gmp调度
线程、协程、进程
-
进程: 是资源分配的最小单位,是程序的一次执行过程,是一个动态概念,是系统进行资源分配和调度的一个独立单位.
-
线程: 是程序执行的最小单位,是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
-
协程: 是一种用户态的轻量级线程,协程的调度完全由用户控制,协程拥有自己的寄存器上下文和栈,协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈指针,所以性能极高,可以不加锁的访问全局变量,所以上下文的切换非常快.
gmp定义
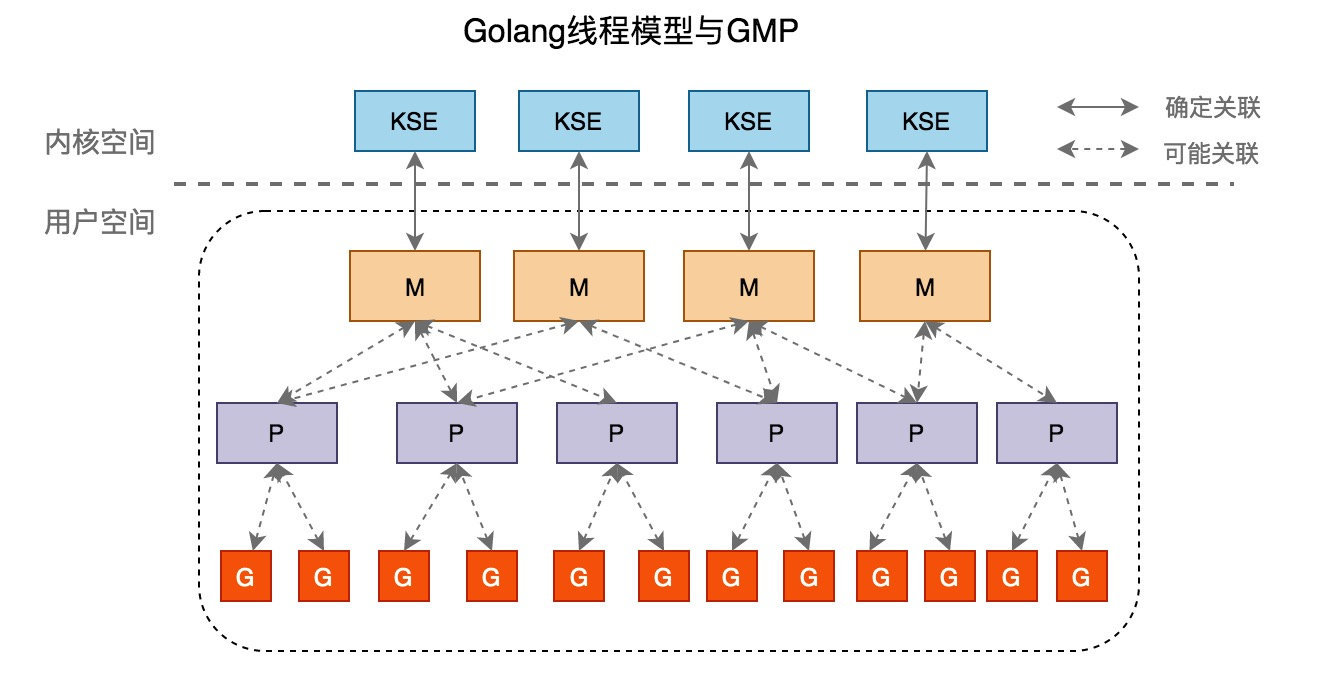
- G - Goroutine,Go协程,是参与调度与执行的最小单位,数量理论上没有限制
- M - Machine,指的是系统级线程,默认
1000,通过SetMaxThreads()设置 - P - Processor,指的是逻辑处理器,P关联了的本地可运行G的队列(也称为LRQ),最多可存放256个G,P的数量由
GOMAXPROCS决定
调度流程
- 线程
M想要运行任务,需要绑定一个P - 从
Pd的本地队列中取出一个G,并执行 P的本地队列为空,从全局队列中取出一批G,并执行- 全局队列为空,从其他
P的本地队列中偷取一半的G,并执行 - 拿到可运行的G之后,M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
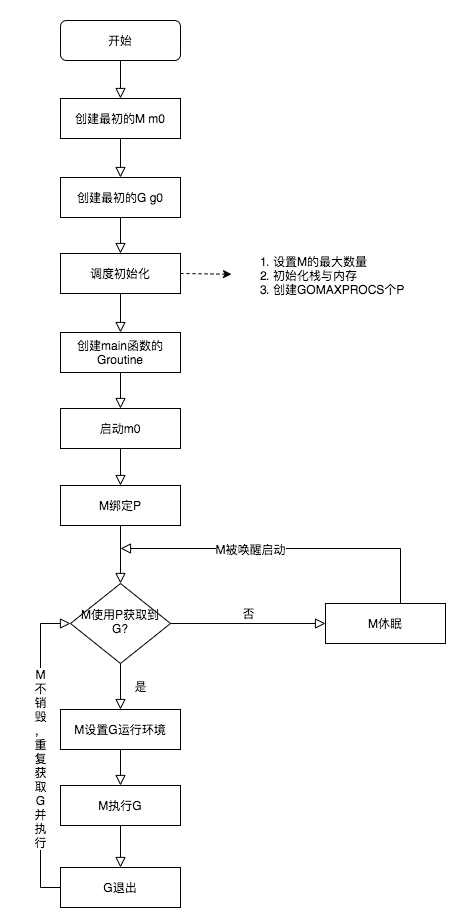
- M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了
- G0 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0
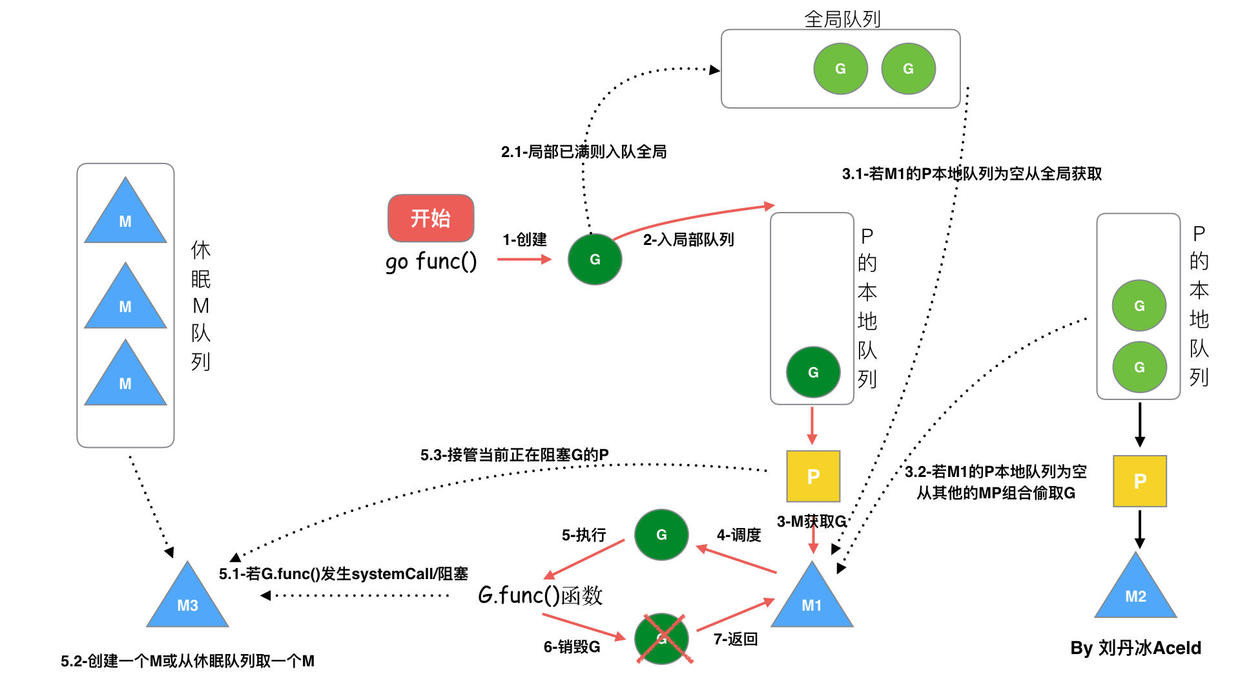
- 每个P有个局部队列,局部队列保存待执行的goroutine(流程2),当M绑定的P的的局部队列已经满了之后就会把goroutine放到全局队列(流程2-1)
每个P和一个M绑定,M是真正的执行P中goroutine的实体(流程3),M从绑定的P中的局部队列获取G来执行 - 当M绑定的P的局部队列为空时,M会从全局队列获取到本地队列来执行G(流程3.1),当从全局队列中没有获取到可执行的G时候,M会从其他P的局部队列中偷取G来执行(流程3.2),这种从其他P偷的方式称为
