发表时间:2021(CoRL 2021)
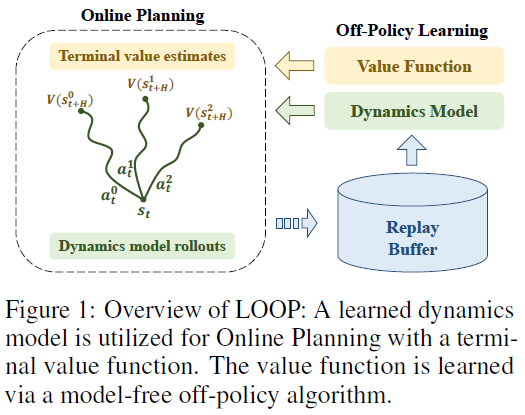
文章要点:这篇文章提出Off-Policy with Online Planning (LOOP)算法,将H-step lookahead with a learned model和terminal value function learned by a model-free off-policy结合起来,做online planning。然后提出一个Actor Regularized Control (ARC)方法来解决Actor Divergence问题。
具体的,就是去学一个model,然后选动作的时候就基于model选使得累积回报最大的动作

最后的这个value是在训强化的时候得到的。这里有个问题就是,做online planning的策略和训练value的策略不是同一个策略,会导致online planning得到的动作不一定是最好的,这个作者就叫做Actor Divergence,作者提的方法就是在最大化回报的同时控制这两个策略的距离

然后就结束了。
总结:不知道点在哪,感觉就没有创新。
疑问:感觉这文章没啥新东西啊,也不知道怎么就能发了。
- Off-Policy Learning Planning Policy Onlineoff-policy learning planning policy reinforcement exploration off-policy learning off-policy off-policy alphazero targets greedy reinforcement minimization experience off-policy policy advantage-weighted off-policy regression improvement planning policy gumbel 策略policy off-policy on-policy model-based learning planning scratch representations deepwalk learning online