1.项目概述
本实例使用Transformer这个强大的特征提取工具,把英文翻译成中文。具体步骤先构建Transorformer架构,然后训练模型、评估模型,最后使用几个英文语句测试模型效果。
为便于训练,这里训练数据仅使用使用TensorFlow2上的wmt19_translate/zh-en数据集中新闻评论部分(newscommentary_v14)
2.预处理数据
如何把输入或目标输入语句转换为Transformer模型的格式?这里假设有两对语句。假设输入语句最大长度为8,不足的语句用0填补。目标语句的最大长度为10,不足的语句用0填补。英文输入语句的BOS、EOS对应索引为8271和8272。目标输入语句的BOS、EOS对应索引为4800和4801。
import os
import time
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from pprint import pprint
from IPython.display import clear_output
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
print(tf.config.list_physical_devices('GPU'))
"""
2.6.0
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
"""
"""
为了避免TensorFlow输出不必要的信息,这里将改变logging等级。在TensorFlow 2里头因为tf.logging被弃用(deprecated),可以直接用logging模块来完成这件事情。
"""
import logging
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
# 让numpy不要显示科学计数法
np.set_printoptions(suppress=True)
# 定义数据保存路径,字典存放文件等信息
output_dir = './data'
en_vocab_file = os.path.join(output_dir, 'en_vocab')
zh_vocab_file = os.path.join(output_dir, 'zh_vocab')
checkpoint_path = os.path.join(output_dir, 'checkpoints')
log_dir = os.path.join(output_dir, 'logs')
download_dir = './download'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if not os.path.exists(download_dir):
os.makedirs(download_dir)
TensorFlow推出了的“预装”数据集功能,叫做TensorFlow Datasets,可以以tf.data和NumPy的格式将公共数据集装载到TensorFlow里。
包括:音频类、图像类、结构化数据集、文本类、翻译类、视频类
每个数据集都作为DatasetBuilder公开,已知:
1.从哪里下载数据集,如何提取数据并写入标准格式;
2.如何从disk加载;
3.各类要素名称、类型等信息。
当数据集自身版本更新时,已经开始训练的数据不会变化,TensorFlow官方会采取增加新版本的方式把新的数据集放上来。有不同变体的数据集用BuilderConfigs进行配置,比如大型电影评论数据集(Large Movie Review Dataset),可以对输入文本进行不同的编码。
也可以用你自己的配置,通过tfds.core.BuilderConfigs,进行以下步骤:
1.把你自己的配置对象定义为的子类 tfds.core.BuilderConfig。比如叫“MyDatasetConfig”;
2.在数据集公开的列表中定义BUILDER_CONFIGS类成员,比如“MyDatasetMyDatasetConfig”;
3.使用self.builder_config在MyDataset配置数据生成,可能包括在_info()或更改下载数据访问中设置不同的值。

# 下载数据
tfds.list_builders()[-20:]
"""
['wmt15_translate',
'wmt16_translate',
'wmt17_translate',
'wmt18_translate',
'wmt19_translate',
'wmt_t2t_translate',
'wmt_translate',
'wordnet',
'wsc273',
'xnli',
'xquad',
'xsum',
'xtreme_pawsx',
'xtreme_pos',
'xtreme_s',
'xtreme_xnli',
'yahoo_ltrc',
'yelp_polarity_reviews',
'yes_no',
'youtube_vis']
"""
# 这里我们使用wmt19_translate数据集
tmp_builder = tfds.builder('wmt19_translate/zh-en')
pprint(tmp_builder.subsets)
"""
{Split('train'): ['newscommentary_v14',
'wikititles_v1',
'uncorpus_v1',
'casia2015',
'casict2011',
'casict2015',
'datum2015',
'datum2017',
'neu2017'],
Split('validation'): ['newstest2018']}
"""
# 为了节省空间以及训练耗时,这里只选择一个数据集
# 定义下载配置文件并下载数据
config = tfds.translate.wmt.WmtConfig(
version=tfds.core.Version('0.0.7', experiments={tfds.core.Experiment.DUMMY: False}),
language_pair=("zh", "en"),
subsets={
tfds.Split.TRAIN: ["newscommentary_v14"]
}
)
builder = tfds.builder('wmt_translate', config=config)
builder.download_and_prepare(download_dir=download_dir)
# 分割数据
train_examples, val_examples, test_examples = builder.as_dataset(split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'])
print(train_examples)
"""
<PrefetchDataset shapes: {en: (), zh: ()}, types: {en: tf.string, zh: tf.string}>
"""
# 注意数据集的中英 反了
# 查看数据结构,将这些Tensors实际储存的字符串利用.numpy()取出并译码
sample_examples = []
num_samples = 2
c = 1
for item in train_examples.take(num_samples).as_numpy_iterator():
print('-' * 10 + '第' + str(c) + '对语句' + '-' * 10)
print(item.get('en').decode())
print(item.get('zh').decode())
c += 1
sample_examples.append((item.get('zh').decode(), item.get('en').decode()))
"""
----------第1对语句----------
这种恐惧是真实而内在的。 忽视它的政治家们前途堪忧。
The fear is real and visceral, and politicians ignore it at their peril.
----------第2对语句----------
事实上,德国政治局势需要的不过是一个符合美国所谓“自由”定义的真正的自由党派,也就是个人自由事业的倡导者。
In fact, the German political landscape needs nothing more than a truly liberal party, in the US sense of the word “liberal” – a champion of the cause of individual freedom.
"""
平常遇到文本数据集都比较难搞,但是有了TensorFlow Datasets就会好办一些,包含很多文本任务,三种文本编码器:
1.ByteTextEncoder,用于字节/字符级编码;
2.TokenTextEncoder,用于基于词汇文件的单词级编码;
3.SubwordTextEncoder,用于子词级编码,具有字节级回退,以使其完全可逆,比如可以把“hello world”分为[“he”,“llo”,“”,“wor”,“ld”],然后进行整数编码。
就跟大多数NLP项目相同,有了原始的中英句子,对单词进行分词,然后为其建立字典来将每个词汇转成索引(Index)。tfds.features.text底下的SubwordTextEncoder提供非常方便的API,让我们扫过整个训练数据集并建立字典,字典大小设置为8192(即2**13)
%%time
# 创建英文语料字典
# 就跟大多数NLP项目相同,有了原始的中英句子,对单词进行分词,然后为其建立字典来将每个词汇转成索引(Index)。
# tfds.features.text底下的SubwordTextEncoder提供非常方便的API,让我们扫过整个训练数据集并建立字典,字典大小设置为8192(即2**13)
try:
subword_encoder_en = tfds.deprecated.text.SubwordTextEncoder.load_from_file(en_vocab_file)
print(f'导入已建立的字典:{en_vocab_file}')
except Exception:
print('沒有已建立的字典,重新建立。')
subword_encoder_en = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
(item.get('zh').decode() for item in train_examples.as_numpy_iterator()),
target_vocab_size=2**13
)
# 保存字典资料,便于下次使用
subword_encoder_en.save_to_file(en_vocab_file)
print(f'字典大小:{subword_encoder_en.vocab_size}')
print(f'前10个subwords:{subword_encoder_en.subwords[:10]}')
print()
"""
导入已建立的字典:./data\en_vocab
字典大小:8271
前10个subwords:[', ', 'the_', 'to_', 'of_', 'and_', 's_', 'in_', 'a_', 'is_', 'that_']
CPU times: total: 15.6 ms
Wall time: 36.9 ms
"""
sample_string = 'Shanghai is beautiful.'
