Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction论文解读
这是发表在ICCV2021的一篇文章,主要的工作内容是RGB图片中的人手重建。

Introduction
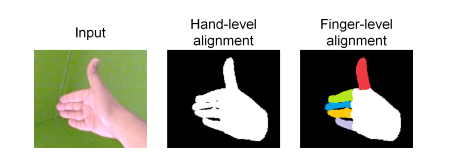
单目下的3D人手重建是计算机视觉中一个非常具有挑战性的任务,并且在人机交互,以及增强现实领域有着很高的应用价值;紧接着作者提出来如果想要把一个人手重建的方法应用在AR中,要满足以下三个需要:1. 重建要具有实时性;2.重建出的手的三维形状和姿态要与用户的手匹配;3.重建出的手投影到2D空间时也要与用户在图像空间中的真实的手对齐(类似上图的最后一张)。同时,论文指出现有的方法也许能够很好的满足前两点,但是第三点却会出现一些misaligned的情况,稍后会提到论文方法针对第三点做的优化。
Method
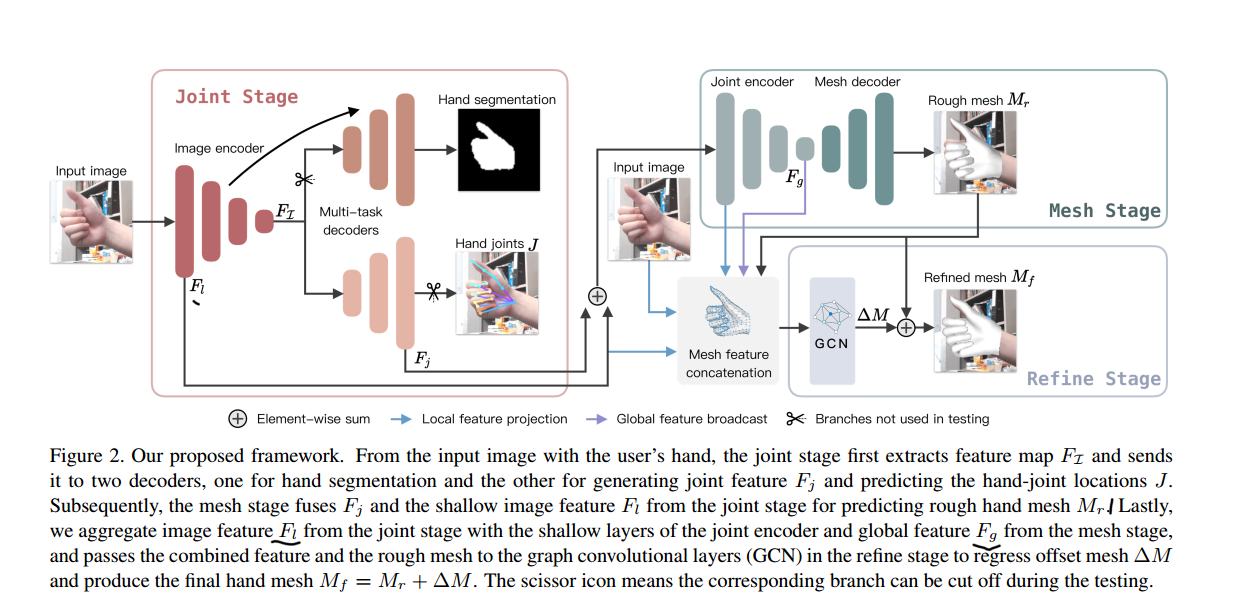
论文的方法,如上图所示,分为三个阶段:
The joint stage将输入图像编码然后预测手的Mask以及hand joints(手部关节点)。The mesh stage将前一个阶段图像encoder的浅层特征\(F_l\),以及Joints Decoder的特征\(F_j\)通过一个网络得到一个初始的Mesh。The Refine stage主要是使用了一个图神经网络,通过一个Local feature projection和Global feature projection预测出Rough Mesh \(M_r\)的一个偏置。
Joint stage
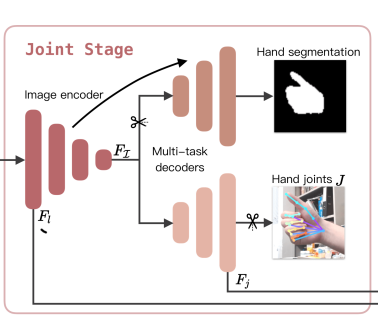
这个阶段的内容比较好理解,一张输入图片先通过一个Image encoder,然后经过一个decoder得到hand segmentation,再通过另一个decoder得到得到手部的关节点预测。在这里Hand segmentation分支发挥的作用主要是为了使得Image encoder训练时,能够更好地捕获手的细节。
