distribution-invariant Normality Learning
引入一个相似性损失,用于量化原始样本的嵌入特征与每个转换过的正常样本的特征之间的差异。
损失项 \(\mathcal{L}_{\text{abs}}\) 添加在编码器的瓶颈层。对于增强后的样本 \(x'_k\) 和 原始样本\(x\) ,要求其在瓶颈层的输出相似。其中\(\mathcal{L}_{\text{sim}}(.,.)\)是一种基于余弦相似性的损失函数。
损失项 \(\mathcal{L}_{lowf}\) 添加在学生解码器架构的最终块中。\(\omega\) 表示从抽象特征到解码器最终块的低级特征的重构函数。
最终损失函数为
其中\(\mathcal{L}_{O r i}\)是RD4AD的原始损失,\(\lambda_{\text {Ori }}, \lambda_{a b s}\)和\(\lambda_{\text {lowf }}\)是确定每种损失函数应该给予多少权重的超参数。
Test Time Augmentation for Anomaly Detection under Distribution Shift
这个组件的目标是解决测试期间数据分布不匹配的问题。为了实现这一目标,我们提出在推断阶段的教师编码器的多层级层面上使用特征分布匹配(FDM)将训练分布注入到推断样本中。
给定一个测试样本\(p \in \mathcal{D}_t\),我们随机选择一个来自训练正常样本集\(\mathcal{D}_s\)的样本\(q\)。样本\(q\)在传递与训练数据相关的分布信息方面发挥作用。
然后将这两个样本送入教师编码器。让\(\mathcal{P}^m\)和\(\mathcal{Q}^m\)分别表示\(p\)和\(q\)在残差编码块\(E^m\)中的嵌入特征,然后进行以下测试过程:
其中,\(m \in\{0,1\}\),\(\alpha\)是一个用于平衡推断样本和选择的正常样本之间样式混合强度的超参数。处理后的嵌入特征\(\mathcal{P}^1\)和\(\mathcal{P}^2\)然后输入到瓶颈层,并参与计算与原始RD4AD的推断过程相符的异常分数。
对于上述的FDM()函数,我们采用了EFDM(Exact Feature Distribution Matching),这是FDM的最先进方法。其操作如下:
其中,\(\left\{\mathcal{C}_{\tau_i}\right\}_{i=1}^n\)和\(\left\{\mathcal{V}_{\kappa_i}\right\}_{i=1}^n\)是嵌入特征\(\mathcal{C}\)和\(\mathcal{V}\)按升序排列的值。这里,\(n\)代表向量\(\mathcal{C}\)和\(\mathcal{V}\)中元素的数量。注意,\(\mathcal{C}\)是测试样本\(p\)的嵌入特征,起到携带 appearance information的作用。\(\mathcal{V}\)是从训练数据中随机抽样的正常样本\(q\)的嵌入特征,携带style information。