Introduction to ML strategy
Why ML Strategy
比如下面这个识别猫的分类器,目前的训练结果可能达到了90%的准确率。但是如果像进一步提高性能,有很多待选的方法。但是该如何去选择呢?

下面的课程就是主要介绍Machine Learning Strategy。另外,需要注意,策略并不是一成不变的。
正交化 Orthogonalization
构建机器学习系统的挑战之一就是,有太多可以尝试和改变的东西,比如有很多的超参数 。
通过调整某些内容来达到指定的效果,这个步骤称为正交化。(就是操作的结果尽量只影响到一个方面,解耦?)
比如以老式电视机为例子,通过调整某个按钮可以修改图像的宽度,或者某个按钮来修改图像的高度等;如果只有一个按钮来调整电视的各项参数,相比之下显然很难调整到合适的位置。
就如同上述的电视机的例子,在机器学习中,当我们遇到了限制系统性能问题,我们需要知道修改那些容来解决这个问题。如下面图中所示,如果在训练集上表现差(高偏差)可以训练更大的网络或者使用Adam算法等。

关于early stopping,老师说这个方法并不算一个比较“正交化的按钮”,因为在使用这个方法的时候,会同时影响到在训练集上的准确性和开发集上的准确性两件事儿。所以在正交化的策略中不推荐使用。
单一数字评估指标
设置一个单一数字评估指标,来帮助了解使用新手段之后神经网络的效果。
如下图示例中,如果通过Precision和Recall来判断A、B两个分类器,那个效果更好,显然是比较麻烦的,因为不能从数据上直观地判断出来A或B谁更好一下,而且在实践中我们需要判断的分类器可能不止两个。
Precision:是指在分类器识别为猫的结果中,确实为猫的概率
Recall:是指分类器将为猫的图片正确识别的概率
所以我们期望通过一个指标可以判断出A或B谁更好,就可以通过F1 Score(调和平均数)这个参数。
通过这个指标可以清晰明了的判断出A是更好的一个。

又或者在下面的例子中,可以通过平均数来判断那个算法的表现更好。
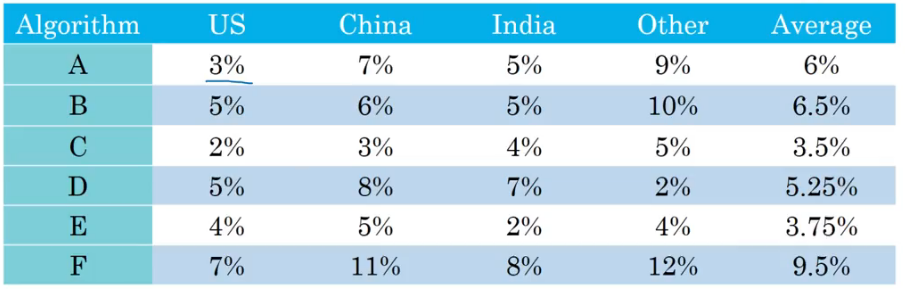
从上面的例子中,可以总结出有一个单实数评估指标可以提高决策效率。
满足指标和优化指标
比如,在一个分类器中,我们需要考虑的指标有N个。选择一个指标作为优化指标是合理的;剩下N-1个指标作满足指标。即只需要尽量优化那个优化指标,而对于满足指标只需要满足下限即可。