Mesh stage
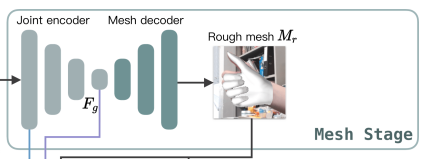
这一步作者把Image encoder的浅层特征\(F_l\)和Joint decoder的特征\(F_j\)加在一送入到下游网络,得到一个Rough Mesh\(M_r\)。
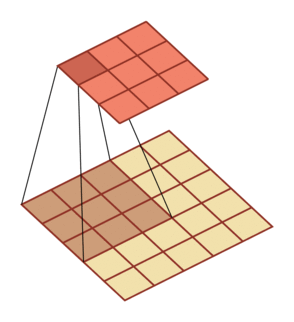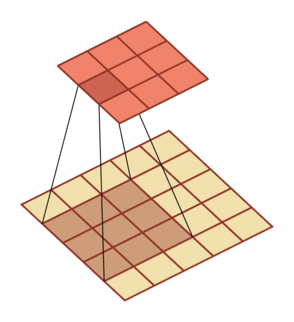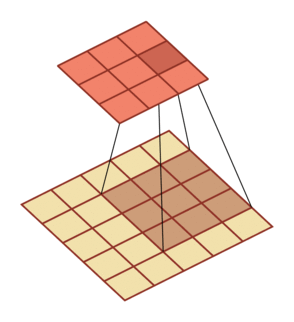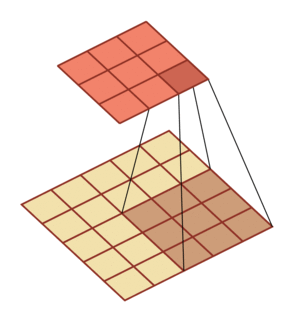
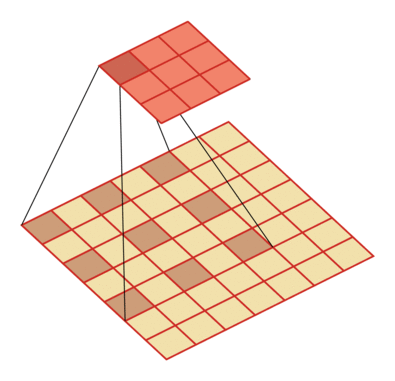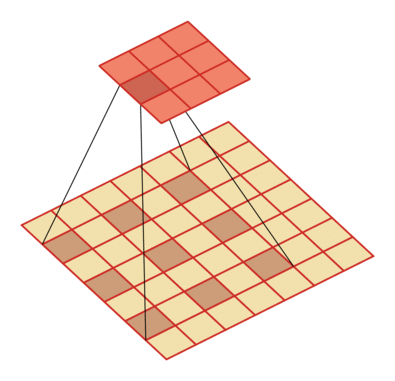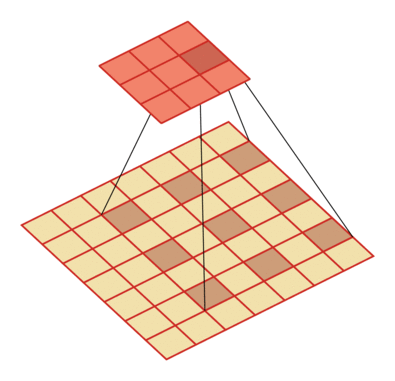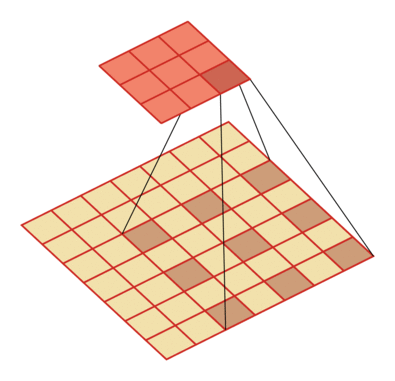
有一个知识点,这里的encoder, decoder使用的是扩张卷积(dilated convolution)[1],扩张卷积又名空洞卷积,相比原来的标准卷积,扩张卷积 多了一个称之为dilation rate(扩张率)的超参数,指的是kernel各点之间的间隔数量,正常的convolution 的 dilatation rate为 1。
| \(l = 1\) | \(l=2\) | \(l=3\) |
|---|---|---|
 |
 |
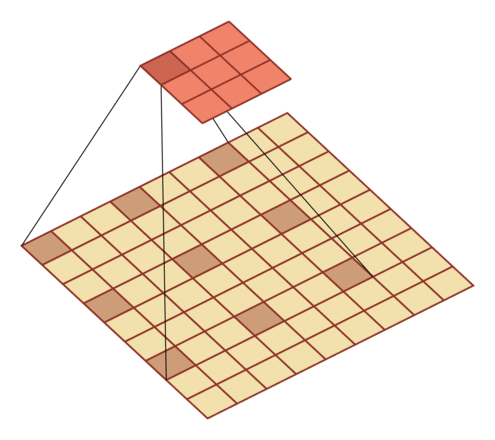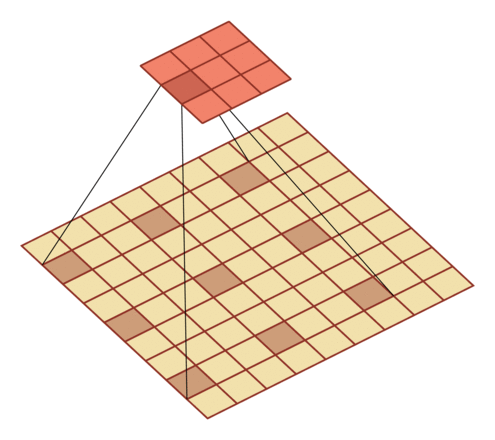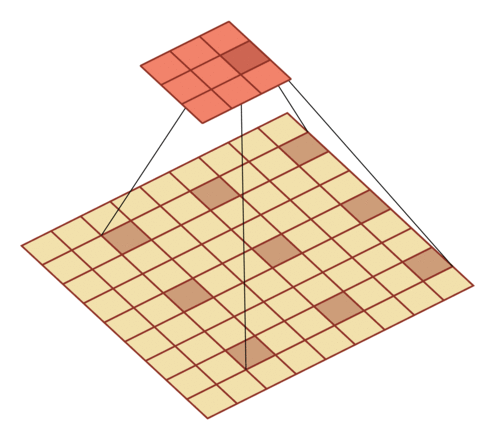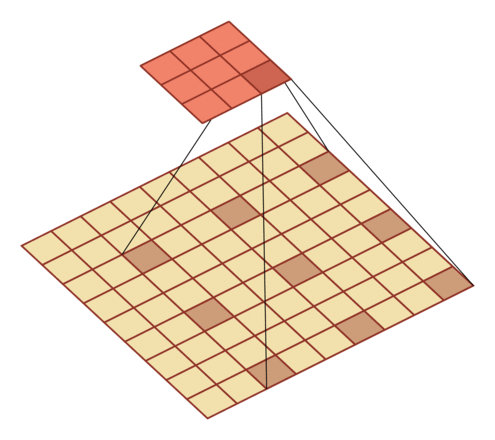 |
