前言 本文介绍了由香港中文大学和粤港澳大湾区数字经济院联合提出的基于 Diffusion 的 Inversion 方法 Direct Inversion,可以在现有编辑算法上即插即用,无痛提点。
本文转载自PaperWeekly
作者:KK
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

导读
现有主流编辑算法大多为双分支结构,一个分支主要负责编辑,另一个分支则负责重要信息保留,Direct Inversion 可以完成(1)对两分支解耦(2)使两分支分别发挥最大效能,因此可以大幅提升现有算法的编辑效果。
同时,为了更加公平公正的进行基于 text 的编辑效果对比,这篇文章提出了 PIE-Bench,一个包含 700 张图片和 10 个编辑类别的“图片-编辑指令-编辑区域”数据集,并提供一系列包含结构保留性、背景保留性、编辑结果与编辑指令一致性、编辑时间四个方面的评测指标。数值结果和可视化结果共同展示了 Direct Inversion 的优越性。

项目主页:https://idea-research.github.io/DirectInversion/
论文链接:
https://arxiv.org/abs/2310.01506https://readpaper.com/paper/4807149696887816193
代码地址:
https://github.com/cure-lab/DirectInversion
PIE-Bench申请:
https://docs.google.com/forms/d/e/1FAIpQLSftGgDwLLMwrad9pX3Odbnd4UXGvcRuXDkRp6BT1nPk8fcH_g/viewform
视频链接:
https://drive.google.com/file/d/1HGr4ETPa7w-08KKOMhfxhngzQ9Y9Nj4H/view

