- 句法图学习
- 同质图学习
- 知识图学习
- 《Improving Hyper-Relational Knowledge Graph Completion》
- 《Mask and Reason Pre-Training Knowledge Graph Transformers》
- 《Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer》
- KG-bert:《KG-BERT: BERT for Knowledge Graph Completion》
- Relphomer:《Relphormer: Relational Graph Transformer for Knowledge Graph Representations》
- COMET 和 Atomic 2020
- 总结与思考
最近两天简单看了一些用Transformer还有预训练模型做图学习的工作,主流的做法都是节点序列输入到Transformer等模型里面学习图结构,而且主要做同质/无向图的比较多,做KG的也有一些。用的模型架构也是属Transformer最多。
最先是看了一个图机器学习的一个综述:https://huggingface.co/blog/zh/intro-graphml,罗列了用Transformer做图的一些工作。
浙大的公众号上发表了GPT学习图结构化知识的一个测评:https://mp.weixin.qq.com/s/Yy9-CiDozE_PqIWTEHX7wg
主要有两点思考:
- KGTransformer输入的是采样的三元组序列,不是全局的图结构(目前的主流做法)
- LLM训练知识推理不应当是这么用的,不是直接和GPT机器人对话去令其学习图结构,而是看内部是如何训练的(有专门的工作)
句法图学习
《Graph Transformer for Graph-to-Sequence Learning》
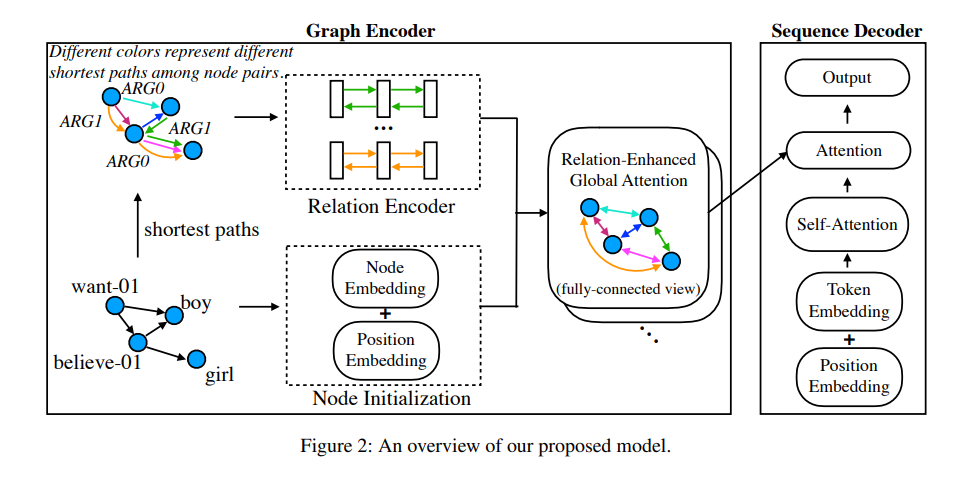
把句子转化为Levi图,也是通过聚合邻居节点信息作为当前节点的表示,和GAT一样,通过注意力计算权重。不过有几点创新的是:对图进行了全连接,可以使图上的任何两个节点互换信息,二是对把两个node之间的关系定义为其之间的最短路径,对关系进行单独编码。好奇的是它的图结构信息是以什么形式输入到模型里面的。
《Heterogeneous Graph Transformer for Graph-to-Sequence Learning》
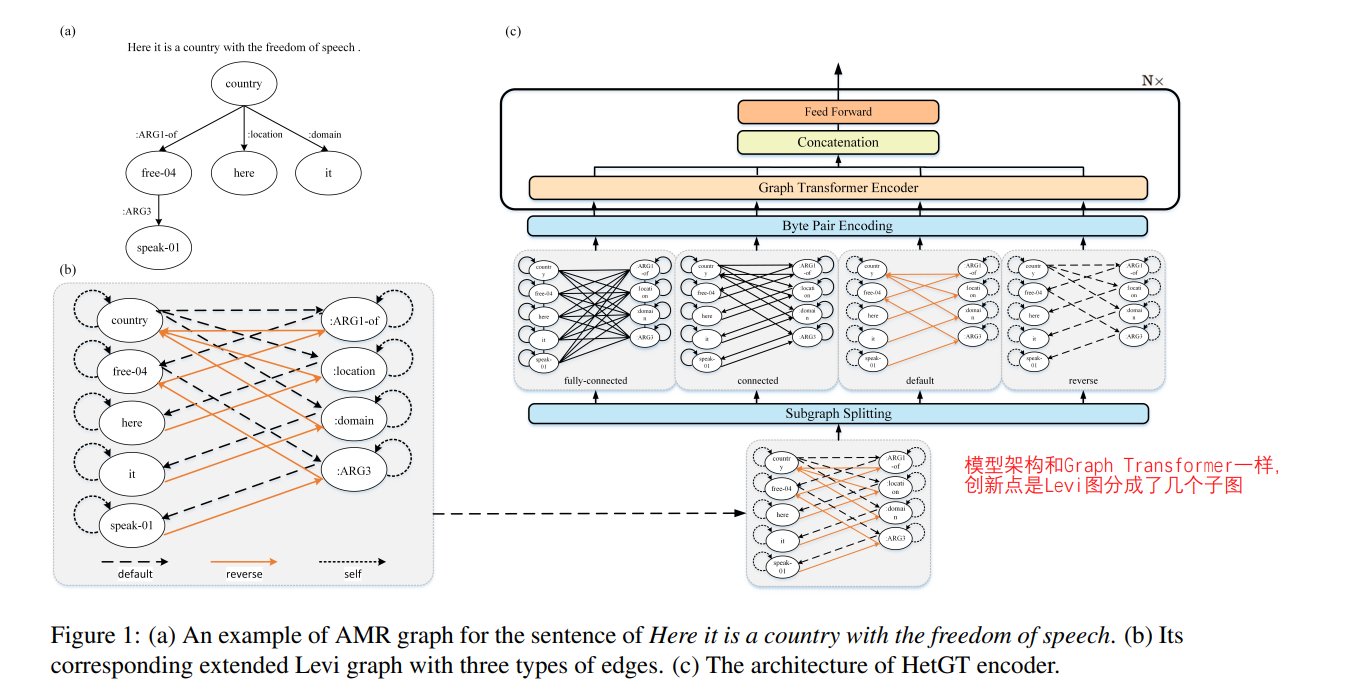
和上一篇文章做的相同的事情,创新点就是把全连接图分成几个子图:fully-connected、connected、default、reverse四个部分。模型架构没什么创新,还是用的Transformer。
