摘要
准备开题报告,整理一篇 2022 年TOP 论文。
论文介绍
该论文是一篇 2022 年,有关可视化分析基于RNN 的深度强化学习训练过程的文章。一作是 Junpeng Wang ,作者主要研究领域就是:visualization, visual analytics, explainable AI。作者主页:https://junpengw.github.io/#/
主要工作
作者为了解决如何去理解和解释深度强化学习模型训练过程中产生的复杂数据变化问题,设计了一个 DRLIVE(Deep Reinforcement Learning Interactive Visual Explorer)系统,使用该系统用户可以灵活探索智能体训练过程中的数据、发现RNN网络模型有效的神经元特征以及通过像素干扰进一步交互诊断模型。

思考
如何有效探索游戏时长较大的智能体训练数据集?
问题描述
在游戏时长较大的游戏训练中(比如:一个剧集中有上千个步骤),如何更有效的处理训练产生的数据,并分析其潜在细节。
相关资料
解决方法

- 监控用户感兴趣的序列数据或指标(动作或奖励值),并可重放某部分智能体的训练过程。
- 提供步骤总览图或其他内在代表步骤数据的信息(比如:CNN不同隐藏层的激活函数值)
- 将每个剧集的 5组高维数据(Game Screens、CNN Activations、Hidden States、Cell States、Actor Logits)通过 t-SNE 降维算法将其投影为 5 组散点图,并通过计算散点之间的距离生成对应的距离分布条图,根据不同的距离阈值进行连接,得到一个连续的游戏片段,目的是用来平滑连接较小的改变,从而突出显示突然的改变的片段,因为突变常常伴随着状态的更新以及更多的注意力,便于专家探索分析。
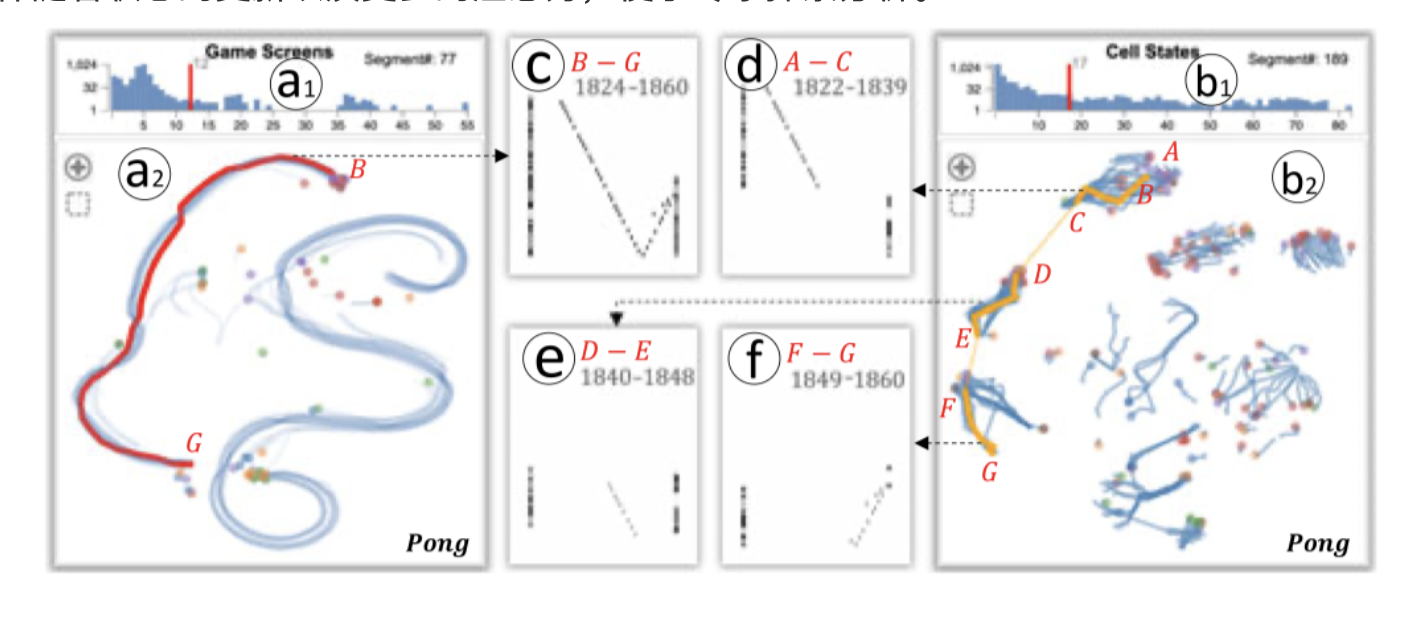
如何识别出训练过程中RNN 模型重要的隐藏层/神经元?如何了解到这些隐藏层/神经元获取到哪些特征?
问题描述
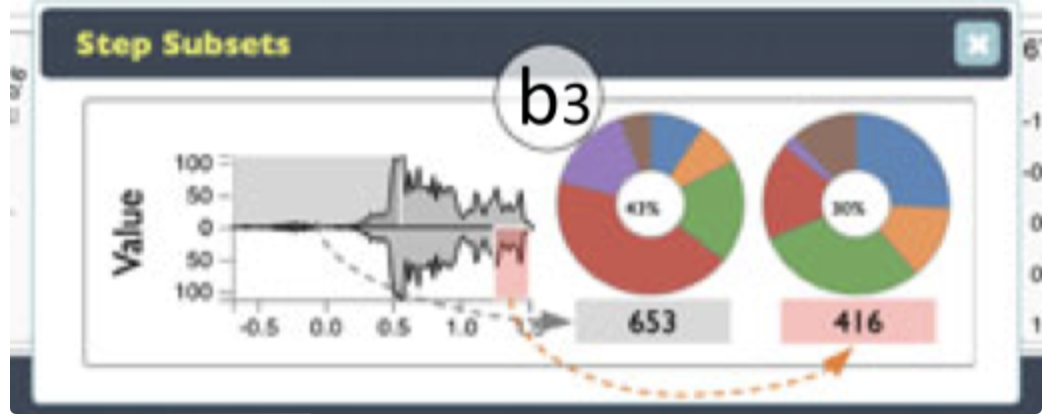
- 怎样能够捕获到模型训练中,同一步骤的两个子集的状态差异?
相关资料
解决方法

