评估指标 模型 性能 指标
能「说」会「画」, VisCPM:SOTA 开源中文多模态大模型
最近, 清华大学 NLP实验室、面壁智能、知乎联合在 OpenBMB 开源多模态大模型系列VisCPM,评测显示,VisCPM 在中文多模态开源模型中达到最佳水平。 VisCPM 是一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM- ......
逼近GPT-4!BLOOMChat: 开源可商用支持多语言的大语言模型
背景 SambaNova和Together这2家公司于2023.05.19开源了可商用的支持多语言的微调模型BLOOMChat。 SambaNova这家公司专注于为企业和政府提供生成式AI平台,Together专注于用开源的方式打造一站式的foundation model,赋能各个行业。 OpenA ......
开源中文大型语言模型(资源汇总
随时更新!汇总2023年开源的大型中文大规模语言模型,入选标准: 对中文支持能力强 模型规模 ≥ 1B 公布模型权重、推理代码 公布模型训练细节 Chinese-Vicuna 项目地址:https://github.com/Facico/Chinese-Vicuna 基座模型:LLaMA 7B 特点 ......
开源大模型新SOTA,支持免费商用,比LLaMA65B小但更强
号称“史上最强的开源大语言模型”出现了。 它叫Falcon(猎鹰),参数400亿,在1万亿高质量token上进行了训练。 最终性能超越650亿的LLaMA,以及MPT、Redpajama等现有所有开源模型。 一举登顶HuggingFace OpenLLM全球榜单: 除了以上成绩,Falcon还可以只 ......
截至2023年5月份目前业界支持中文大语言模型开源和商用许可协议总结
原文有模型链接与更新信息。 目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。 上图是Dat ......
性能认证+最佳案例,阿里云 ACK@Edge 产品技术、落地能力获信通院综合认可
大会现场对领域近期权威成果进行了颁奖公示,阿里云边缘容器服务 ACK@Edge 以“2023 大规模边缘容器集群服务质量和关键性能评测”、“2023 边缘计算技术创新与实践最佳案例”两项结果,展示了其产品服务能力在大规模性能、企业落地生产维度优秀的综合能力。 ......
中小型系统必要可行的性能测试实践--jmeter落地实践
为什么选择jmeter,业界用的广而且免费。本篇着重如何具体的开展性能测试:应该做哪些类型的性能测试?每种类型下采用什么类型线程组?每种类型监控数据的角度?在具体场景下的思路、具体配置? 一、性能场景的分析与创建压测的场景来源于性能需求,性能需求侧重点不同,选择的测试场景和压测类型也不相同。对于旧系 ......
MegEngine 使用小技巧:如何使用 MegCC 进行模型编译
本文将重点解析模型部署中的重要步骤之一-模型编译:编译 MegEngine 模型,生成运行这个模型对应的 Kernel 以及和这些 Kernel 绑定的模型。 ......
如何避免模型数据的偏差?
当数据集存在偏差时,训练出的模型可能会对某些类别或观点表现出倾向性,而忽略其他类别或观点。这种偏差可能会导致不公平的结果或误导性的决策。因此,消除训练数据中的偏差至关重要。 训练数据可能存在多种类型的偏差。以下是一些常见的数据偏差类型: 1. 标签偏差(Label Bias):标签偏差是指训练数据集 ......
31.性能优化
首页加载很慢的原因: 1. 由于vendor.js和app.css较大,VUE等主流的单页面框架都是js渲染html body的,所以必须等到vendor.js和app.css加载完成后完整的界面才会显示。 2. 单页面首次会把所有界面和接口都加载出来,会有多次的请求和响应,数据不能马上加载,二者相 ......
【资料分享】RK3568评估板规格书(4x ARM Cortex-A55(64bit),主频1.8GHz)
1 评估板简介 创龙科技TL3568-EVM是一款基于瑞芯微RK3568J/RK3568B2处理器设计的四核ARM Cortex-A55国产工业评估板,每核主频高达1.8GHz/2.0GHz,由核心板和评估底板组成。核心板CPU、ROM、RAM、电源、晶振、连接器等所有器件均采用国产工业级方案,国产 ......