推测,这种句法图应该是每个句子形成的小图,不是知识图、同质图那种整个的大图。相比之下学习起来应该是比较容易的。
同质图学习
《Do Transformers Really Perform Bad for Graph Representation?》

微软发表的 Graphormer 模型,在同质图上做attention,有几个创新点:
-
中心度编码。认为每个节点是有自身的重要程度的,比如,同一社交网络下,明星的影响力是比普通用户要大的。提出用节点的度来度量节点的中心性。
-
空间编码。编码图结构/节点的空间位置。对于每个节点对,学习一个专门的embedding(上面说的全连接),对于相连的节点,它们之间的关系定义为最短路径,用embedding与这个最短路径的相似度作为attention,如图所示。(有可能是借鉴了Levi图的做法)
《Pure Transformers are Powerful Graph Learners》
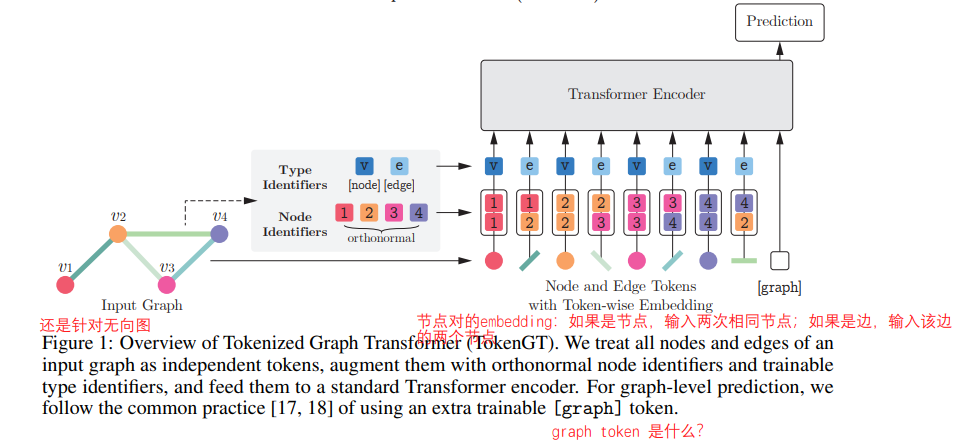
把所有的node和edge都视为独立的token,按照顺序输入到 Transformer 中。没有用GNN学习图结构。