扩张卷积的主要目标是增大感受野,在目标检测和语义分割领域经常会看到此方法。
由于\(F_g\)最终是一个低维度的全局特征,由于扩张卷积核的存在,丢失了很多的局部特征。所以mesh stage预测出的mesh在图像空间里并不一定能与用户的手对齐(align),但是这个阶段却可以快速的得到手的一个大致的轮,然后在接下来的renfine stage可以通过学习出mesh的偏置向量来对结果进行微调。
Refine stage
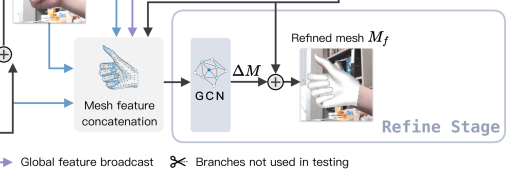
Mesh stage的核心是使用了一个图神经网络(GIN)来预测Mesh的偏置:
\(x_i\)是图的第\(i\)个节点(对应的也就是rough mesh 里的第\(i\)个Mesh顶点)的特征;\(x_i^{\prime}\)是预测出的这个顶点的偏置;
\(\mathcal{N}(i)\)是这个第\(i\)节点的邻居向量集合。
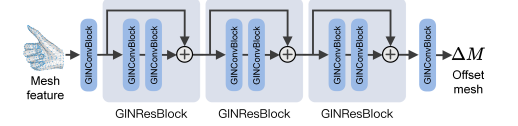
用通俗一点的语言描述就是,这里把手的一个mesh网格看做是一张图,每个节点的特征是由它自己和其邻居节点的特征求和得到,然后将这些特征输入到多层的MLP中去预测出节点的偏置。
下面,我们就去解读每个节点(等同于每个Mesh顶点)的特征如何得到的。
Local feature projection
首先是将每个顶点(vertex)投影到输入图像的像素空间,然后使用得到的像素空间坐标,在输入图像,Image encoder的浅层feature map\(F_l\),Joint encoder得到的浅层Feature map上进行双线性插值,将这三者得到的特征组合成每个顶点的特征向量。
Global feature projection
局部特征有助于处理细节,但它们并不足够。这是因为它们不能提供有关整体手部网格结构的全局信息。针对这一问题,作者引入了Global feature projection,将网格的全局特征广播到每个网格顶点。使用Mesh stage的Joint encoder中获取深层特征\(Fg\),对其进行全局平均池化,得到一个一维向量,并使用全连接层将其通道维度减少1/4。最后,我们将这个全局特征向量再附加到每个顶点的特征向量上。正如方法大图中的紫色箭头表示的一样。
