思路 数据 问题
0308记录之前的一些问题
1. 头文件里可以进行同名声明,编译可通过。 2. initializer element is not constant:全局变量是保存在静态存储区的,因此在编译的时候只能用常量进行初始化,而不能用变量进行初始化。全局变量的内存地址直接存储变量的值。 3. 线程的属性可通过pthread_attr ......
100 个 pandas 数据分析函数总结 转载
经过一段时间的整理,本期将分享我认为比较常规的100个实用函数,这些函数大致可以分为六类,分别是统计汇总函数、数据清洗函数、数据筛选、绘图与元素级运算函数、时间序列函数和其他函数。一、统计汇总函数数据分析过程中,必然要做一些数据的统计汇总工作,那么对于这一块的数据运算有哪些可用的函数可以帮助到我们呢 ......
使用python编写递归获取树形结构数据
``` # 使用递归做一个常用的数据库的目录树结构递归,递归的数据如果太大容易将内存给吃光掉 import json list_data = [ {'id': 1, 'name': '体育0', 'pid': 0}, # pid为0表示顶级 {'id': 2, 'name': '体育1', 'pid ......
PostgreSQL 数据库与模式(一)
基本概念 数据库管理系统(DBMS)是用于管理数据库的软件系统。常见的关系型DBMS有Oracle、MySQL、Microsoft SQL Server、PostgreSQL、Db2等。常见的NoSQLDBMS有Redis、MongoDB、Cassandra、Neo4j等。 数据库系统由实例(Ins ......
关系型数据库速度比较(性能基准测试)及python实现
https://www.sqlite.org/speed.html 做了SQLite、MySQL和PostgreSQL的速度比较,使用的数据库版本比较老,但是测试方法依旧颇有意义。 
Metric 是 Datavines 中一个核心概念,一个 Metric 表示一个数据质量检查规则,比如空值检查和表行数检查都是一个规则。Metric 采用插件化设计,用户可以根据自己的需求来实现一个 Metric。下面我们来详细讲解一下如何自定义`Metric`。 ### 第一步 我们先了解下几个 ......
MySQL数据库引擎有哪些
mysql常用引擎包括:MYISAM、Innodb、Memory、MERGE MYISAM:全表锁,拥有较高的执行速度,不支持事务,不支持外键,并发性能差,占用空间相对较小,对事务完整性没有要求,以select、insert为主的应用基本上可以使用这引擎Innodb:行级锁,提供了具有提交、回滚和崩 ......
环境变量是操作系统中存储特定值的动态命名对象。它们用于在系统级别和用户级别提供重要的配置信息和路径。以下是关于环境变量的一些常见问题和回答:什么是环境变量?为什么使用环境变量?如何设置环境变量?
环境变量是操作系统中存储特定值的动态命名对象。它们用于在系统级别和用户级别提供重要的配置信息和路径。以下是关于环境变量的一些常见问题和回答: **什么是环境变量?** 环境变量是一个保存了特定值或路径的标识符,可以在操作系统和应用程序中引用。它们通常用于指定配置信息、系统路径和用户设置。 **为什么 ......
数据安全审计:对数据可视化进行审计和评估
[toc] 数据安全审计:对数据可视化进行审计和评估 引言 随着大数据时代的到来,数据可视化成为了企业管理和决策的重要工具。数据可视化可以让我们更加直观地了解数据背后的故事,发现数据中的规律,从而更好地做出决策。然而,数据可视化也面临着一些问题。其中之一就是数据安全问题。如何确保数据的安全,防止数据 ......
元数据的国际化和跨语言支持
[toc] 《元数据的国际化和跨语言支持》技术博客文章 1. 引言 1.1. 背景介绍 随着互联网的信息爆炸式增长,数据的规模和复杂度不断增加,为了更好地组织和管理这些数据,人们需要对数据进行元数据( metadata)的描述和定义。 1.2. 文章目的 本文旨在探讨如何在软件设计和开发过程中,实现 ......
利用ApacheNiFi实现数据处理与传输的自动化管理
[toc] 利用Apache NiFi实现数据处理与传输的自动化管理 ## 1. 引言 1.1. 背景介绍 随着大数据时代的到来,企业和组织需要处理和传输海量的数据,而这些数据往往需要经过多个系统或服务进行处理和传输。传统的数据处理和传输方式往往需要手动配置和管理,容易产生错误、遗漏或安全隐患。因此 ......
城市智慧交通:基于大数据和人工智能技术的出行优化
[toc] 城市智慧交通:基于大数据和人工智能技术的出行优化 1. 引言 随着城市交通的日益繁忙和交通拥堵问题的不断加剧,城市智慧交通已成为当今研究的热点。城市智慧交通旨在通过利用大数据和人工智能技术来优化城市交通,提高交通效率和出行质量。本文将介绍基于大数据和人工智能技术的城市智慧交通的实现步骤、 ......