就比如上图中的例子,运行的时间我们只要求做到100ms以下就行(不在意他是100ms或50ms满足下限即可),即满足指标;accuracy才是优化指标,是我们需要尽量去优化的评估指标。
Train/dev/test distributions
如何设置 Train/dev/test 集,在很大程度上影响了机器学习的速度。
首先dev/test集应该保持来自同一分布(比如有来自不同地区猫咪的图片,我们直组打乱组合再随机分配给dev和test)。其次确定了dev set和单实数评估指标就确定了目标。就可以快速迭代、实验、尝试不同的想法。
Size of the dev and test sets
(之前讲过的)总结,在现在大数据时代,之前七三分已经不再适用了,先在主流的做法是把大量的数据分到训练集,然后少量的数据分开到开发集和测试集,尤其是有一个非常大的数据集。
When to change dev/test sets and metrics
举例如下,对于识别是否为猫的分类器有算法A、B。从原本的指标分类错误率上来看,A算法比B要好。但是A算法有概率将色图识别为猫推荐给用户而B不会。这样的算法显然是用户不希望看到的,所以此时就需要修改评估指标或者是dev/test sets。
| Algorithm | Classification error[%] | |
|---|---|---|
| A | 3% | error maybe porngraphic |
| B | 5% | no |
可以更改指标为下面 的式子
不过,使用上述的式子,必须自己过一遍数据,标记处色图。
另外例如,开发测试集都是很清晰的专业图片,而实际上最终上线的是针对用户上传的不专业的图片(像素低、角度差等),那么此时就需要更改开发/测试集,加入不专业的图片作为训练对象。
总体来说就是,如果你当前的指标和当前用来评估的数据和你真正必须做好的事情关系不大,那么就要修改指标或者dev/test集,让其能更好的反应算法需要处理好的数据。即使你无法直接确定完美的指标和dev/test集合,也可以先设置一个,如果后面觉得不好再改。
人类表现水准
为什么要和人类表现水准对比?
第一,由于DL的进步,ML的算法突然产生了很好的表现,并且很多应用领域做到匹敌人类逐渐变得可行。
第二,构建ML的流程中,如果尝试人类能做的事情,会非常有效。
算法的准确率在接近人类之前,提升的很快,然超过人类表现之后提升的速度逐渐下降。并且存在一个论上限,Baye optimal error,这是由数据本身的噪声决定的。
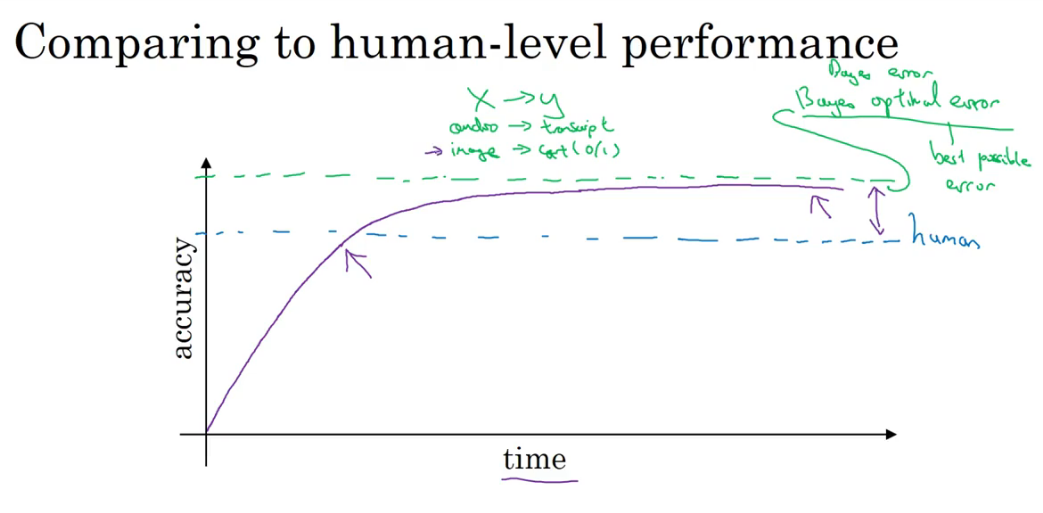
之所以会产生这种前后反差,是因为:
- human-level performance其实已经足够好了,本身就很接近Bayes optimal error。因此留给算法再提升的空间非常有限。
- 在human-level performance之下,人们有特定的工具可以提高performance(相反,超过之后则很难用工具提高了):
- 获取人工标注的数据。
- 人工分析错误的原因,从人类的正确处理得到启发。
- 对bias/variance得到更好的分析。
Avoidable bias
使用人类表现的值近似得作为贝叶斯最优误差,据此去考察一个算法的表现,以及是需要降低bias还是要降低variance。
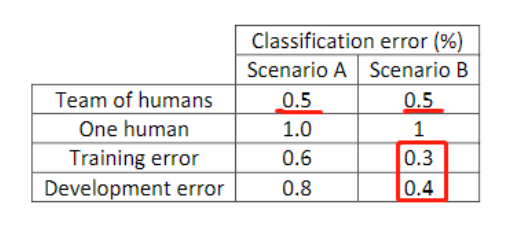
比如,识别猫咪的分类算法,有两个场景A、B得到以下结果:
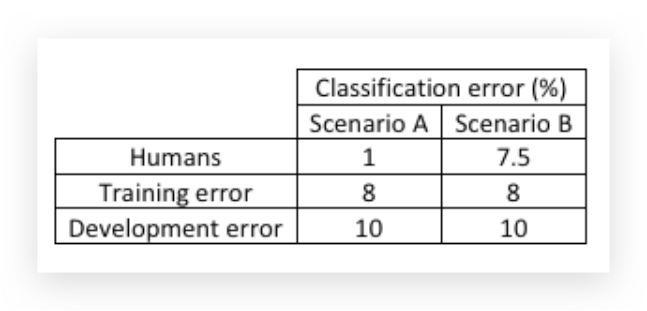
场景A是比较清晰的图片,人类分辨的误差为1%(或者说是贝叶斯最优误差);场景B是模糊图片,即便是人类分辨的误差也在7.5%。
对于这两个场景,算法都得到了相同的 train error和dev error,但是他们结果表现是不同的。
把人类表现得水平近似得看作贝叶斯最优误差,我们将train error和贝叶斯最优误差之间得差距称作avoidable bias。
场景A而言,avoidable bias有7%,而方差有2%,所以这里我们需要重点降低bias。可以采取的手段有:增大神经网络或增加迭代。场景B,avoidable bias只有0.5%,方差有2%,所以我们这里需要重点降低方差。可以采取的手段有正则化、或者更数据扩充。
理解人类的表现
以根据一张X光片对疾病进行判断为例,不同人群可能会有不同的表现。