这篇论文是如何发现过往方法问题,并找到新解决方案的呢?
基于 Diffusion 的编辑在近两年来一直是文生图领域的研究重点,也有无数文章从各个角度(比如效果较好的在 Stable Diffusion 的 Attention Map 上特征融合)对其进行研究,作者在文章中进行了一个比较全面的相关方法 review,并把这些方法从“重要信息保留”和“编辑信息添加”两个方面分别进行了四分类,具体可以参见原文,此处不再赘述。
这里提到了一个编辑的重点,也就是“重要信息保留”和“编辑信息添加”。事实上,这两个要点正是编辑所需要完成的两个任务,比如把图 1 的猫变成狗,那红色的背景和猫的位置需要保留,这就是“重要信息保留”;同时编辑要完成“变成狗”的任务,这就是“编辑信息添加”。
为了完成这两个任务,最为直觉,也是使用最多的方式就是:使用两个分支来完成这两件事,一个用来保留信息,一个用来添加信息。之前的编辑算法大多可以划分出这两个分支,但可能隐含在模型中或者没有显式割离,也正是在这篇文章中,作者将两个概念划分清楚并给出了过往方法的分类。
到现在为止,已经弄清楚了编辑的两个分支及其各自作用,但编辑不仅仅只需要这两个分支,还需要重要的一步,也就是 Inversion。
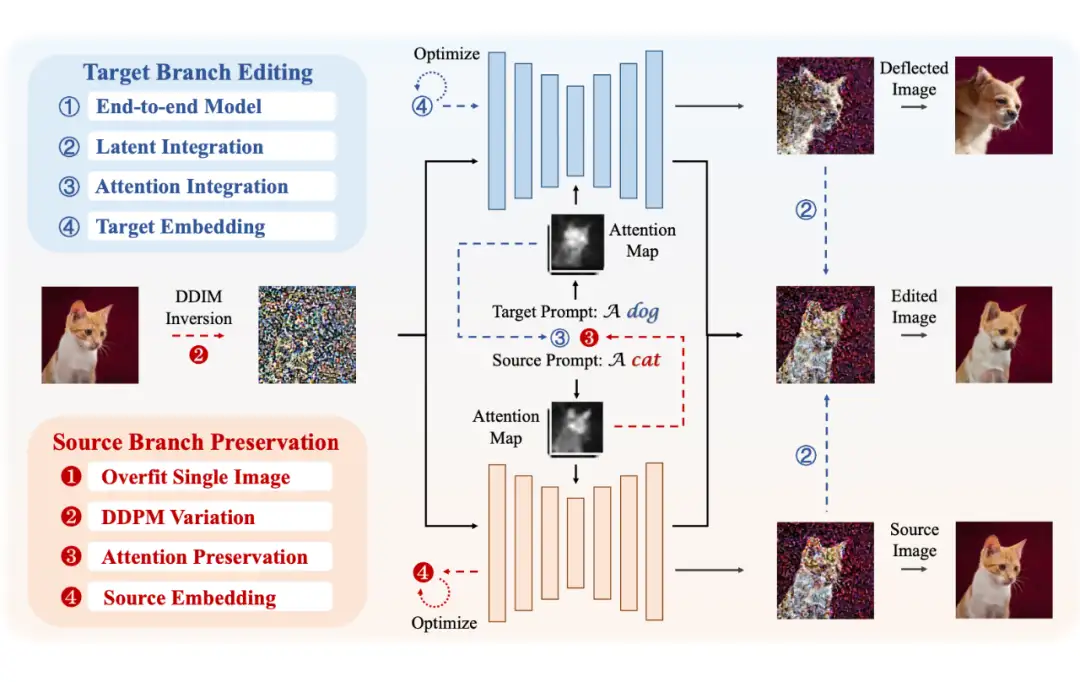
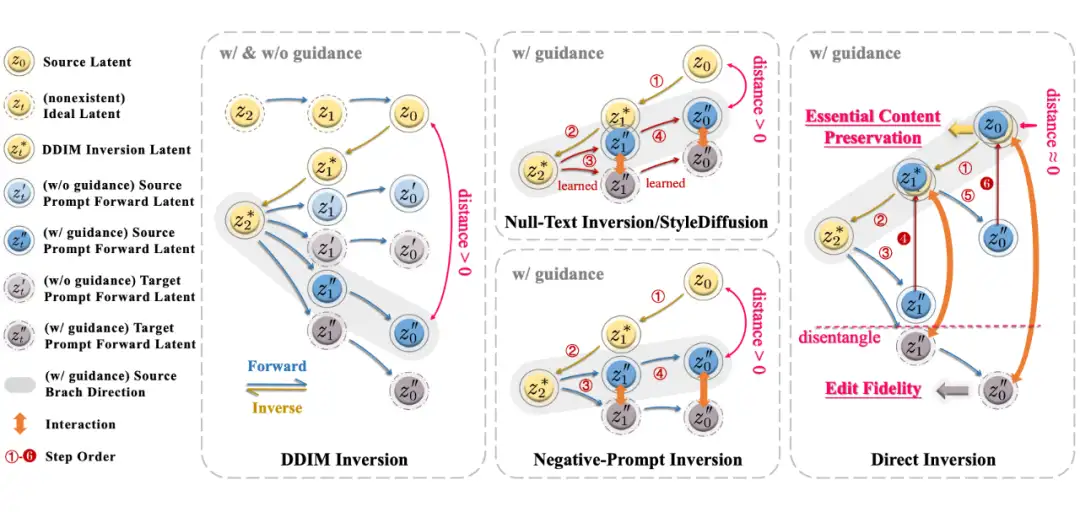
我们都知道,Diffusion 是一个把噪声映射到有用信息(比如图片)的过程,但 Diffusion 到噪声的过程是单向的,它并不可逆,不能直接像 VAE 一样直接把有用信息再映射回到隐空间,即,可以根据一个噪声得到图片,但不能根据一张图片得到“可以得到这张图片的噪声”,但这个噪声又在编辑中非常重要,因为它是双分支的起点。