indices = subword_encoder_en.encode(sample_string)
print(indices)
"""
[7899, 6210, 502, 9, 3093, 3050, 1252, 8061]
"""
# 根据索引进行还原
print("{0:10}{1:6}".format("Index", "Subword"))
print("-" * 15)
for idx in indices:
subword = subword_encoder_en.decode([idx])
print('{0:5}{1:6}'.format(idx, ' ' * 5 + subword))
"""
Index Subword
---------------
7899 Shan
6210 gha
502 i
9 is
3093 bea
3050 uti
1252 ful
8061 .
"""
%%time
# 创建中文语料字典
try:
subword_encoder_zh = tfds.deprecated.text.SubwordTextEncoder.load_from_file(zh_vocab_file)
print(f"导入已建立的字典: {zh_vocab_file}")
except Exception:
print('沒有已建立的字典,重新开始。')
subword_encoder_zh = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
(item.get('en').decode() for item in train_examples.as_numpy_iterator()),
target_vocab_size=2**13,
max_subword_length=1 # 每一个中文字就是一个单位
)
# 保存
subword_encoder_zh.save_to_file(zh_vocab_file)
print(f"字典大小:{subword_encoder_zh.vocab_size}")
print(f"前10个 subwords:{subword_encoder_zh.subwords[:10]}")
print()
"""
导入已建立的字典: ./data\zh_vocab
字典大小:4800
前10个 subwords:['的', ',', '。', '国', '在', '是', '一', '和', '不', '这']
CPU times: total: 15.6 ms
Wall time: 20.9 ms
"""
# 测试一下
sample_string = sample_examples[0][1]
indices = subword_encoder_zh.encode(sample_string)
print(sample_string)
print(indices)
"""
这种恐惧是真实而内在的。 忽视它的政治家们前途堪忧。
[10, 149, 572, 1245, 6, 385, 52, 29, 192, 5, 1, 3, 4576, 949, 438, 124, 1, 17, 123, 33, 20, 98, 1109, 1227, 856, 3]
"""
# 测试
en = "The eurozone’s collapse forces a major realignment of European politics."
zh = "欧元区的瓦解强迫欧洲政治进行一次重大改组。"
# 将文字转为索引
en_indices = subword_encoder_en.encode(en)
zh_indices = subword_encoder_zh.encode(zh)
print("[英中原文](转换前)")
print(en)
print(zh)
print()
print('-' * 40)
print()
print("[英中序列](转换后)")
print(en_indices)
print(zh_indices)
"""
[英中原文](转换前)
The eurozone’s collapse forces a major realignment of European politics.
欧元区的瓦解强迫欧洲政治进行一次重大改组。
----------------------------------------
[英中序列](转换后)
[16, 936, 11, 6, 1591, 746, 8, 223, 2229, 2435, 245, 4, 87, 1270, 8061]
[44, 201, 176, 1, 870, 202, 232, 601, 44, 91, 17, 123, 101, 37, 7, 279, 82, 18, 211, 273, 3]
"""
在处理序列数据时我们时常会在一个序列的前后各加入一个特殊的标识符(token),以标记该序列的开始与结束,而它们常有许多不同的称呼.
开始token、Begin of Sentence、BOS、
结束token、End of Sentence、EOS、
这边我们定义了一个将被tf.data.Dataset使用的encode函式,它的输入是一笔包含2个string Tensors的例子,输出则是2个包含BOS / EOS的索引序列。
# 定义编码函数
def encode(en_t, zh_t):
en_indices = [subword_encoder_en.vocab_size] + subword_encoder_en.encode(en_t.numpy()) + [subword_encoder_en.vocab_size + 1]
zh_indices = [subword_encoder_zh.vocab_size] + subword_encoder_zh.encode(zh_t.numpy()) + [subword_encoder_zh.vocab_size + 1]
return en_indices, zh_indices
en_t = next(iter(train_examples)).get('zh')
zh_t = next(iter(train_examples)).get('en')
en_indices, zh_indices = encode(en_t, zh_t)
print('英文 BOS 的 index:', subword_encoder_en.vocab_size)
print('英文 EOS 的 index:', subword_encoder_en.vocab_size + 1)
print('中文 BOS 的 index:', subword_encoder_zh.vocab_size)
print('中文 EOS 的 index:', subword_encoder_zh.vocab_size + 1)
print('\n输入为2个 Tensors:')
pprint((en_t, zh_t))
print('-' * 15)
print('输出为2个索引序列:')
pprint((en_indices, zh_indices))
"""
英文 BOS 的 index: 8271
英文 EOS 的 index: 8272
中文 BOS 的 index: 4800
中文 EOS 的 index: 4801
输入为2个 Tensors:
(<tf.Tensor: shape=(), dtype=string, numpy=b'The fear is real and visceral, and politicians ignore it at their peril.'>,
<tf.Tensor: shape=(), dtype=string, numpy=b'\xe8\xbf\x99\xe7\xa7\x8d\xe6\x81\x90\xe6\x83\xa7\xe6\x98\xaf\xe7\x9c\x9f\xe5\xae\x9e\xe8\x80\x8c\xe5\x86\x85\xe5\x9c\xa8\xe7\x9a\x84\xe3\x80\x82 \xe5\xbf\xbd\xe8\xa7\x86\xe5\xae\x83\xe7\x9a\x84\xe6\x94\xbf\xe6\xb2\xbb\xe5\xae\xb6\xe4\xbb\xac\xe5\x89\x8d\xe9\x80\x94\xe5\xa0\xaa\xe5\xbf\xa7\xe3\x80\x82'>)
---------------
输出为2个索引序列:
([8271, 16, 1150, 9, 249, 5, 1422, 2155, 191, 1, 5, 1040, 5246, 22, 38, 31, 3529, 8123, 8061, 8272],
[4800, 10, 149, 572, 1245, 6, 385, 52, 29, 192, 5, 1, 3, 4576, 949, 438, 124, 1, 17, 123, 33, 20, 98, 1109, 1227, 856, 3, 4801])
"""
你可以看到不管是英文还是中文的索引序列,前面都加了一个代表BOS的索引(分别为8271与4800),最后一个索引则代表EOS(分别为8272与4801) 但如果我们将encode函式直接套用到整个训练数据集时会产生“AttributeError: 'Tensor' object has no attribute 'numpy'”的错误信息。
这是因为目前tf.data.Dataset.map函式里头的计算是在计算图模式(Graph mode)下执行,所以里头的Tensors并不会有Eager Execution下才有的numpy属性。 解法是使用tf.py_function将我们刚刚定义的encode函式包成一个以eager模式执行的TensorFlow Op
把encode的结果转换为tf.Tensor格式的数据
目前tf.data.Dataset.map函式里的计算是在计算图模式(Graph mode)下执行,而Tensors并不会有Eager Execution下才有的numpy属性。解法是使用tf.py_function将我们刚刚定义的encode函式包转换成一个以eager模式执行的操作,即把encode的结果转换为tf.Tensor格式的数据即可。
# 将encode的结果转换为tf.Tensor格式
def tf_encode(item):
en_t = item.get('zh')
zh_t = item.get('en')
return tf.py_function(encode, [en_t, zh_t], [tf.int64, tf.int64])
tmp_dataset = train_examples.map(tf_encode)