Transformer用于同质图综述:《Transformer for Graphs: An Overview from Architecture Perspective》
把Transformer做图学习的工作分为三类:
1)GNN作为辅助模块。处理图的时候用到GNN,GNN和Transformer堆叠的方式会不一样:有GNN堆在Transformer之前的,有单次拼接再重复N次的,也有并列的。

2)改进位置编码。因为图的位置信息和序列不一样,可以用节点的度和中心性表示位置。
3)改进attention matrices。比如给图中加一些偏置项作为图的先验;或者限制某节点只能在局部邻居中传递信息。
知识图学习
《Improving Hyper-Relational Knowledge Graph Completion》

这个论文就是对STARE这个模型做了一个简化,本来STARE是GNN堆Transformer,它把GNN直接去掉了。用于 Hyper-relational 知识图谱补全。Hyper-relation 大概是在普通的关系上加了一些修饰信息,丰富了关系包含的信息量,所以叫超关系。
《Mask and Reason Pre-Training Knowledge Graph Transformers》
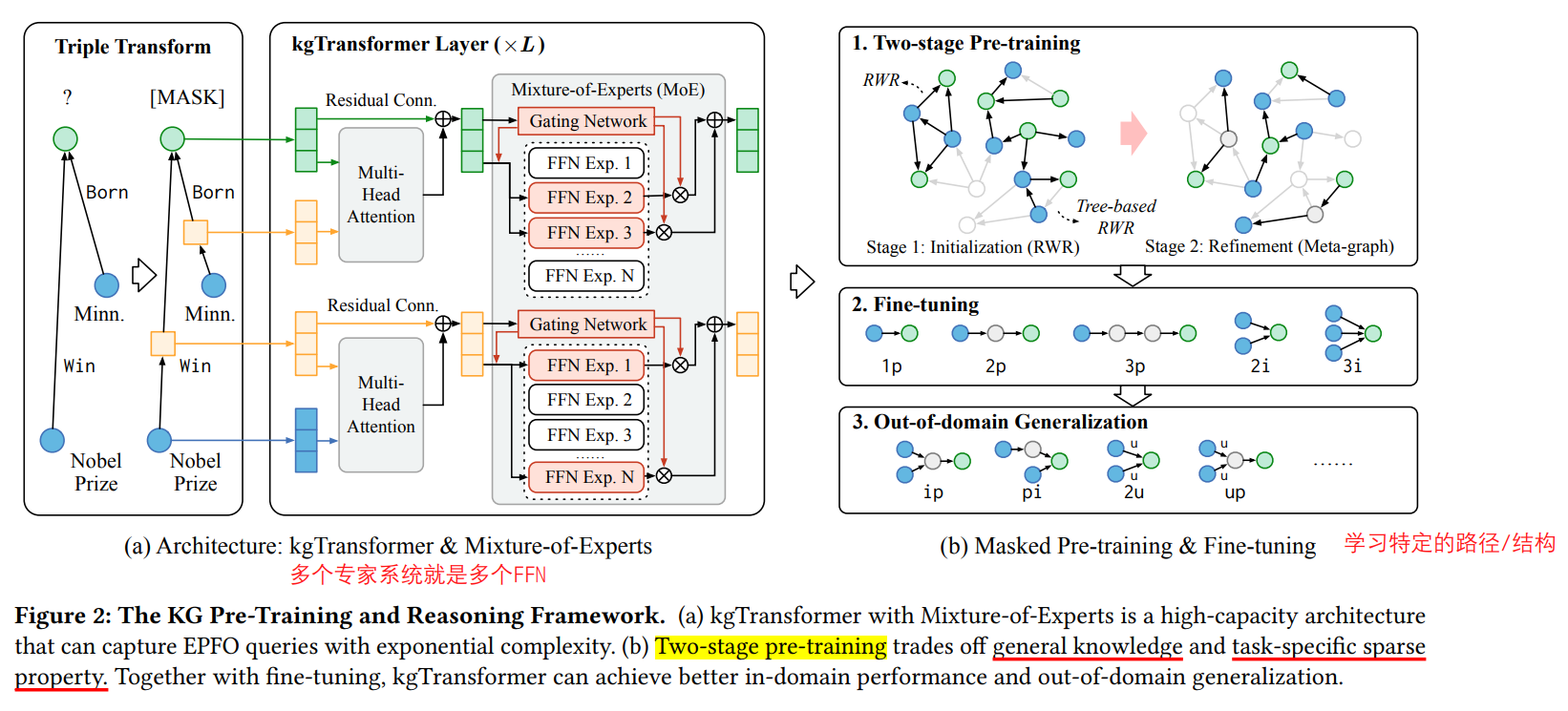