work stealing - 当G因系统调用(syscall)阻塞时会阻塞M,此时P会和M解绑即
hand off,并寻找新的idle的M,若没有idle的M就会新建一个M(流程5.1)。 - 当G因channel或者network I/O阻塞时,不会阻塞M,M会寻找其他runnable的G;当阻塞的G恢复后会重新进入runnable进入P队列等待执行(流程5.3)
阻塞
- I/O,select
- block on syscall
- channel
- 等待锁
- runtime.Gosched()
用户态阻塞
主要指channel,网络IO
以channel读写为例
- 当
channel容量满时,g_chan_write会记录在waitq,状态从_Gruning改为_Gwaitting,然后m会尝试获取可运行的g,如果无法获取,m会解绑p,进行sleep状态 - 当
g_chan_write接收到可写信号通知后,状态恢复为runnable,并尝试加入通知自己的g的的队列
系统阻塞
当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于 block on syscall 状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列。
单个P的调度
code
func main() {
runtime.GOMAXPROCS(1)
for i := 1; i <= 258; i++ {
go func(int) {
fmt.Println(i)
}(i)
}
time.Sleep(time.Second * 2)
}
在上面这段代码中,通过GOMAXPROCS(1)设置只有一个P处理器同时工作
p中有关键成员:runnext,新加入本地队列的g会放置在runnext上
p的本地队列长度为256,当p的本地队列满了之后,会将runnext中的g和p的本地队列中前128个g放到全局队列中
也就是说,一个p最多存放len(p.runq)+len(p.runnext)个g,也就是257个g
当第258个g加入进来,g_258会放在runnext位置,本地队列中g_1-g_128和原来在runnext的g_257会放到全局队列中
这样运行结果应该是
258(runnext位,最先运行)
129(本地队列,因为1-128被放到全局队列中,129就成为了本地队列第一个元素)
130(同上)
.....
.....
255