en_indices, zh_indices = next(iter(tmp_dataset))
print(en_indices)
print(zh_indices)
"""
tf.Tensor(
[8271 16 1150 9 249 5 1422 2155 191 1 5 1040 5246 22
38 31 3529 8123 8061 8272], shape=(20,), dtype=int64)
tf.Tensor(
[4800 10 149 572 1245 6 385 52 29 192 5 1 3 4576
949 438 124 1 17 123 33 20 98 1109 1227 856 3 4801], shape=(28,), dtype=int64)
"""
# 过滤数据:为了使训练更简单一些,这里将长度超过50个token的序列都去掉
MAX_LENGTH = 50
def filter_max_length(en, zh, max_length=MAX_LENGTH):
return tf.logical_and(tf.size(en) <= max_length, tf.size(zh) <= max_length)
tmp_dataset = tmp_dataset.filter(filter_max_length)
# 验证过滤
num_examples = 0
for en_indices, zh_indices in tmp_dataset:
cond1 = len(en_indices) <= MAX_LENGTH
cond2 = len(zh_indices) <= MAX_LENGTH
assert cond1 and cond2
num_examples += 1
print(f"所有英文與中文序列長度都不超过{MAX_LENGTH}个 tokens")
print(f"训练集共有 {num_examples} 笔数据")
"""
所有英文與中文序列長度都不超过50个 tokens
训练集共有 163823 笔数据
"""
最后值得注意的是每个例子里的索引序列长度不一,这在建立batch时可能会发生问题。不过别担心,轮到padded_batch函式出场了:
# 将batch里的所有序列都pad到同样长度
BATCH_SIZE = 64
tmp_dataset = tmp_dataset.padded_batch(BATCH_SIZE, padded_shapes=([-1], [-1]))
en_batch, zh_batch = next(iter(tmp_dataset))
print("英文索引序列的 batch")
print(en_batch)
print('-' * 20)
print("中文索引序列的 batch")
print(zh_batch)
"""
英文索引序列的 batch
tf.Tensor(
[[8271 16 1150 ... 0 0 0]
[8271 3814 1559 ... 0 0 0]
[8271 44 40 ... 0 0 0]
...
[8271 103 762 ... 0 0 0]
[8271 89 642 ... 0 0 0]
[8271 103 23 ... 0 0 0]], shape=(64, 44), dtype=int64)
--------------------
中文索引序列的 batch
tf.Tensor(
[[4800 10 149 ... 0 0 0]
[4800 208 281 ... 0 0 0]
[4800 5 10 ... 0 0 0]
...
[4800 27 245 ... 0 0 0]
[4800 10 61 ... 0 0 0]
[4800 4 33 ... 0 0 0]], shape=(64, 50), dtype=int64)
"""
# 创建训练集和验证集
BATCH_SIZE = 128
BUFFER_SIZE = 5000
# 训练集
train_dataset = (train_examples
.map(tf_encode)
.filter(filter_max_length)
.cache()
.shuffle(BUFFER_SIZE)
.padded_batch(BATCH_SIZE, padded_shapes=([-1], [-1]))
.prefetch(tf.data.experimental.AUTOTUNE))
# 验证集
val_dataset = (val_examples
.map(tf_encode)
.filter(filter_max_length)
.padded_batch(BATCH_SIZE, padded_shapes=([-1], [-1])))
# 测试集
test_dataset = (test_examples
.map(tf_encode)
.filter(filter_max_length)
.padded_batch(BATCH_SIZE, padded_shapes=([-1], [-1])))
en_batch, zh_batch = next(iter(train_dataset))
print("en_batch的形状:{},zh_batch的形状:{}".format(en_batch.shape, zh_batch.shape))
print("英文索引序列的 batch样例")
print(en_batch[:2])
print('-' * 20)
print("中文索引序列的 batch样例")
print(zh_batch[:2])
"""
en_batch的形状:(128, 50),zh_batch的形状:(128, 50)
英文索引序列的 batch样例
tf.Tensor(
[[8271 208 1102 37 67 4 2 169 756 21 6084 240 1045 2159
11 6 2524 1 4 42 128 37 8 6279 636 8061 8272 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[8271 1502 1 83 4 97 4604 26 1626 122 3 26 1212 1309
8131 8060 7 2335 1236 34 5816 3586 2959 8130 13 104 67 217
1280 6631 4 7912 1491 933 6589 8061 8272 0 0 0 0 0
0 0 0 0 0 0 0 0]], shape=(2, 50), dtype=int64)
--------------------
中文索引序列的 batch样例
tf.Tensor(
[[4800 170 570 510 6 161 263 288 523 219 236 263 879 187
145 1 44 188 561 214 22 53 309 46 1 70 109 7
367 570 510 2 105 55 69 6 35 16 7 214 3 4801
0 0 0 0 0 0 0 0]
[4800 9 784 1 6 2 10 66 148 435 50 419 11 192
67 75 313 455 199 338 445 308 112 4576 13 4576 13 4576
42 26 19 542 79 15 9 26 104 292 75 3 4801 0
0 0 0 0 0 0 0 0]], shape=(2, 50), dtype=int64)
"""
3.构建Transformer模型





# 构建scaled_dot_product_attention模块
def scaled_dot_product_attention(q, k, v, mask):
"""计算注意力权重.
q, k, v 必须有匹配的维度.
参数:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
返回值:
output, attention_weights
"""
# 将`q`与`k`做点积,再scale
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32) # 获取seq_k序列长度
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk) # scale by sqrt(dk)
# 将掩码加入logits
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# 使用softmax激活函数
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
# 对v做加权平均
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
对q、k、v输入一个前馈神经网络,然后在scaled_dot_product_attention的基础上构建多头注意力模块。
# 初始化时指定输出维度及多头注意数目`d_model` & `num_heads,
# 运行时输入 `v`, `k`, `q` 以及 `mask`
# 输出与scaled_dot_product_attention 函式一样有两个:
# output.shape == (batch_size, seq_len_q, d_model)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
class MultiHeadAttention(tf.keras.layers.Layer):
# 初始化相关参数
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads # 指定要将`d_model`拆成几个heads
self.d_model = d_model # 在split_heads之前的维度
assert d_model % self.num_heads == 0 # 确保能整除或平分
self.depth = d_model // self.num_heads # 每个head里子词新的维度
self.wq = tf.keras.layers.Dense(d_model) # 分別给q, k, v 做线性转换
self.wk = tf.keras.layers.Dense(d_model) # 这里并没有指定激活函数
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model) # 多heads拼接后做线性转换
# 划分成多头机制
def split_heads(self, x, batch_size):
"""
将最后一个维度拆分为(num_heads, depth).