清华大学提出的 kgTransformer(这个名称的模型见过好几个了),这篇没看太懂,大概是用实体和边做attention?训练分为部分,首先是在通用的图结构上进行预训练,然后设计了几种路径结构进行fine-tuning,最后还在out-of-domain上进行泛化。
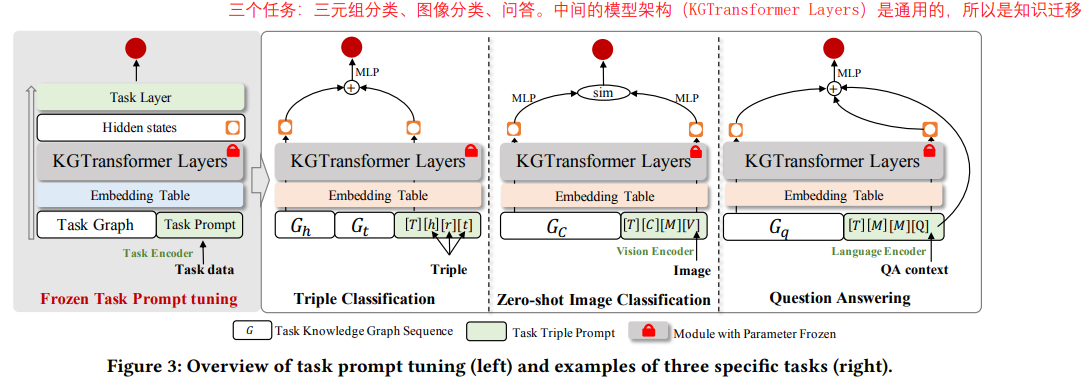
《Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer》
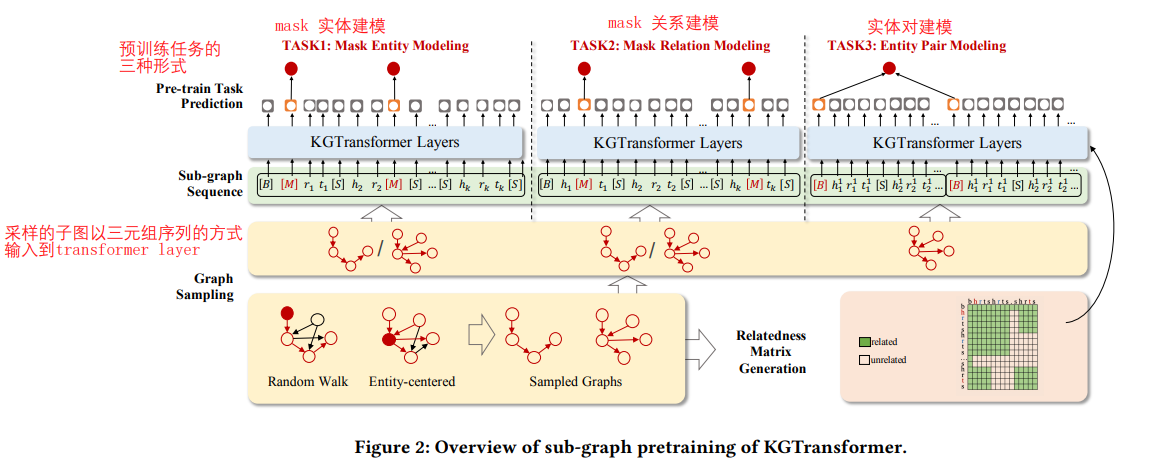
浙大提出的 KGTransformer,跟上面清华的工作差不多,先是随机游走进行子图采样,采样的子图以三元组的方式输入到Transformer。预训练的任务有三种:mask 实体建模、mask 关系建模、以及实体对建模。下游任务包括三元组分类、图像分类、问答三个。
KG-bert:《KG-BERT: BERT for Knowledge Graph Completion》
几个月前看的文章,19年就出来了。
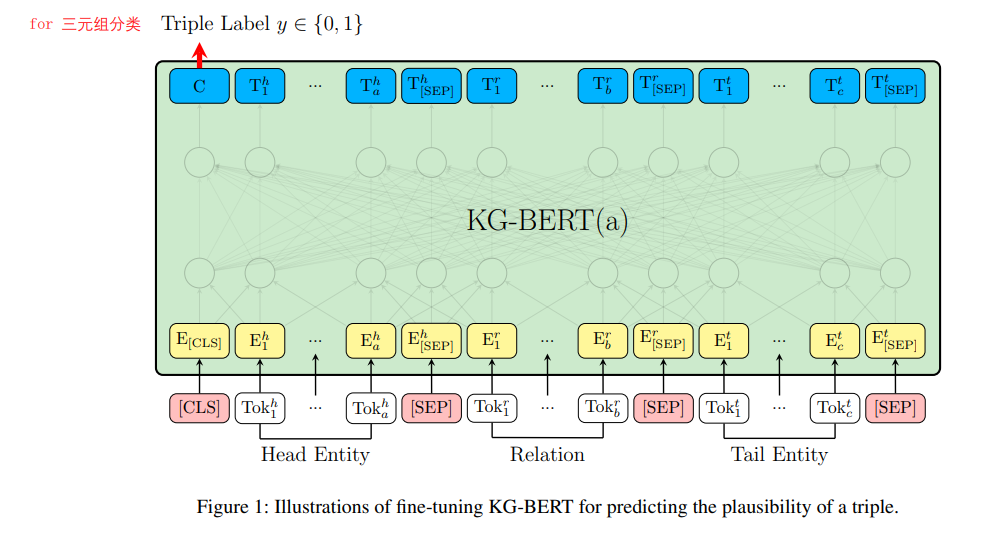
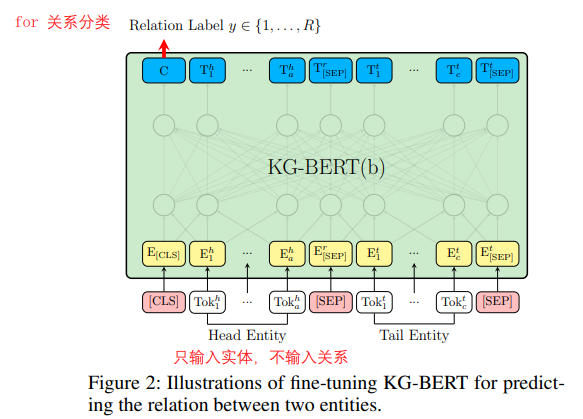
没讲怎么预训练的,只讲了微调阶段的输入输出。在这个模型里,头实体、关系和尾实体都被描述成一个句子,将句子的token 输入到Bert,[sep]进行分隔。如果是三元组分类,就输入三个元素的句子,输出是二分类的标签;如果是关系分类,则输入头实体和尾实体的token,输出是关系。
