一、HPA弹性伸缩描述
1.1 基础概念
HPA全称是 Horizontal Pod Autoscaler,也就是对k8s的workload的副本数进行自动水平扩缩容(scale)机制,也是k8s里使用需求最广泛的一种Autoscaler机制。
在 K8S 1.18 之前,HPA 扩容是无法调整灵敏度的:
- 对于缩容,由
kube-controller-manager的--horizontal-pod-autoscaler-downscale-stabilization-window参数控制缩容时间窗口,默认 5 分钟,即负载减小后至少需要等 5 分钟才会缩容。 - 对于扩容,由 hpa controller 固定的算法、硬编码的常量因子来控制扩容速度,无法自定义。
HPA 在 K8S 1.18 迎来了一次更新,在之前 v2beta2 版本上新增了扩缩容灵敏度的控制,不过版本号依然保持 v2beta2 不变。
1.2 弹性伸缩类型
- Cluster-Autoscale: 集群容量(node数量)自动伸缩,跟自动化部署相关的,依赖iaas的弹性伸缩,主要用于虚拟机容器集群
- Vertical Pod Autoscaler: 工作负载Pod垂直(资源配置)自动伸缩,如自动计算或调整deployment的Pod模板limit/request,依赖业务历史负载指标
- Horizontal-Pod-Autoscaler: 工作负载Pod水平自动伸缩,如自动scale deployment的replicas,依赖业务实时负载指标
1.3 扩缩容的原理
通过监控业务繁忙情况,在业务忙时就对workload扩容副本数;等到业务闲下来时自然要把副本数再缩下去。
- 如何识别业务的忙闲程度
- 使用什么样的副本调整策略
Kubernetes 提供了一个标准的度量标准接口,整个 Horizontal Pod Autoscaler(HPA)和度量架构如下图所示。HPA 控制器通过这一一致的度量标准接口可以查询到与任意一个 HPA 对象关联的 Deployment 业务的繁忙度量标准数据。不同业务的繁忙度量标准可以进行自定义,在相应的 HPA 中定义与关联 Deployment 相关的度量标准即可。
一旦标准的度量标准查询接口就绪,接下来需要实现度量标准 API 的服务端,并提供各种度量标准数据。在 Kubernetes 中,核心组件之间通常通过 apiserver 进行通信。因此,作为 Kubernetes API 的扩展,metrics API server 自然选择了基于 API Aggregation 聚合层。通过这一层,HPA 控制器的度量标准查询请求能够自动通过 apiserver 的聚合层转发到后端真实的 metrics API 服务端。
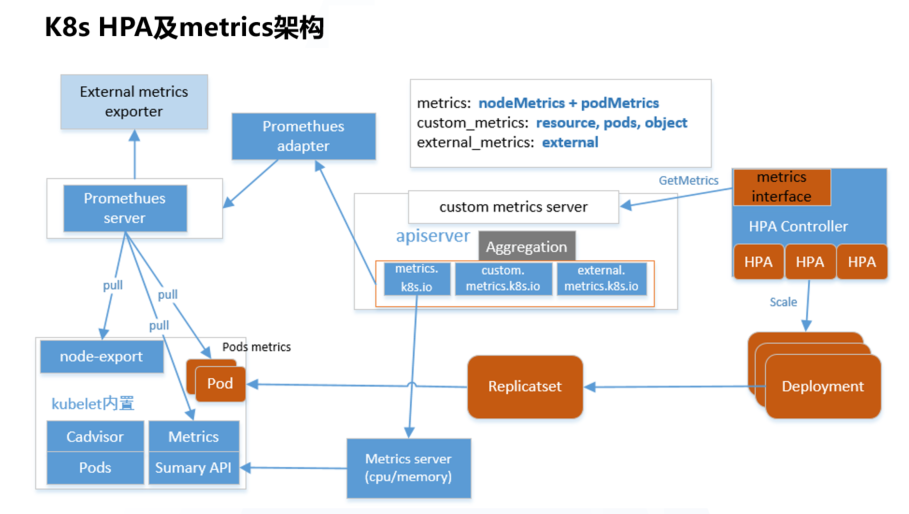
1.4 HPA的metrics的分类
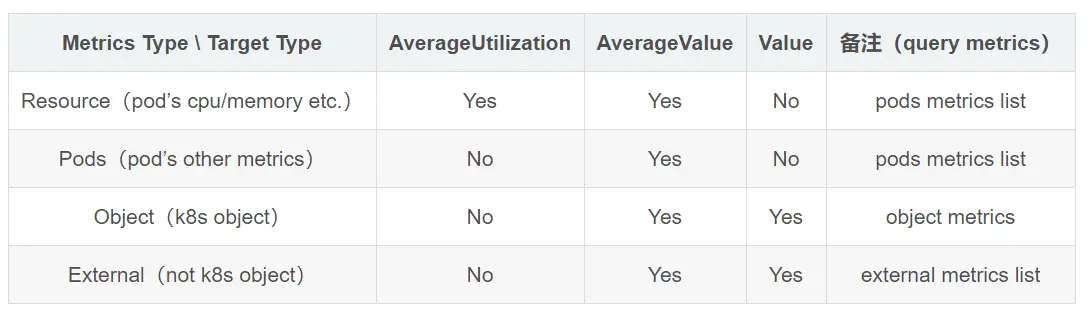
要支持最新的custom(包括external)的metrics,也需要使用新版本的HPA:autoscaling/v2beta1,里面增加四种类型的Metrics:Resource、Pods、Object、External,每种资源对应不同的场景,下面分别说明:
- Resource Metrics: 这种度量标准基于 Pod 使用的资源(如 CPU 和内存)。HPA 可以使用这些度量标准来自动调整 Pod 的副本数,以确保资源的有效利用。
- Pods Metrics: Pods 指标关注的是一组 Pod 的聚合度量标准,而不是单个 Pod。这样的度量标准可能涉及到一组 Pod 的总体性能,例如一组 Pod 中的平均请求响应时间。
- Object Metrics: 这种度量标准允许 HPA 关注与特定对象相关的性能指标,如存储系统中的对象。这对于需要基于特定对象状态进行调整的场景很有用。
- External Metrics: 外部度量标准允许 HPA 使用来自集群外部的度量标准,例如由第三方监控系统提供的指标。这使得 HPA 可以更灵活地根据外部系统的信息进行调整。
HPA里的各种类型的Metrics和Metrics Target Type的对应支持关系表
1.4.1 Resource Metrics
-
在 Pod 的 YAML 文件中定义资源请求和限制,如 CPU 和内存。示例:
yamlCopy coderesources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" -
在 HPA 的 YAML 文件中指定使用资源度量标准。示例:
yamlCopy codeapiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: example-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: example-deployment metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50