转置后的形状为 (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
# multi-head attention 的实际执行流程,注意参数顺序
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
# 将输入的 q, k, v 都各自做一次线性转换到 `d_model`维空间
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
#将最后一个`d_model` 维度拆分成 `num_heads` 个`depth` 维度
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# 利用广播机制(broadcasting )让每个句子的每个head的 qi, ki, vi都各自实现注意力机制
# 输出多一个表示num_heads的维度
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
# 与`split_heads` 相反,先做 transpose 再做 reshape
# 将`num_heads` 个`depth` 维度拼接成原来的`d_model`维度
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model))
# (batch_size, seq_len_q, d_model)
# 实现最后一个线性转换
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
构建Encoder及Decoder中的前馈神经网络(feed forward network)模块。
# 创建Transformer 中的Encoder / Decoder layer 都用到的Feed Forward组件
def point_wise_feed_forward_network(d_model, dff):
# 这里FFN 对输入做两个线性转换,中间加一个ReLU激活函数
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
由MHA,dropout,norm及FFN构成一个Encoder Layer模块
# Encoder有N个 EncoderLayers,而每个EncoderLayer 又有两个sub-layers即MHA & FFN
class EncoderLayer(tf.keras.layers.Layer):
# dropout rate设为0.1
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
# 一个sub-layer使用一个layer norm
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 一个sub-layer使用一个 dropout layer
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
# `dropout在训练以及测试的作用有所不同
def call(self, x, training, mask):
# 除了 `attn`,其他张量的形状都为(batch_size, input_seq_len, d_model)
# attn.shape == (batch_size, num_heads, input_seq_len, input_seq_len)
# sub-layer 1: MHA
# Encoder 利用注意力机制关注自己当前的序列,因此 v, k, q 全部都是自己
# 需要用 padding mask 来遮住输入序列中的 <pad> token
attn_output, attn = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output)
# sub-layer 2: FFN
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output)
return out2


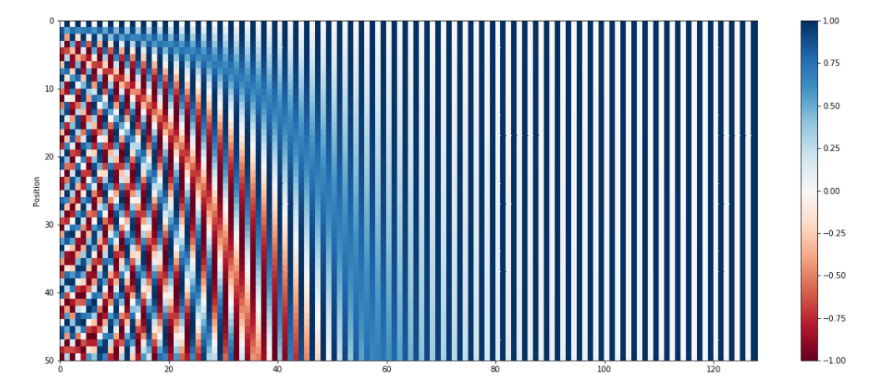
上述横坐标代表维度i,纵坐标代表位置。可以看到,对于句子长度最大为50的模型来说,前60维就可以区分位置了。至于后面为什么一白一蓝,别忘了,sin,cos相间。
我们仔细观察那个位置编码的公式可以发现,这个是绝对位置编码,即只要位置小于1万,每一个位置的编码都是不同的。
另外,其还有特点:1)奇数维度之间或者偶数维度之间周期不同。
2)也可以很好的表示相对位置信息。给定k,存在一个固定的与k相关的线性变换矩阵,从而由pos的位置编码线性变换而得到pos+k的位置编码。这个相对位置信息可能可以被模型发现而利用。因为绝对位置信息只保证了各个位置不一样,但是并不是像0,1,2这样的有明确前后关系的编码。
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis], np.arange(d_model)[np.newaxis, :], d_model)
sines = np.sin(angle_rads[:, 0::2])
cosines = np.cos(angle_rads[:, 1::2])
pos_encoding = np.concatenate([sines, cosines], axis=-1)
pos_encoding = pos_encoding[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
定义输入嵌入(Embedding)及位置编码(pos_encoding),连接n个EncoderLayer构成Encoder模块
class Encoder(tf.keras.layers.Layer):
# 参数num_layers: 确定有几个EncoderLayers
# 参数input_vocab_size: 用来把索引转换为词嵌入(Embedding)向量
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)
self.pos_encoding = positional_encoding(input_vocab_size, self.d_model)
# 创建`num_layers` 个EncoderLayers
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
# 输入的 x.shape == (batch_size, input_seq_len)
# 以下各layer 的输出都是(batch_size, input_seq_len, d_model)
input_seq_len = tf.shape(x)[1]
# 将2维的索引序列转成3维的词嵌入张量,并乘上sqrt(d_model)
# 再加上对应长度的位置编码
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :input_seq_len, :]
x = self.dropout(x, training=training)
# 通过N个EncoderLayer构建Encoder
for i, enc_layer in enumerate(self.enc_layers):
x = enc_layer(x, training, mask)
return x
DecoderLayer由MHA、Encoder输出的MHA及FFN构成
# Decoder有N个DecoderLayer,
# 而DecoderLayer有三个sub-layers: 自注意的MHA,Encoder输出的MHA及FFN
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
# 3 个sub-layer
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
# 每个sub-layer使用的LayerNorm
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 定义每个sub-layer使用的Dropout
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training, combined_mask, inp_padding_mask):
# 所有sub-layers的主要输出皆为 (batch_size, target_seq_len, d_model)
# enc_output为Encoder输出序列,其形状为 (batch_size, input_seq_len, d_model)
# attn_weights_block_1 形状为 (batch_size, num_heads, target_seq_len, target_seq_len)
# attn_weights_block_2 形状为 (batch_size, num_heads, target_seq_len, input_seq_len)
# sub-layer 1:Decoder layer需要 look ahead mask 以及对输出序列的padding mask
# 以此来避免前面已生成的子词关注到未來的子词以及 <pad>
attn1, attn_weights_block1 = self.mha1(x, x, x, combined_mask)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
# sub-layer 2: Decoder layer关注Encoder 的最后输出
# 同样需要对Encoder的输出使用用padding mask避免关注到 <pad>
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, inp_padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
# sub-layer 3: FFN 部分跟 Encoder layer 完全一样
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
Decoder layer本来就只跟Encoder layer差在一个MHA,而这逻辑被包起来以后呼叫它的Decoder做的事情就跟Encoder基本上没有两样了。