Training
这里我们主要是看一下这个模型的损失函数:
- Mesh loss && joint loss

-
normal loss && edge-length loss
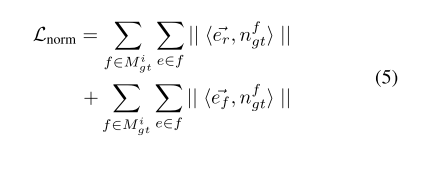
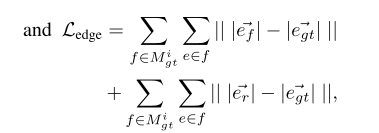
-
Hand segmentation loss

-
render loss

这里是把预测到的Hand mesh投影到2D空间里,然后得到一个二值Mask,使用它来监督模型的投影。不过作者在这里做的更加细化了,叫做finger-level,具体就是作者把 ground truth Hand mesh的手指标注了不同的颜色,然后使用投影得到的像素点颜色进行更加严格细致的监督。
最终的Loss \(\mathcal{L}=\mathcal{L}_{\text {mesh }}+\lambda_j \mathcal{L}_{\text {joint }}+\lambda_n \mathcal{L}_{\text {normal }}+\) \(\lambda_e \mathcal{L}_{\text {edge }}+\lambda_s \mathcal{L}_{\text {sil }}+\lambda_r \mathcal{L}_{\text {render }}\),根据经验设置 \(\lambda_j=\) \(\lambda_n=\lambda_e=1, \lambda_s=10\), 设置 \(\lambda_r=0.1\)
Experiments
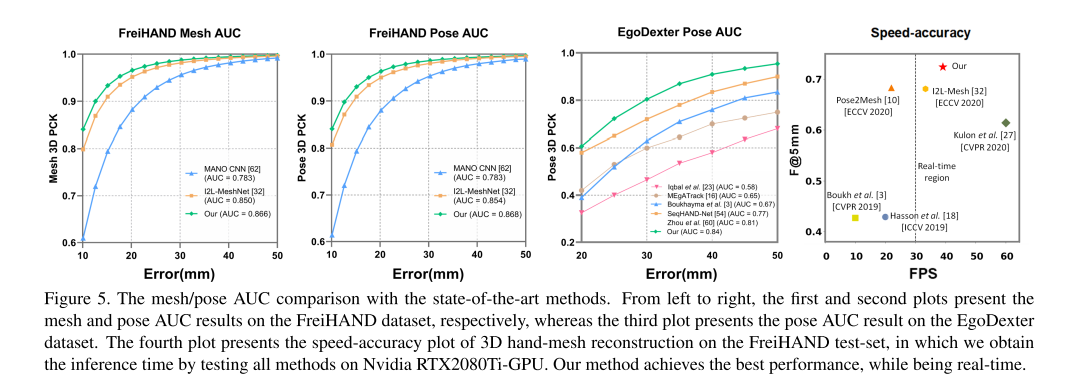

主要是看一下对应的消融实验:
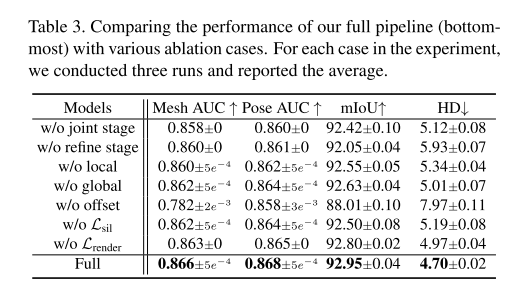
第二行是去掉最后的refine stage,将\(M_r\)$作为最终模型的输出;
第三行是去掉vertex从Local projection unit得到的局部特征;
第四行是去掉vertex从Global projection unit得到的全局特征;
第五行是直接使用Graph-CNN预测最终的Hand Mesh而不是偏置向量,可以看到这个对结果影响比较大,作者的解释是这个比较小的网络结构是设计用来regress small values;
第六第七行则是去掉Mask segmentation Loss 还有 render loss的影响;
最后一行是 full pipeline。
Code
模型是在Nvidia RTX 2080ti 上进行训练的,不过作者在其代码主页没有给出对应的cuda和pytorch版本,我前期在这里因为版本问题踩了一些坑。最后经过推测得到的版本是 torch1.6 + cuda10.2,需要的朋友可以据此配置一下。

refer
[1] 如何理解空洞卷积(dilated convolution)?
[2] Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction
- Reconstruction Alignment Real-time Hand-Mesh Accuratereconstruction alignment real-time hand-mesh hand-mesh accurate reconstruction vdsr-accurate reconstruction comparison algorithms evaluation regression efficient accurate bounding reconstruction learning natural survey super-resolution vdsr-accurate convolutional lightweight cardinality estimation accurate