如果把人类表现作为贝叶斯最优误差的近似,那么应该选择所有人群中表现最好的数据,在本例中也就选择0.5%作为最优误差。
在实践中,如果目的不同,可以选择不同的人群表现作为最优误差。另外当算法的train error和dev error都接近所设置的最优误差再去考虑不同的人类表现才有价值。
总结下来:
- Human-level error是Bayes error的近似。
- 如果human-level error与training error差距比training error和 dev error的差距大,那么焦点应放在减少bias上。(类似场景A)
- 如果human-level error与training error差距比training error和 dev error的差距小,那么焦点应放在减少variance上。(类似场景B)
超越人类表现
像上图这种请情况,如果你的算法已经超越了人类最好的表现,那就没有明显的途径去优化算法了。
关于机器学习超越人类的方向(如在线广告、产品推荐、物流时间预测、贷款审批)主要是在结构化的数据上(数据库),与机器相比人类并不擅长处理这类问题。人类更擅长处理自然感知的问题如图像识别,语音识别。不过随着发展,机器甚至在这方面也超越人类。
改善你模型的表现
- 首先要很好的匹配Training Set,即尽可能的降低Avoidable Bias。
- 在Training set上的良好表现很好的泛化(generalize)到dev/test set,即variance要低。
总结起来,可以分别采取的办法有:
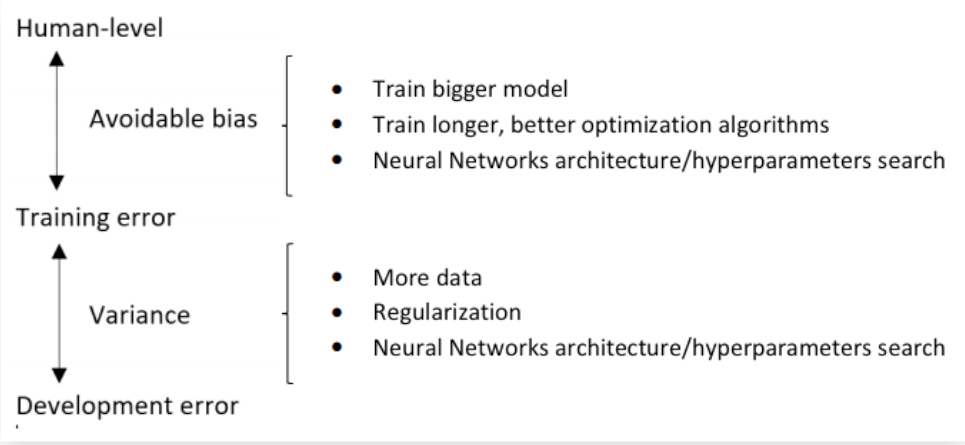
感觉这章的内容有一些都是前面提到的,感觉主要是再讲制定怎样得ML策略,以及优化神经网络的一些经验吧。