在Decoder里头我们只需要建立一个专门给中文用的词嵌入层以及位置编码即可。我们在呼叫每个Decoder layer的时候也顺便把其注意权重存下来,方便我们了解模型训练完后是怎么做翻译的。
class Decoder(tf.keras.layers.Layer):
# 初始化参数与Encoder基本相同,所不同的是`target_vocab_size` 而非 `inp_vocab_size`
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
#为中文(即目标语言)构建词嵌入层
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(target_vocab_size, self.d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
# 调用的参数与DecoderLayer相同
def call(self, x, enc_output, training, combined_mask, inp_padding_mask):
tar_seq_len = tf.shape(x)[1]
attention_weights = {} # 用于存放每个Decoder layer 的注意力权重
# 这与Encoder做的事情完全一样
x = self.embedding(x) # (batch_size, tar_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :tar_seq_len, :]
x = self.dropout(x, training=training)
for i, dec_layer in enumerate(self.dec_layers):
x, block1, block2 = dec_layer(x, enc_output, training,
combined_mask, inp_padding_mask)
# 将从每个 Decoder layer 获取的注意力权重全部存下來回传,方便后续观察
attention_weights['decoder_layer{}_block1'.format(i + 1)] = block1
attention_weights['decoder_layer{}_block2'.format(i + 1)] = block2
# x.shape == (batch_size, tar_seq_len, d_model)
return x, attention_weights
Encoder和Decoder构成Transformer
# Transformer 之上沒有其他层了,我們使用tf.keras.Model构建模型
class Transformer(tf.keras.Model):
# 初始化参数包括Encoder 和Decoder 模块涉及的超参数以及中英字典数目等
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff,
input_vocab_size, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, rate)
# 这个FFN 输出跟中文字典一样大的logits数,通过softmax后表示每个中文字出现的概率
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
# enc_padding_mask 跟 dec_padding_mask 都是英文序列的 padding mask,
# 只是一个给Encoder layer的MHA用,一个是给Decoder layer 的MHA 2使用
def call(self, inp, tar, training, enc_padding_mask,
combined_mask, dec_padding_mask):
enc_output = self.encoder(inp, training, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(
tar, enc_output, training, combined_mask, dec_padding_mask)
# Decoder 输出通过最后一个全连接层(linear layer)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attention_weights
输入: 英文序列:(batch_size,inp_seq_len)
中文序列:(batch_size,tar_seq_len)
输出: 生成序列:(batch_size,tar_seq_len,target_vocab_size)
让我们马上建一个Transformer,并假设我们已经准备好用demo数据来训练它做英翻中
# 定义掩码函数
# 先给一个样例进行测试
# 注意,反向
demo_examples = {'zh': ['It is important.', 'The numbers speak for themselves.'],
'en': ['这很重要。', '数字证明了一切。']}
pprint(demo_examples)
"""
{'en': ['这很重要。', '数字证明了一切。'],
'zh': ['It is important.', 'The numbers speak for themselves.']}
"""
batch_size = 2
demo_examples = tf.data.Dataset.from_tensor_slices(
demo_examples
)
demo_dataset = demo_examples.map(tf_encode).padded_batch(batch_size, padded_shapes=([-1], [-1]))
inp, tar = next(iter(demo_dataset))
print('inp:', inp)
print('' * 10)
print('tar:', tar)
"""
inp: tf.Tensor(
[[8271 103 9 984 8061 8272 0 0]
[8271 16 3991 5315 12 2337 8061 8272]], shape=(2, 8), dtype=int64)
tar: tf.Tensor(
[[4800 10 237 82 27 3 4801 0 0 0]
[4800 166 490 406 193 14 7 552 3 4801]], shape=(2, 10), dtype=int64)
# 定义生成掩码函数
"""
# 定义生成掩码函数
def create_padding_mask(seq):
mask = tf.cast(tf.equal(seq, 0), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :]
inp_mask = create_padding_mask(inp)
inp_mask
"""
<tf.Tensor: shape=(2, 1, 1, 8), dtype=float32, numpy=
array([[[[0., 0., 0., 0., 0., 0., 1., 1.]]],
[[[0., 0., 0., 0., 0., 0., 0., 0.]]]], dtype=float32)>
"""
# 把输入转换为Embedding向量
vocab_size_en = subword_encoder_en.vocab_size + 2
vocab_size_zh = subword_encoder_zh.vocab_size + 2
d_model = 4
embedding_layer_en = tf.keras.layers.Embedding(vocab_size_en, d_model)
embedding_layer_zh = tf.keras.layers.Embedding(vocab_size_zh, d_model)
emb_inp = embedding_layer_en(inp)
emb_tar = embedding_layer_zh(tar)
emb_inp, emb_tar
"""
(<tf.Tensor: shape=(2, 8, 4), dtype=float32, numpy=
array([[[-0.04182395, 0.01449409, 0.01069355, -0.03005066],
[-0.03116937, -0.04186185, -0.01299434, 0.03064852],
[-0.01919217, -0.02776655, 0.02810219, -0.00000649],
[ 0.03217215, -0.02296976, 0.00476924, -0.01986209],
[-0.01127541, 0.03727119, 0.0028994 , 0.03741236],
[ 0.01270341, 0.04360043, 0.02222354, -0.01921478],
[-0.01913302, -0.00351896, 0.02179058, -0.04265676],
[-0.01913302, -0.00351896, 0.02179058, -0.04265676]],
[[-0.04182395, 0.01449409, 0.01069355, -0.03005066],
[ 0.03469316, 0.0232845 , -0.01536707, 0.00159789],
[-0.03295207, 0.02939221, -0.02689996, 0.01670803],
[-0.00705422, 0.01940979, 0.03008078, -0.01318967],
[-0.04180906, 0.03664943, -0.04693525, -0.00998367],
[ 0.04463113, -0.00019956, -0.00479864, 0.03423682],
[-0.01127541, 0.03727119, 0.0028994 , 0.03741236],
[ 0.01270341, 0.04360043, 0.02222354, -0.01921478]]],
dtype=float32)>,
<tf.Tensor: shape=(2, 10, 4), dtype=float32, numpy=
array([[[ 0.04481469, -0.0270125 , 0.00897012, 0.03345258],