所以大部分人就采用了一种近似的方法,即 DDIM Inversion,它能够将图片映射到噪声,但从这个噪声得到的新图片就会稍微偏离原图片一点(如图 DDIM Inversion 上标注的 distance),其实如果不给模型文本控制条件,偏离还不太严重,但当文本的控制加强时,偏离就会逐渐不可接受。
因此,一系列的 Inversion 方法被提出用来修正这一偏差,比如著名的基于优化的 Null-Text Inversion,而在无数方法进行尝试和探索之后,大家似乎得到了一个 common sense:好的偏离修正必须要包含优化过程。所以这篇文章就更加深入的探索了一下基于优化的 inversion(或者说修正)到底在做什么。
这些方法在优化什么?优化真的必要吗?
基于优化的 Inversion 方法通常使用一个模型输入变量(如 Null Text)存储刚刚提到的偏差,而这一偏差则作为优化过程中的 loss,通过梯度下降来拟合变量。因此优化的过程本质上就是把一个高精度的偏差存储在了一个低精度的变量中(该变量的数值精度相对 noise latent 更不敏感)。
但这种做法是存在问题的:1. 优化相当于在推导过程中训练,非常消耗时间,比如 Null-Text Inversion 通常需要两三分钟编辑一张图片;2. 优化存在误差,因此不能完全消除“偏差”,如图 2 Null-Text Inversion/StyleDiffusion 中画出的,保留分支与原始 inversion 分支之间的偏差只是被缩小并没有被消除,这就使得重要信息的保护没有发挥到最大限度;
3. 优化得到的变量其实在 Diffusion 模型训练过程中并未出现过,因此相当于进行了强制赋值,会影响模型输入和模型参数之间数据分布的协调。
回到上文提到的双分支编辑,之前的方法训练好优化的变量之后,就会将其同时送入到编辑分支和保留分支(其实不仅仅是基于优化的方法,非基于优化的方法也没有将两分支解耦),根据上面的分析,其实可以发现一个很简单的改进策略:将可编辑分支和保留分支解耦,使两个分支充分发挥各自效能。