探讨优化Flutter性能的一些思路
一直以来,Flutter都是公认的非常强大的一套移动应用开发框架。在我们进行技术架构选型时,我们选择了Flutter,尤其是它出色的跨端能力让我们印象深刻。然而,随着我们在复杂的应用程序实现中深入使用,我们逐渐发现了App性能方面的一些影响。 ......
开源大语言模型是否可以商用的调查报告
开源大语言模型是否可以商用的调查报告 0. 背景 1. 调查结果 1.1 基础大模型(LLM) 1.2 对话大模型(ChatLLM) 1.3 多模态对话大模型(MultiModal-ChatLLM) 2. 可商用开源模型总结 2.1 基础大模型(LLM) 2.2 对话大模型(ChatLLM) 0. ......
python基础 如何查看进程的id号、队列的使用(queue)、解决进程之间隔离关系、生产者消费者模型、线程
如何查看进程id号 进程都有几个属性:进程名、进程id号(pid-->process id)每一个进程都有一个唯一的id号, 通过这个id号就能找到这个进程 import os import time def task(): print("task中的子进程号:", os.getpid()) pri ......
数据密集型应用系统设计:数据模型与查询语言
1、现在大多数应用开发都采用面向对象的编程语言,由于兼容性问题,普遍对SQL数据模型存在抱怨:如果数据存储在关系表中,那么应用层代码中的对象与表、行和列的数据库模型之间需要一个笨拙的转换层。模型之间的脱离有时被称为阻抗失谐。 2、拥有地理区域和行业的标准化列表,并让用户从下拉列表或自动填充器中进行选 ......
Java实现自定义指标数据远程写入Prometheus
最近在看夜莺的记录规则这部分功能实现,其中新增记录规则之后需要远程写入prometheus,而对于这部分功能实现,夜莺使用的是Go实现,由于项目使用Java开发,所以针对这部分功能,只能进行重写。下面内容为抽取出来的主要代码实现,仅做记录说明。 主要的流程如下: 1> prometheus添加启动参 ......
Redis基础、高级特性与性能调优——一篇文章搞定
本文将从Redis的基本特性入手,通过讲述Redis的数据结构和主要命令对Redis的基本能力进行直观介绍。之后概览Redis提供的高级能力,并在部署、维护、性能调优等多个方面进行更深入的介绍和指导。本文适合使用Redis的普通开发人员,以及对Redis进行选型、架构设计和性能调优的架构设计人员。 ......
C++内存模型&空指针、野指针、函数指针和回调函数
C++内存模型&空指针、野指针、函数指针和回调函数 C++内存模型 栈与堆的区别: 1.管理方式不同 栈是系统自动管理的,在超出作用域后,将自动被释放 堆是手动释放,若程序中不释放,程序结束后将由操作系统回收 2.空间大小不同 堆的大小受限于物理内存范围 栈小的可怜,一般为8M(可通过更改系统配置来 ......
22年11月Tita360评估题库上线
1. 支持设计问卷时,从题库批量导入题目 Tita - OKR和新绩效一体化管理平台 使用场景:企业之前没有做过360评估活动,不知道如何创建合适的问卷;或者企业想用一些新的不同维度的题目进行评估 2. 活动发布后新增的被评估人增加未发放标识 使用场景:在活动发布后新增大量被评估人后,无法确认对应的 ......
R语言独立成分分析fastICA、谱聚类、支持向量回归SVR模型预测商店销量时间序列可视化|附代码数据
全文链接:http://tecdat.cn/?p=31948 原文出处:拓端数据部落公众号 本文利用R语言的独立成分分析(ICA)、谱聚类(CS)和支持向量回归 SVR 模型帮助客户对商店销量进行预测。 首先,分别对商店销量的历史数据进行了独立成分分析,得到了多个独立成分;其次,利用谱聚类方法将商店 ......