[ 0.03471525, 0.02038595, -0.01162243, 0.04497036],
[-0.03334796, 0.02037865, -0.03871433, 0.02199462],
[-0.02444813, 0.02508065, 0.0088293 , -0.03474721],
[ 0.00740949, 0.01969865, -0.04735444, 0.04288668],
[ 0.04755275, 0.00974827, -0.04311817, -0.04960954],
[ 0.03298051, 0.02346268, -0.02278814, -0.00174334],
[ 0.02475177, -0.03339859, 0.04745051, -0.02679628],
[ 0.02475177, -0.03339859, 0.04745051, -0.02679628],
[ 0.02475177, -0.03339859, 0.04745051, -0.02679628]],
[[ 0.04481469, -0.0270125 , 0.00897012, 0.03345258],
[ 0.02338156, -0.0038751 , 0.01051865, -0.00806693],
[ 0.00817747, 0.03387388, -0.02589376, -0.01304664],
[-0.03133773, -0.02535142, -0.02335464, -0.04836036],
[-0.01313121, 0.03987482, -0.00624017, -0.0245963 ],
[-0.02595066, 0.02681254, 0.04376345, -0.03036916],
[ 0.03004694, 0.00803242, 0.04199124, -0.01971479],
[-0.03684239, -0.00179986, -0.03862727, 0.02630795],
[ 0.04755275, 0.00974827, -0.04311817, -0.04960954],
[ 0.03298051, 0.02346268, -0.02278814, -0.00174334]]],
dtype=float32)>)
"""
# 定义对目标输入的掩码函数
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask
seq_len = emb_tar.shape[1]
look_ahead_mask = create_look_ahead_mask(seq_len)
print("emb_tar:", emb_tar)
print("-" * 20)
print("look_ahead_mask", look_ahead_mask)
"""
emb_tar: tf.Tensor(
[[[ 0.04481469 -0.0270125 0.00897012 0.03345258]
[ 0.03471525 0.02038595 -0.01162243 0.04497036]
[-0.03334796 0.02037865 -0.03871433 0.02199462]
[-0.02444813 0.02508065 0.0088293 -0.03474721]
[ 0.00740949 0.01969865 -0.04735444 0.04288668]
[ 0.04755275 0.00974827 -0.04311817 -0.04960954]
[ 0.03298051 0.02346268 -0.02278814 -0.00174334]
[ 0.02475177 -0.03339859 0.04745051 -0.02679628]
[ 0.02475177 -0.03339859 0.04745051 -0.02679628]
[ 0.02475177 -0.03339859 0.04745051 -0.02679628]]
[[ 0.04481469 -0.0270125 0.00897012 0.03345258]
[ 0.02338156 -0.0038751 0.01051865 -0.00806693]
[ 0.00817747 0.03387388 -0.02589376 -0.01304664]
[-0.03133773 -0.02535142 -0.02335464 -0.04836036]
[-0.01313121 0.03987482 -0.00624017 -0.0245963 ]
[-0.02595066 0.02681254 0.04376345 -0.03036916]
[ 0.03004694 0.00803242 0.04199124 -0.01971479]
[-0.03684239 -0.00179986 -0.03862727 0.02630795]
[ 0.04755275 0.00974827 -0.04311817 -0.04960954]
[ 0.03298051 0.02346268 -0.02278814 -0.00174334]]], shape=(2, 10, 4), dtype=float32)
--------------------
look_ahead_mask tf.Tensor(
[[0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[0. 0. 1. 1. 1. 1. 1. 1. 1. 1.]
[0. 0. 0. 1. 1. 1. 1. 1. 1. 1.]
[0. 0. 0. 0. 1. 1. 1. 1. 1. 1.]
[0. 0. 0. 0. 0. 1. 1. 1. 1. 1.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 1.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]], shape=(10, 10), dtype=float32)
"""
# 测试
num_layers = 1
d_model = 4
num_heads = 2
dff = 8
input_vocab_size = subword_encoder_en.vocab_size + 2
output_vocab_size = subword_encoder_zh.vocab_size + 2
# 预测时用前一个字预测后一个字
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
inp_padding_mask = create_padding_mask(inp)
tar_padding_mask = create_padding_mask(tar_inp)
look_ahead_mask = create_look_ahead_mask(tar_inp.shape[1])
combind_mask = tf.math.maximum(tar_padding_mask, look_ahead_mask)
# 初始化
transformer = Transformer(num_layers, d_model, num_heads, dff, input_vocab_size, output_vocab_size)
predictions, attn_weights = transformer(inp, tar_inp, False, inp_padding_mask, combind_mask, inp_padding_mask)
print("tar:", tar)
print("-" * 20)
print("tar_inp:", tar_inp)
print("-" * 20)
print("tar_real:", tar_real)
print("-" * 20)
print("predictions:", predictions)
"""
tar: tf.Tensor(
[[4800 10 237 82 27 3 4801 0 0 0]
[4800 166 490 406 193 14 7 552 3 4801]], shape=(2, 10), dtype=int64)
--------------------
tar_inp: tf.Tensor(
[[4800 10 237 82 27 3 4801 0 0]
[4800 166 490 406 193 14 7 552 3]], shape=(2, 9), dtype=int64)
--------------------
tar_real: tf.Tensor(
[[ 10 237 82 27 3 4801 0 0 0]
[ 166 490 406 193 14 7 552 3 4801]], shape=(2, 9), dtype=int64)
--------------------
predictions: tf.Tensor(
[[[ 0.06714755 0.02210751 0.02649074 ... -0.09588379 -0.08413748
0.04788114]
[ 0.06265754 0.02583148 0.04899437 ... -0.09513853 -0.06718149
0.03201686]
[ 0.05245805 0.02678581 0.06032752 ... -0.08387038 -0.04705617
0.01453761]
...
[ 0.06733222 0.02400295 0.02839489 ... -0.09616775 -0.08326343
0.04395719]
[ 0.06491998 0.02733237 0.04123614 ... -0.09561303 -0.07360026
0.03253191]
[ 0.06015977 0.02779196 0.05118706 ... -0.09172023 -0.06220304
0.02405965]]
[[ 0.06702732 0.02158592 0.02782599 ... -0.09625459 -0.08347679
0.04874738]
[ 0.06246733 0.02564452 0.04960055 ... -0.09510225 -0.06667221
0.03210702]
[ 0.05710626 0.02586092 0.05761607 ... -0.08986507 -0.05525937
0.02340729]
...