-
将 RNN 的隐藏状态和细胞状态通过公式量化后分为三组数据,第一组是:隐藏状态的标准差。第二组是:当获得评论者值和演员策略,模型中起关键作用的隐藏状态权重值,排序后找到贡献值高的状态。第三组是:隐藏状态值和评论者值(value)和演员策略(policy)的相关系数
-
通过使用 Jensen-Shannon Divergence 方法量化比较两个步骤子集的分布差异。
如何交互诊断模型训练过程中的某一步?
问题描述
相关资料
- S. Greydanus, A. Koul, J. Dodge, and A. Fern, “Visualizing and understanding Atari agents,” in Proc. 35th Int. Conf. Mach. Learn., 2018, pp. 1792–1801.
- V. R. Konda and J. N. Tsitsiklis, “Actor-critic algorithms,” in Proc.Neural Inf. Process. Syst., 2000, pp. 1008–1014.
- N. Puri et al., “Explain your move: Understanding agent actions using specific and relevant feature attribution,” in Proc. Int. Conf. Learn. Representations, 2020. [Online]. Available: https:// openreview.net/forum?id=SJgzLkBKPB
解决方法

- 使用算法处理env 画面,使用像素干扰的方式,干扰分析小球位置,从而将对应隐藏状态和细胞状态对应的维度重新进行 排序,从而发现影响力强的维数。
- Reinforcement Analytics RNN-Based Learning Visualreinforcement analytics rnn-based learning analytics visual comp 5048 reinforcement learning noise reinforcement exploration learning reinforcement transformer learning trainer reinforcement learning chapter reinforcement distillation teachable learning reinforcement transformer decision learning reinforcement exploration off-policy learning reinforcement modelling learning feedback