256(本地队列最后一个)
1(开始从全局队列开始拿)
2
3
4
5
6
....
....
127
128
257(本来在runnext位,加入到全局队列放在最后)
实际上,在258-256中间,就会出现1-257的元素,这是golang内部机制,防止全局队列中的g等待时间过长,每个p每隔61个schedtick就会从全局队列中拿g去执行
源码解析
g
type g struct {
stack stack // g自己的栈
m *m // 隶属于哪个M
sched gobuf // 保存了g的现场,goroutine切换时通过它来恢复
atomicstatus uint32 // G的运行状态
goid int64
schedlink guintptr // 下一个g, g链表
preempt bool //抢占标记
lockedm muintptr // 锁定的M,g中断恢复指定M执行
gopc uintptr // 创建该goroutine的指令地址
startpc uintptr // goroutine 函数的指令地址
}
p
type p struct {
id int32
status uint32 // P的状态
link puintptr // 下一个P, P链表
m muintptr // 拥有这个P的M
mcache *mcache
// P本地runnable状态的G队列,无锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr // 一个比runq优先级更高的runnable G
// 状态为dead的G链表,在获取G时会从这里面获取
gFree struct {
gList
n int32
}
gcBgMarkWorker guintptr // (atomic)
gcw gcWork
}
m
type m struct {
g0 *g // g0, 每个M都有自己独有的g0
curg *g // 当前正在运行的g
p puintptr // 隶属于哪个P
nextp puintptr // 当m被唤醒时,首先拥有这个p
id int64
spinning bool // 是否处于自旋
park note
alllink *m // on allm
schedlink muintptr // 下一个m, m链表
mcache *mcache // 内存分配
lockedg guintptr // 和 G 的lockedm对应
freelink *m // on sched.freem
}