[ 0.06722847 0.02334051 0.02931567 ... -0.09647965 -0.08282962
0.04517528]
[ 0.06448303 0.02681075 0.04323987 ... -0.09573536 -0.07218384
0.03289985]
[ 0.06064662 0.02693863 0.05154229 ... -0.09274959 -0.06291922
0.02657595]]], shape=(2, 9, 4802), dtype=float32)
"""
4.定义损失函数
这里基于交叉熵定义损失函数,先定义一个含交叉熵的对象,然后定义损失函数使用该对象。
# 定义损失函数——交叉熵损失
# 如果你的输出层有一个'softmax'激活,from_logits应该是False。如果你的输出层没有'softmax'激活from_logits应该是True。
# from_logits参数是控制损失函数计算方式的一个参数。如果设置为True,则表示传入的预测结果是未经过softmax处理的,也就是logits;如果设置为False,则表示传入的预测结果已经进行了softmax处理。
# 在实际使用中,由于softmax和logits之间存在一一对应关系,因此两种方式得到的损失函数值是等价的。但从计算效率和数值稳定性来看,使用未经过softmax处理的logits更加优秀。因此,在神经网络训练中通常会直接输出模型最后一层(全连接层)的输出作为logits,并将其作为输入给交叉熵损失函数。
# 总结而言,如果模型输出已经进行了softmax操作,则需要将from_logits参数设置为False;如果模型输出未进行softmax操作,则需要将其设置为True。
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
real = tf.constant([1, 1, 0], shape=(1, 3), dtype=tf.float32)
pred = tf.constant([[0, 1], [0, 1], [0, 1]], dtype=tf.float32)
loss_object(real, pred)
"""
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.31326175, 0.31326175, 1.3132617 ], dtype=float32)>
"""
有了损失对象(loss_object)之后,还需要另外一个函式来建立掩码并加总序列里头
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
# 定义两个评估指标
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
5.定义优化器
# 定义超参数
num_layers = 4
d_model = 128
dff = 512
num_heads = 8
input_vocab_size = subword_encoder_en.vocab_size + 2
target_vocab_size = subword_encoder_zh.vocab_size + 2
dropout_rate = 0.1 # 初始值
print("input_vocab_size:", input_vocab_size)
print("target_vocab_size:", target_vocab_size)
"""
input_vocab_size: 8273
target_vocab_size: 4802
"""
动态调整学习率,并采用自适应优化器Adam
# 定义优化器
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super().__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps ** -1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98,epsilon=1e-9)
# 查看学习率变化情况
d_models = [128, 256, 512]
warmup_steps = [1000 * i for i in range(1, 4)]
schedules = []
labels = []
colors = ['blue', 'red', 'black']
for d in d_models:
schedules += [CustomSchedule(d, s) for s in warmup_steps]
labels += [f'd_model: {d}, warm: {s}' for s in warmup_steps]
for i, (schedule, label) in enumerate(zip(schedules, labels)):
plt.plot(schedule(tf.range(10000, dtype=tf.float32)), label=label, color=colors[i // 3])
plt.legend()
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")
plt.show()

6.训练模型
# 训练模型
# 实例化transformer
transformer = Transformer(num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, dropout_rate)
print(f"""这个Transformer 有 {num_layers} 层 Encoder / Decoder layers
d_model: {d_model}
num_heads: {num_heads}
dff: {dff}
input_vocab_size: {input_vocab_size}
target_vocab_size: {target_vocab_size}
dropout_rate: {dropout_rate}""")
"""
这个Transformer 有 4 层 Encoder / Decoder layers
d_model: 128
num_heads: 8
dff: 512
input_vocab_size: 8273
target_vocab_size: 4802
dropout_rate: 0.1
"""
# 设置checkpoint
run_id = f'{num_layers}layers_{d_model}d_{num_heads}heads_{dff}dff'
checkpoint_path = os.path.join(checkpoint_path, run_id)
log_dir = os.path.join(log_dir, run_id)
# tf.train.Checkpoint 把想要存下来的信息进行整合,方便存储和读取
# 保存模型及优化器(optimizer的状态
ckpt = tf.train.Checkpoint(transformer=transformer, optimizer=optimizer)
# ckpt_manager 将查看checkpoint_path 是否有 ckpt 里定义的信息
# 只保存最近5次checkpoints,其他自动刪除
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# 如果在checkpoint上发现有内容将读取
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
last_epoch = int(ckpt_manager.latest_checkpoint.split('-')[-1])
print(f'已读取最新的checkpoint,模型已训练 {last_epoch} epochs。')
else:
last_epoch = 0
print("没有找到 checkpoint,重新开始训练。")
"""
没有找到 checkpoint,重新开始训练。
"""
def create_masks(inp, tar):
# 英文句子的 padding mask,给Encoder layer自注意力机制
enc_padding_mask = create_padding_mask(inp)
# 英文句子的 padding mask,给 Decoder layer的MHA 2
# 关注Encoder 输出序列用的
dec_padding_mask = create_padding_mask(inp)
# Decoder layer 的 MHA1 在做自注意力机制用的
# `combined_mask` 是中文句子的 padding mask 跟 look ahead mask 的疊加
look_ahead_mask = create_look_ahead_mask(tf.shape(tar)[1])
dec_target_padding_mask = create_padding_mask(tar)
combined_mask = tf.maximum(dec_target_padding_mask, look_ahead_mask)
return enc_padding_mask, combined_mask, dec_padding_mask
# 定义训练模型函数
@tf.function
def train_step(inp, tar):
# 用去尾的原始序列预测下一个字的序列
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
enc_padding_mask, combind_mask, dec_padding_mask = create_masks(inp, tar_inp)
# 用去尾的原始序列预测下一个字的序列
with tf.GradientTape() as tape:
predictions, _ = transformer(inp, tar_inp, True, enc_padding_mask, combind_mask, dec_padding_mask)
loss = loss_function(tar_real, predictions)
# 使用Adam optimizer 更新Transformer 中的参数
gradients = tape.gradient(loss, transformer.trainable_variables)
optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))
# 将loss 以及训练的acc等信息保存到TensorBoard 上
train_loss(loss)
train_accuracy(tar_real, predictions)
#定义训练的循环次数
EPOCHS = 30
last_epoch=0
print(f"已训练 {last_epoch} epochs。")
print(f"剩余 epochs:{min(0, last_epoch - EPOCHS)}")
# 写入TensorBoard
summary_writer = tf.summary.create_file_writer(log_dir)
# 还要训练多少 epochs
for epoch in range(last_epoch, EPOCHS):
start = time.time()
# 重置TensorBoard的指标
train_loss.reset_states()
train_accuracy.reset_states()
# 一个epoch 就是把我们定义的训练集逐个处理
for (step_idx, (inp, tar)) in enumerate(train_dataset):
# 将数据导入Transformer,并计算损失值loss
train_step(inp, tar)
# 每个epoch 完成就存一次
if (epoch + 1) % 1 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1, ckpt_save_path))
# 將将loss 以及 accuracy 写入TensorBoard
with summary_writer.as_default():
tf.summary.scalar("train_loss", train_loss.result(), step=epoch + 1)
tf.summary.scalar("train_acc", train_accuracy.result(), step=epoch + 1)
print('Epoch {} Loss {:.4f} Accuracy {:.4f}'.format(epoch + 1,
train_loss.result(), train_accuracy.result()))
print('Time taken for 1 epoch: {} secs\n'.format(time.time() - start))
"""
Epoch 195 Loss 0.8525 Accuracy 0.4406
Time taken for 1 epoch: 43.66896605491638 secs
Epoch 196 Loss 0.8521 Accuracy 0.4407
Time taken for 1 epoch: 41.91505146026611 secs
Epoch 197 Loss 0.8521 Accuracy 0.4409
Time taken for 1 epoch: 41.02498507499695 secs
Epoch 198 Loss 0.8521 Accuracy 0.4408
Time taken for 1 epoch: 42.95865511894226 secs
Epoch 199 Loss 0.8510 Accuracy 0.4408
Time taken for 1 epoch: 42.135393142700195 secs
Epoch 200 Loss 0.8513 Accuracy 0.4409
Time taken for 1 epoch: 41.81994891166687 secs
"""
7.评估预测模型
# 定义评估函数
def evaluate(inp_sentence):
#在英文句子前后分别加上<start>, <end>
start_token = [subword_encoder_en.vocab_size]
end_token = [subword_encoder_en.vocab_size + 1]
# inp_sentence 是字符串,用Subword Tokenizer 将其变成子词的索引序列
# 在前后加上 BOS / EOS
inp_sentence = start_token + subword_encoder_en.encode(inp_sentence) + end_token
encoder_input = tf.expand_dims(inp_sentence, 0)
# Decoder 在第首先輸入是一个只包含一个中文 <start> token 的序列
decoder_input = [subword_encoder_zh.vocab_size]
output = tf.expand_dims(decoder_input, 0)
# 一次生成一个中文字并将预测加到输入再导入Transformer
for i in range(MAX_LENGTH):
# 每生成的一个字就得产生新的掩蔽
enc_padding_mask, combined_mask, dec_padding_mask = create_masks(encoder_input, output)
predictions, attention_weights = transformer(encoder_input, output, False, enc_padding_mask, combined_mask, dec_padding_mask)
# 取出序列中的最后一个distribution ,将其中最大的当做模型最新的预测字
predictions = predictions[:, -1:, :]
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)
# 遇到 <end> token 就停止回传,表示模型已生成完成
if tf.equal(predicted_id, subword_encoder_zh.vocab_size + 1):
return tf.squeeze(output, axis=0), attention_weights
#将Transformer新预测中文索引加到输出序列中,使Decoder可以产生
# 下个中文字的时候关注到最新的`predicted_id`
output = tf.concat([output, predicted_id], axis=-1)
# 将batch 的维度去掉后回传预测的中文索引序列
return tf.squeeze(output, axis=0), attention_weights
sentence = "China, India, and others have enjoyed continuing economic growth."