1.4.2 Pods Metrics
-
使用监控工具收集一组 Pod 的聚合度量标准,例如 Prometheus。
-
在 HPA 的 YAML 文件中指定 Pods 度量标准。示例:
yamlCopy codeapiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: example-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: example-deployment metrics: - type: Pods pods: metricName: http_requests target: type: AverageValue averageValue: 500
1.4.3 Object Metrics
-
定义与特定对象相关的性能指标,例如存储系统中的对象度量标准。
-
在 HPA 的 YAML 文件中指定 Object 度量标准。示例:
yamlCopy codeapiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: example-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: example-deployment metrics: - type: Object object: metricName: custom_object_metric target: type: Value value: 100
1.4.4 External Metrics
-
通过外部监控系统(例如 Prometheus、Datadog 等)收集度量标准。
-
在 HPA 的 YAML 文件中指定 External 度量标准。示例:
yamlCopy codeapiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: example-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: example-deployment metrics: - type: External external: metricName: custom_external_metric target: type: Value value: 200
二、案例配置及解析
2.1 控制扩缩容的速率综合案例
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
labels:
app: payww-service-read
name: payww-service-read-hpa
namespace: teew-app-pay-pro
spec:
behavior: # 这里是重点
scaleDown:
stabilizationWindowSeconds: 300 # 需要缩容时,先观察5分钟,如果一直持续需要缩容才执行缩容
policies:
- periodSeconds: 15
type: Percent # 允许全部缩掉
value: 100
selectPolicy: Max
scaleUp:
policies:
stabilizationWindowSeconds: 0 # 需要扩容时,立即扩容
- periodSeconds: 15 #每15s最大允许扩容4个Pod
type: Pods
value: 4
- periodSeconds: 15 #每15s最大允许扩容当前1倍数量的 Pod
type: Percent
value: 100
selectPolicy: Max # 使用以上两种扩容策略中算出来扩容 Pod 数量最大的
maxReplicas: 2
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: payww-service-read
- 以上
behavior配置是默认的,即如果不配置,会默认加上。 scaleUp和scaleDown都可以配置1个或多个策略,最终扩缩时用哪个策略,取决于selectPolicy。selectPolicy默认是Max,即扩缩时,评估多个策略算出来的结果,最终选取扩缩 Pod 数量最多的那个策略的结果。stabilizationWindowSeconds是稳定窗口时长,即需要指标高于或低于阈值,并持续这个窗口的时长才会真正执行扩缩,以防止抖动导致频繁扩缩容。扩容时,稳定窗口默认为0,即立即扩容;缩容时,稳定窗口默认为5分钟。policies中定义扩容或缩容策略,type的值可以是Pods或Percent,表示每periodSeconds时间范围内,允许扩缩容的最大副本数或比例。
案例分析:
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