R语言关联规则挖掘apriori算法挖掘评估汽车性能数据|附代码数据
被客户要求撰写关于关联规则挖掘的研究报告,包括一些图形和统计输出。 我们一般把一件事情发生,对另一件事情也会产生影响的关系叫做关联。而关联分析就是在大量数据中发现项集之间有趣的关联和相关联系(形如“由于某些事件的发生而引起另外一些事件的发生”)。 我们的生活中有许多关联,一个典型例子是购物篮分析。该 ......
单细胞生物学基础大型语言模型scGPT
生成式预训练模型在自然语言处理(NLP)和计算机视觉等领域取得了显著的成功。 文本是由文字组成的,细胞可以用基因来表征。 NLP 和单细胞生物学之间的另一个核心相似之处是,用于训练的公开可用的单细胞 RNA 测序(scRNA-seq)数据的规模庞大且不断增长。 NLP 模型是否也能理解单细胞生物学的 ......
cesium模型位置调整
使用经纬度坐标创建entity let circle01 = viewer.entities.add({ // position: new Cesium.Cartesian3(-2458283.9120733286, 4760603.561249552, 3448793.686233579), po ......
使用部分写时复制提升Lakehouse的 ACID Upserts性能
## 使用部分写时复制提升Lakehouse的 ACID Upserts性能 译自:[Fast Copy-On-Write within Apache Parquet for Data Lakehouse ACID Upserts](https://www.uber.com/en-ZA/blog/f ......
MosaicML 推出 300 亿参数模型
导读 AI 创业公司 MosaicML 近日发布了其语言模型 MPT-30B,单从参数来看,这个模型具有 300 亿参数,放在如今动则上千亿参数的模型领域中并没有什么突出的地方。但这个新模型的训练成本却只有其他模型的零头,有望扩大模型在更广泛领域的运用。 MosaicML 的首席执行官兼联合创始人 ......
Final2x - 开源图片放大工具,支持9 款模型,可提高图像分辨率
- Final2x - 开源图片放大工具,支持9 款模型,可提高图像分辨率 ... - [下载地址](https://github.com/Tohrusky/Final2x/releases)  1、Network Slimming剪枝理论 Network Slimming剪枝是结 ......
OSI TCP/IP模型 数据包报帧区别(自用)
# OSI七层模型 OSI(Open System Interconnection Reference Model,开放式通信系统互联参考模型) 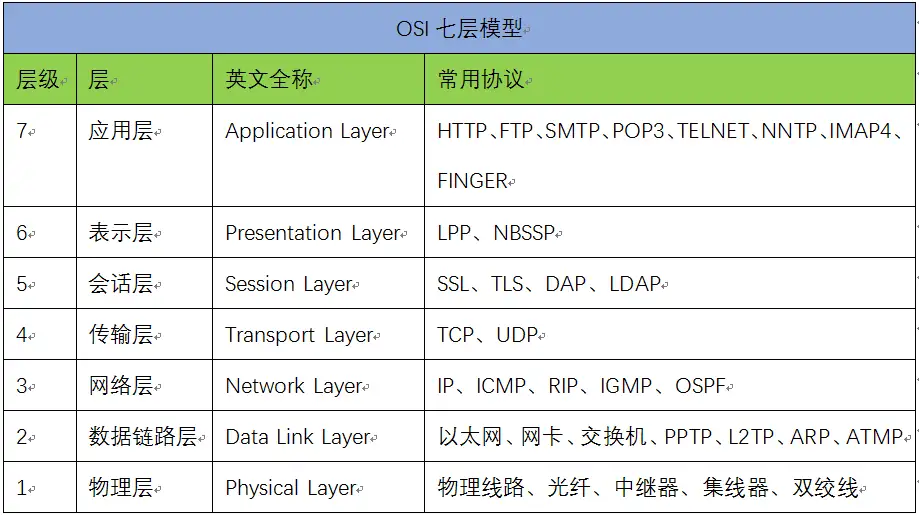 ......