predicted_seq, _ = evaluate(sentence)
target_vocab_size = subword_encoder_zh.vocab_size
predicted_seq_without_bos_eos = [idx for idx in predicted_seq if idx < target_vocab_size]
predicted_sentence = subword_encoder_zh.decode(predicted_seq_without_bos_eos)
print("sentence:", sentence)
print("-" * 20)
print("predicted_seq:", predicted_seq)
print("-" * 20)
print("predicted_sentence:", predicted_sentence)
"""
sentence: China, India, and others have enjoyed continuing economic growth.
--------------------
predicted_seq: tf.Tensor(
[4800 16 4 36 380 99 8 35 32 4 33 42 945 190
165 104 292 23 54 107 84 3], shape=(22,), dtype=int32)
--------------------
predicted_sentence: 中国、印度和其他国家也享受着持续经济增长。
"""
# bad case
sentence = "China has become an economic superpower and is flexing its muscles."
predicted_seq, _ = evaluate(sentence)
target_vocab_size = subword_encoder_zh.vocab_size
predicted_seq_without_bos_eos = [idx for idx in predicted_seq if idx < target_vocab_size]
predicted_sentence = subword_encoder_zh.decode(predicted_seq_without_bos_eos)
print("sentence:", sentence)
print("-" * 20)
print("predicted_seq:", predicted_seq)
print("-" * 20)
print("predicted_sentence:", predicted_sentence)
"""
sentence: China has become an economic superpower and is flexing its muscles.
--------------------
predicted_seq: tf.Tensor(
[4800 16 4 146 23 41 15 7 30 23 54 511 538 18
4 2 42 113 5 1094 602 35 2395 1461 3], shape=(25,), dtype=int32)
--------------------
predicted_sentence: 中国已经成为一个经济超级大国,也正在逃避其肌肉。
"""
transformer.summary()
"""
Model: "transformer_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
encoder_4 (Encoder) multiple 1852032
_________________________________________________________________
decoder_4 (Decoder) multiple 1672960
_________________________________________________________________
dense_225 (Dense) multiple 619458
=================================================================
Total params: 4,144,450
Trainable params: 4,144,450
Non-trainable params: 0
_________________________________________________________________
"""
8.可视化注意力权重
# 可视化注意力权重
predicted_seq, attention_weights = evaluate(sentence)
print("sentence:", sentence)
print("-" * 20)
print("predicted_seq:", predicted_seq)
print("-" * 20)
print("attention_weights.keys():")
for layer_name, attn in attention_weights.items():
print(f"{layer_name}.shape: {attn.shape}")
print("-" * 20)
print("layer_name:", layer_name)
"""
sentence: China has become an economic superpower and is flexing its muscles.
--------------------
predicted_seq: tf.Tensor(
[4800 16 4 146 23 41 15 7 30 23 54 511 538 18
4 2 42 113 5 1094 602 35 2395 1461 3], shape=(25,), dtype=int32)
--------------------
attention_weights.keys():
decoder_layer4_block1.shape: (1, 8, 25, 25)
decoder_layer4_block2.shape: (1, 8, 25, 19)
--------------------
layer_name: decoder_layer4_block2
"""
plt.rcParams['font.sans-serif'] = 'simhei'
plt.rcParams['axes.unicode_minus'] =False
zhfont = mpl.font_manager.FontProperties(fname=r'C:\Windows\WinSxS\amd64_microsoft-windows-font-truetype-simhei_31bf3856ad364e35_10.0.22000.1_none_4a6b540478ddf6c4/simhei.ttf')
fontdict = {"fontproperties": zhfont}
plt.style.use('seaborn-whitegrid')
def plot_attention_weights(attention_weights, sentence, predicted_seq, layer_name, max_len_tar=None):
fig = plt.figure(figsize=(17, 7))
sentence = subword_encoder_en.encode(sentence)
if max_len_tar:
predicted_seq = predicted_seq[:max_len_tar]
else:
max_len_tar = len(predicted_seq)
attention_weights = tf.squeeze(attention_weights[layer_name], axis=0)
for head in range(attention_weights.shape[0]):
ax = fig.add_subplot(2, 4, head+1)
attn_map = np.transpose(attention_weights[head][:max_len_tar, :])
ax.matshow(attn_map, cmap='viridis')
ax.set_xticks(range(max(max_len_tar, len(predicted_seq))))
ax.set_xlim(-0.5, max_len_tar -1.5)
ax.set_yticks(range(len(sentence) + 2))
ax.set_xticklabels([subword_encoder_zh.decode([i]) for i in predicted_seq if i < subword_encoder_zh.vocab_size] + ['']*(18-len([subword_encoder_zh.decode([i]) for i in predicted_seq if i < subword_encoder_zh.vocab_size])), fontdict=fontdict, fontsize=18)
ax.set_yticklabels(['<start>'] + [subword_encoder_en.decode([i]) for i in sentence] + ['<end>'], fontdict=fontdict)
ax.set_xlabel('Head {}'.format(head + 1))
ax.tick_params(axis="x", labelsize=12)
ax.tick_params(axis="y", labelsize=12)
plt.tight_layout()
plt.show()
plt.close(fig)
plot_attention_weights(attention_weights, sentence, predicted_seq, layer_name, max_len_tar=18)