-
resource: 表示该指标是一个资源相关的指标,这里指定了cpu,即基于 CPU 利用率。 -
target定义了 CPU 利用率的目标。
averageUtilization: 80表示你希望每个 CPU 核心的平均利用率维持在 80%。但是需要注意,这个值超过了通常的 CPU 利用率的百分比范围(0 到 100%)。type: Utilization表示这是一个基于资源利用率的指标。
2.2 扩容策略
2.2.1 快速缩容
可以使用类似如下的 HPA 配置:
behavior:
scaleUp:
policies:
- type: Percent
value: 900
periodSeconds: 15 # 每 15s 最多允许扩容 9 倍于当前副本数
上面的配置表示扩容时最大一次性新增当前 9 倍数量的副本数,当然也不能超过 maxReplicas 的限制。
假如一开始只有 1 个 Pod,如果遭遇流量突发,且指标持续超阈值 9 倍以上,它将以飞快的速度进行扩容,扩容时 Pod 数量变化趋势如下:
1 -> 10 -> 100 -> 1000
没有配置缩容策略,将等待全局默认的缩容时间窗口 (默认5分钟) 后开始缩容。
2.2.2 缓慢扩容
如果想要你的应用不太关键,希望扩容时不要太敏感,可以让它扩容平稳缓慢一点,为 HPA 加入下面的 behavior:
behavior:
scaleUp:
policies:
- type: Pods
value: 1
periodSeconds: 300 # 每 5 分钟最多只允许扩容 1 个 Pod
假如一开始只有 1 个 Pod,指标一直持续超阈值,扩容时它的 Pod 数量变化趋势如下:
1 -> 2 -> 3 -> 4
2.2.3 延长扩容时间窗口
有些应用经常会有数据毛刺导致频繁扩容,而扩容出来的 Pod 其实没太大必要,反而浪费资源。比如数据处理管道的场景,需要的副本数取决于队列中的事件数量,当队列中堆积了大量事件时,我们希望可以快速扩容,但又不希望太灵敏,因为可能只是短时间内的事件堆积,即使不扩容也可以很快处理掉。
默认的扩容算法会在较短的时间内扩容,针对这种场景我们可以给扩容增加一个时间窗口以避免毛刺导致扩容带来的资源浪费,behavior 配置示例如下:
behavior:
scaleUp:
stabilizationWindowSeconds: 300 # 扩容前等待 5 分钟的时间窗口
policies:
- type: Pods
value: 20
periodSeconds: 60 # 每分钟最多只允许扩容 20 个 Pod
上面的示例表示扩容时,需要先等待 5 分钟的时间窗口,如果在这段时间内指标又降下来了就不再扩容,如果一直持续超过阈值才扩容,并且每分钟最多只允许扩容 20 个 Pod。
2.3 缩容策略
2.3.1 缓慢缩容
如果流量高峰过了,并发量骤降,如果用默认的缩容策略,等几分钟后 Pod 数量也会随之骤降,如果 Pod 缩容后突然又来一个流量高峰,虽然可以快速扩容,但扩容的过程毕竟还是需要一定时间的,如果流量高峰足够高,在这段时间内还是可能造成后端处理能力跟不上,导致部分请求失败。这时候我们可以为 HPA 加上缩容策略,HPA behavior 配置示例如下:
behavior:
scaleUp:
policies:
- type: Percent
value: 900
periodSeconds: 15 # 每 15s 最多允许扩容 9 倍于当前副本数
scaleDown:
policies:
- type: Pods
value: 1
periodSeconds: 600 # 每 10 分钟最多只允许缩掉 1 个 Pod
上面示例中增加了 scaleDown 的配置,指定缩容时每 10 分钟才缩掉 1 个 Pod,大大降低了缩容速度,缩容时的 Pod 数量变化趋势如下:
1000 -> … (10 min later) -> 999
这个可以让关键业务在可能有流量突发的情况下保持处理能力,避免流量高峰导致部分请求失败。
2.3.2 禁止自动缩容
如果应用非常关键,希望扩容后不自动缩容,需要人工干预或其它自己开发的 controller 来判断缩容条件,可以使用类型如下的 behavior 配置来禁止自动缩容:
behavior:
scaleDown:
selectPolicy: Disabled
2.3.3 延长缩容时间窗口
缩容默认时间窗口是 5 分钟,如果我们需要延长时间窗口以避免一些流量毛刺造成的异常,可以指定下缩容的时间窗口,behavior 配置示例如下:
behavior:
scaleDown:
stabilizationWindowSeconds: 600 # 等待 10 分钟再开始缩容
policies:
- type: Pods
value: 5
periodSeconds: 600 # 每 10 分钟最多只允许缩掉 5 个 Pod
上面的示例表示当负载降下来时,会等待 600s (10 分钟) 再缩容,每 10 分钟最多只允许缩掉 5 个 Pod。