语言模型在文本挖掘中的应用:如何通过数据挖掘和机器学习技术发现文本中的有价值的信息
[toc] 语言模型在文本挖掘中的应用:如何通过数据挖掘和机器学习技术发现文本中的有价值的信息 1. 引言 1.1. 背景介绍 随着互联网的快速发展,文本数据量不断增加,人们对文本数据的需求也越来越高。文本数据具有丰富的信息量,对于企业、政府、金融等各行业来说,都具有重要意义。但是,如何从大量的文本 ......
基于人工智能和机器学习的数据访问控制:最佳实践和新技术
[toc] 《基于人工智能和机器学习的数据访问控制:最佳实践和新技术》 1. 引言 1.1. 背景介绍 随着大数据时代的到来,各类机构和企业为了应对海量的数据,需要采取有效数据访问控制策略来保护其核心数据资产。数据访问控制技术可以分为两类:传统技术和新兴技术。传统技术主要采用访问控制列表(ACL)和 ......
人工智能中的道德问题:如何确保机器学习算法的透明度和可解释性
[toc] 人工智能中的道德问题:如何确保机器学习算法的透明度和可解释性 1. 引言 1.1. 背景介绍 随着人工智能技术的快速发展,机器学习算法已经在各个领域取得了显著的成果,如金融、医疗、教育等。然而,这些算法在带来便利的同时,也引发了一系列道德问题。如何确保机器学习算法的透明度和可解释性,让算 ......
关系数据库中的数据库设计优化与性能提升——基于Python的关系数据库数据库设计优化与性能提升方法
[toc] 《77. 关系数据库中的数据库设计优化与性能提升——基于Python的关系数据库数据库设计优化与性能提升方法》 1. 引言 1.1. 背景介绍 随着互联网技术的快速发展,数据量日益增长,对关系数据库的管理与维护也日益复杂。传统的数据库管理工具和方式难以满足现代应用的需求,因此,关系数据库 ......
了解FaunaDB数据库的现代设计和实现最佳实践:提高性能和可维护性
[toc] 《29. 了解FaunaDB数据库的现代设计和实现最佳实践:提高性能和可维护性》 1. 引言 1.1. 背景介绍 FaunaDB 是一款高性能、高可用、易于扩展的关系型数据库,旨在提供低延迟、高吞吐量的数据存储和查询服务。FaunaDB 的设计理念和实现最佳实践在业界备受关注,其核心目标 ......
Windows Recovery Environment(简称为WinRE)是一个预安装在 Windows 操作系统中的独立环境,用于故障排除和系统恢复。它提供了一套工具和功能,可帮助用户修复无法启动或出现其他问题的计算机。
Windows Recovery Environment(简称为WinRE)是一个预安装在 Windows 操作系统中的独立环境,用于故障排除和系统恢复。它提供了一套工具和功能,可帮助用户修复无法启动或出现其他问题的计算机。 WinRE可以通过以下几种方式访问: 启动时自动进入:当您的计算机无法正常 ......
Troubleshooters(故障排除工具)是 Windows 操作系统中的一组内置工具,旨在帮助用户诊断和解决常见的计算机问题。这些工具提供了一种自动化的方式来检测并尝试解决特定类型的问题,从而简化了用户的故障排除过程
Troubleshooters(故障排除工具)是 Windows 操作系统中的一组内置工具,旨在帮助用户诊断和解决常见的计算机问题。这些工具提供了一种自动化的方式来检测并尝试解决特定类型的问题,从而简化了用户的故障排除过程。 每个故障排除工具针对不同的问题类型,并提供了特定的解决方案。以下是一些常见 ......