之前尝试运行了一下程序,模型比较大,训练起来比较慢,训了大约一天得到论文中差不多的结果。效果确实有提升,但是付出的算力代价很大。
Relphomer:《Relphormer: Relational Graph Transformer for Knowledge Graph Representations》
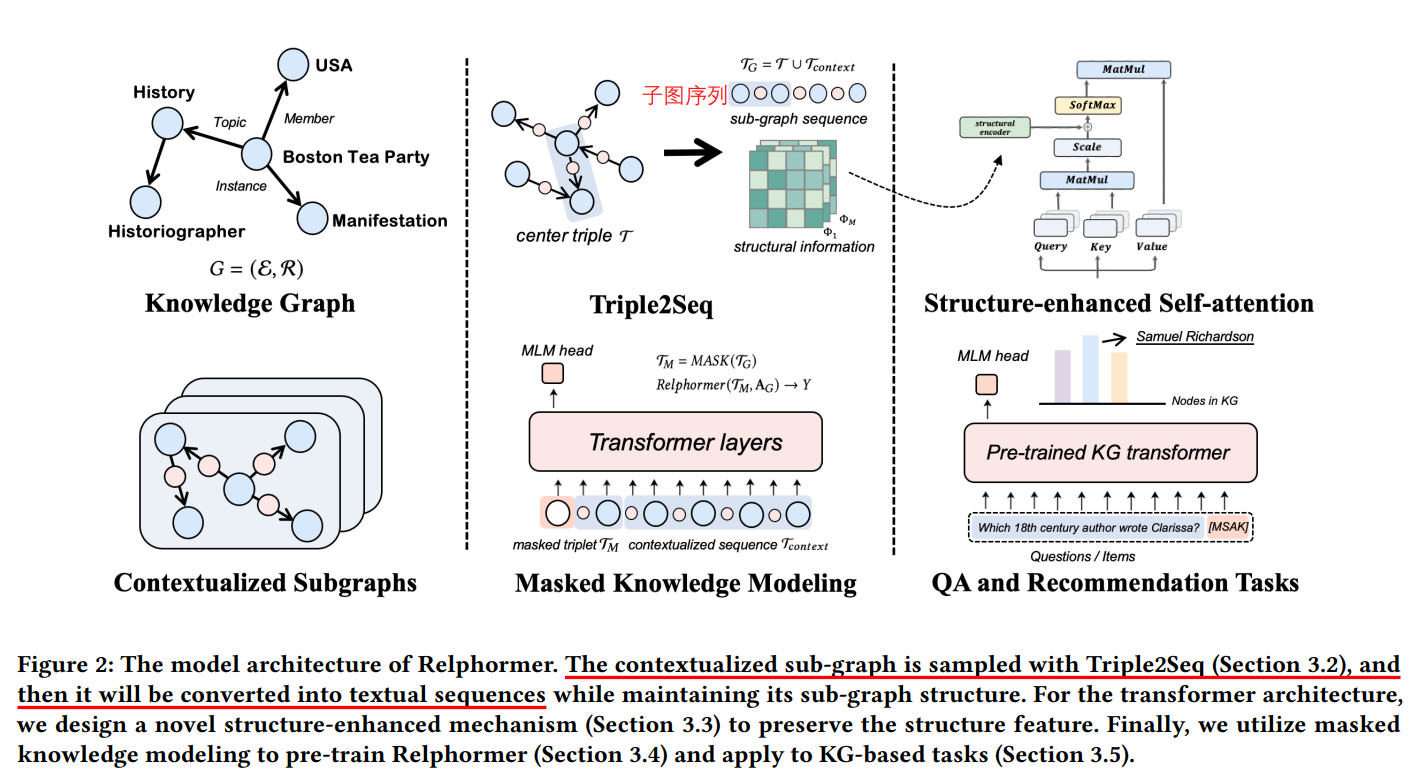
浙大今年新出的一篇,用Transformer做KGC。文章有三个创新点:
1)triple2seq,上下文子图采样;
2)结构增强的 self-attention;
3)masked 知识建模。
在链接预测、问答、推荐任务上进行了测试。之所以注意到这篇文章,是因为它横扫了paperwithcode上几个静态KG数据集的指标。
COMET 和 Atomic 2020
《COMET: Commonsense Transformers for Automatic Knowledge Graph Construction》
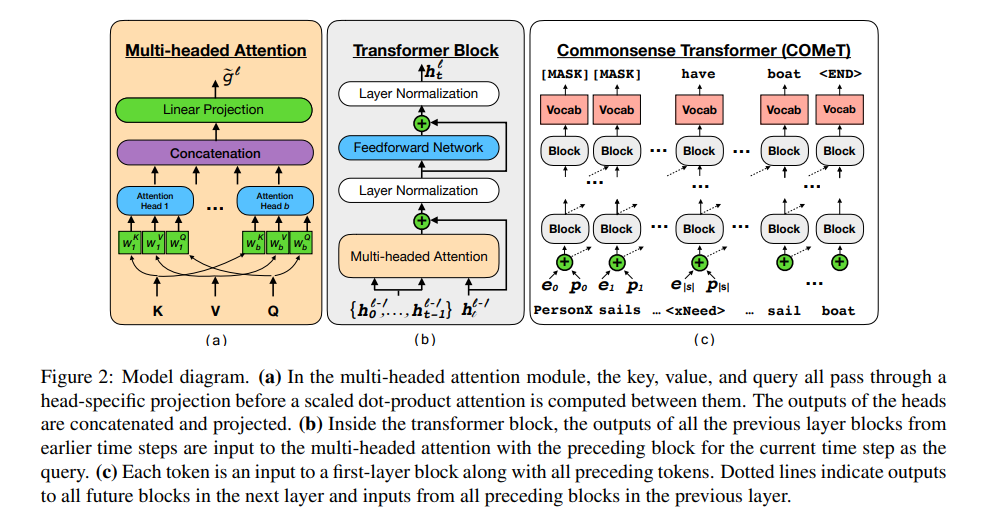
COMET 是一个基于Transformer的知识构建模型(产生新的连边,也是链接预测/知识图谱补全)
《(COMET-)ATOMIC 2020: On Symbolic and Neural Commonsense Knowledge Graphs》
质疑预训练语言模型是否已经编码了常识知识,用GPT验证了效果并不好,只有加上如COMET这样的知识模型,才能效果好。
两个模型是一个团队做的,比较新奇,无论是做的工作,还是给模型取的名字。
总结与思考
用大模型学习图结构的难点:
- 如何解决图结构表示【稀疏】和输入到Transformer的问题?处理图的transformer是如何进行输入和输出的?
经过上述调研,基本都是节点/关系转为序列,才能输入Transformer;但我的想法是最好能直接处理图结构(输入邻接矩阵什么的,可能需要GNN) - 知识图:方向性->用HGAT解决,但如何结合Transformer?有一篇图NN结合Transformer的论文,还有一篇是微软graphormer
关系的表示->tokenGT,关系表示代替位置编码 - 难点:要保留图结构信息就要用到邻接矩阵(图NN),但邻接矩阵中如何体现关系embedding?
解决图结构与方向性的两种方案:
- GNN(但不想用,因为效果不好,要用的话需要考虑如何表示关系
- TransE
也要根据具体的切片图特点考虑用什么样的形式输入到Transformer,还有个问题是用什么计算Attention?