Direct Inversion
这篇文章通过解耦编辑分支和保留分支,仅用三行代码就能够大幅提升现有编辑算法效果(如图 3 中伪代码),具体做法非常简单,即:将保留分支加回到原始 DDIM Inversion 路径,而保持编辑分支不被影响。


PIE-Bench
尽管基于 Diffusion 的编辑在近几年引起了广泛关注,但各类编辑方法的评估主要依赖于主观且不确定性的可视化。因此这篇文章为了系统验证所提出的 Direct Inversion,并对比过往 Inversion 方法,以及弥补编辑领域的性能标准缺失,构建了一个基准数据集,名为PIE-Bench(Prompt-based Image Editing Benchmark)。PIE-Bench 包括 700 张图像,涵盖了 10 种不同的编辑类型。这些图像均匀分布在自然和人工场景(例如绘画作品)中,分为四个类别:动物、人物、室内和室外。PIE-Bench 中的每张图像都包括五个注释:源图像提示语句、目标图像提示语句、编辑指令、主要编辑部分和编辑掩码。值得注意的是,编辑掩码注释(即使用一个 mask 指示预期的编辑区域)在准确的指标计算中至关重要,因为期望编辑仅发生在指定的区域内。


实验效果
6.1 数值结果
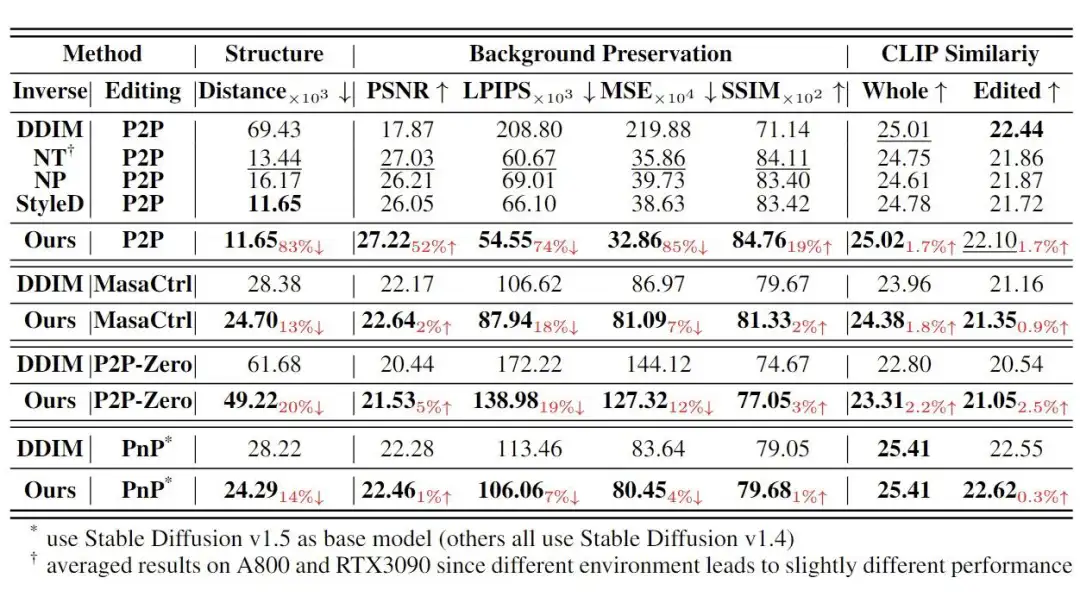
在各个编辑算法上对比不同 Inversion 和 Direct Inversion 算法效果:
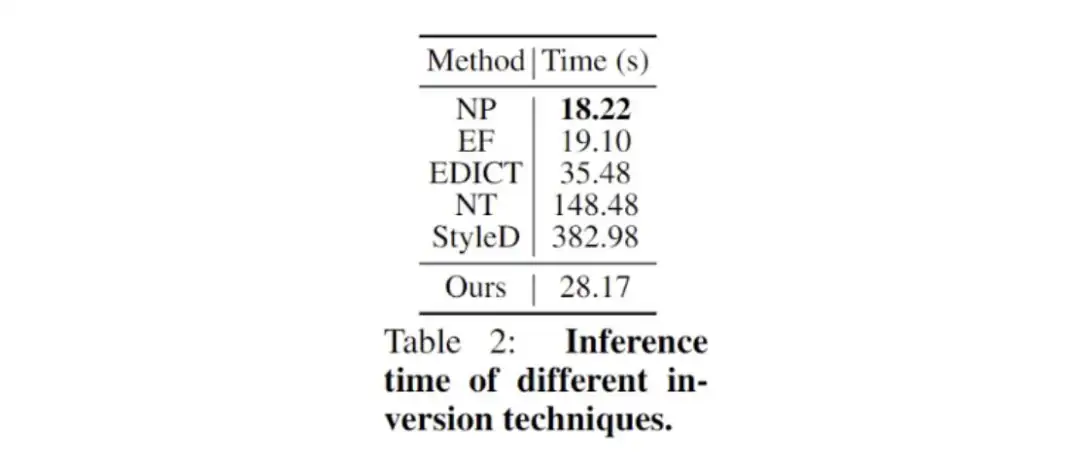
各类 Inversion 算法运行时间对比:
6.2 可视化对比
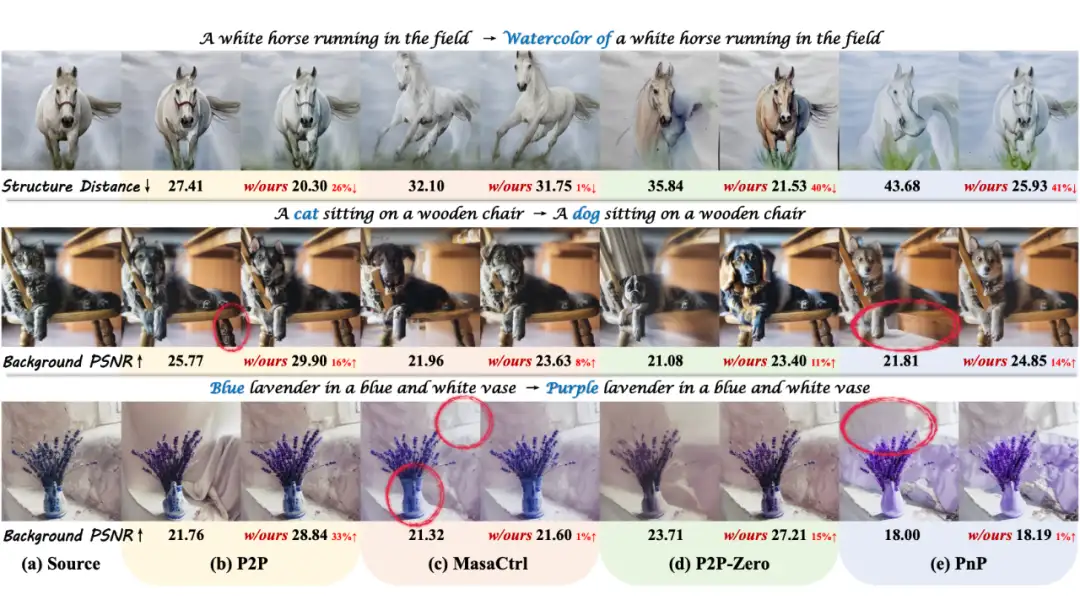

更多可视化和消融实验结果可以参考原论文。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!