数据库内核:PostgreSQL 关系操作与评估
# 关系操作 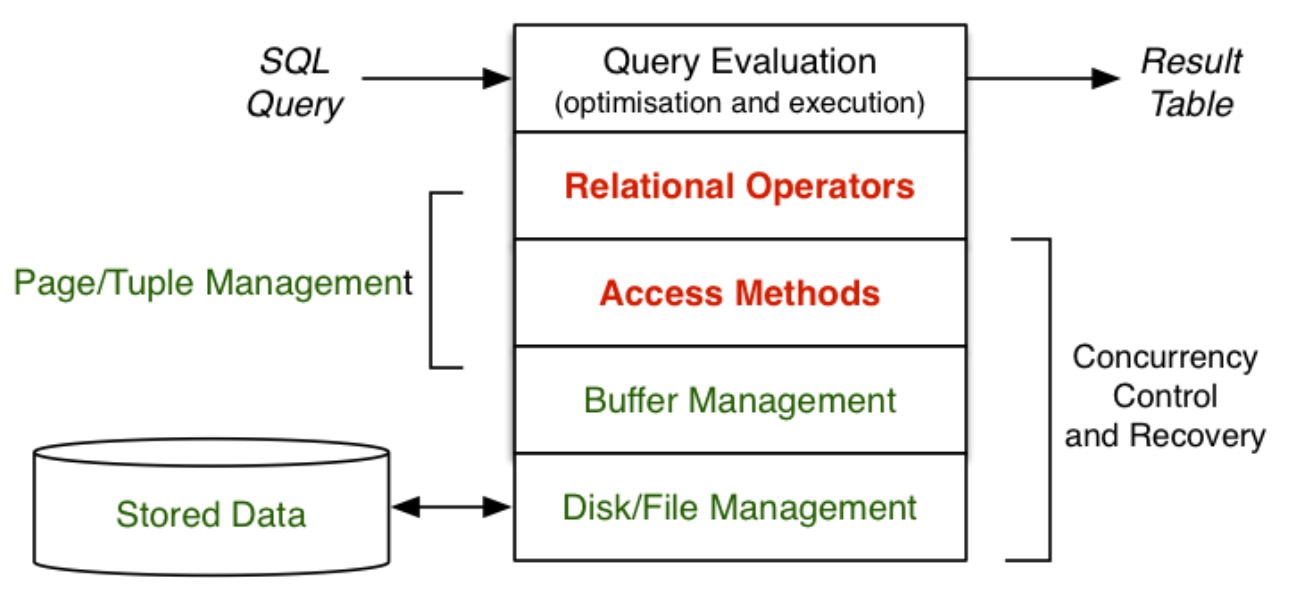 关键术语: * 元组(tuple)= 在某些模式下收集数据值 $\cong$ 记录(recor ......
Unity 使用Advanced InI Parser .Open()时读取到不存在文件路径相关问题
在使用Advanced INI Parser插件用来读写配置文件时,如果在使用插件对象的Open()方法读取不存在的文件路径时,会自动创建相应的文件,但是这里需要注意的是,插件的Open()执行的操作是:判断文件是否存在=》若存在正常打开;若不存在则创建然后关闭文件流。请注意,这里是创建后关闭,所以 ......
Python全栈学习 day06 数据类型(二)
# day06 数据类型(中) 常见的数据类型: - int,整数类型(整形) - bool,布尔类型 - str,字符串类型 - **list,列表类型** - **tuple,元组类型** - dict,字典类型 - set,集合类型 - float,浮点类型(浮点型) 目标:掌握列表和元组数据 ......
Python全栈学习 day05 数据类型(一)
# day05 数据类型(上) 接下来的3天的课程都是来讲解数据类型的知识点,常见的数据类型: - int,整数类型(整形) - bool,布尔类型 - str,字符串类型 - list,列表类型 - tuple,元组类型 - dict,字典类型 - set,集合类型 - float,浮点类型(浮点 ......
Python数据预处理
# 1 数据的生成与导入 这里主要使用的pandas ``` import pandas as pd #加载excel数据 df_excel=pd.read_excel('') df_excel.head() #加载text数据 df_text=pd.read_table('') df_text.h ......
discuz的邮件设置,密码保存及邮件数据保存位置地方
表 pre_common_setting mail auth_username后面是邮箱地址 auth_password后面是邮箱的密匙密码 图例是我修改过的abcdefghijkmn ......
lakefs 提供的数据工程现状图
此图很不错,整理了不少数据处理周边的工具,可以参考学习 参考图 参考资料 https://lakefs.io/blog/the-state-of-data-engineering-2023/ ......
Python全栈学习 day07 数据类型(三)
# day06 数据类型(下) 常见的数据类型: - int,整数类型(整形) - bool,布尔类型 - str,字符串类型 - list,列表类型 - tuple,元组类型 - **dict,字典类型** - **set,集合类型** - **float,浮点类型(浮点型)** 目标:掌握字典、 ......
TortoiseGit使用Cherry Pick遇到的问题及解决方案
## TortoiseGit的Cherry Pick 比如从master pick某一个commit 记录到其它分支(release) pick的操作方法:切到分支,点击 show log,然后在log dialog的左上角切到master,选中需要的commit记录,再右键选择cherry pic ......
R语言用非凸惩罚函数回归(SCAD、MCP)分析前列腺数据|附代码数据
使用lasso或非凸惩罚拟合线性回归,GLM和Cox回归模型的正则化,特别是_最小_最_大凹_度_惩罚_函数_(MCP)_和光滑切片绝对偏差惩罚(SCAD),以及其他L2惩罚的选项( “弹性网络”) 还提供了用于执行交叉验证以及拟合后可视化,摘要,推断和预测的实用程序。 我们研究 前列腺数据,它具有 ......