flink wordcount demo job
Flink - 概述
官网:https://flink.apache.org/ Flink 是什么 为什么选择Flink 流处理的应用场景 Flink的特点 Flink 是什么 是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能。 是一个框架和分布式处理引擎,用于对无界和有界数 ......
Flink的几种Join总结
# Regular join组 第一种: left join 流任务中,只要left的流数据到了,就输出。如果右边流没有到,输出 [L,NULL];如果右边流到了,输出 [L, R] 第二种: right join 流任务中,只要right的流数据到了,就输出。如果左边流没有到,输出 [NULL,R ......
Hadoop - hadoop自带MR案例:词频 WordCount
词频 Word Count 1、在浏览器上访问 https://node01:9870 2、创建目录 /user 目录 bin/hdfs dfs -mkdir /user 如果未配置环境变量,需要到hadoop安装目录下执行 /opt/module/hadoop-2.5.2(这个是我的安装目录) 3 ......
net core-Scheduling Background Jobs With Quartz
一 安装包 Install-Package Quartz.Extensions.Hosting 二 注入依赖关系 services.AddQuartz(configure => { configure.UseMicrosoftDependencyInjectionJobFactory(); }); ......
flink源码分析--RPC通信过程分析
flink的通信框架基于akka,但是不懂akka也关系不大。 首先介绍几个概念,大家记住名字和对应的作用: xxxGateway:在flink中就是一个用来告诉调用者,xxx具有哪些方法可以调用的一个接口类。比如JobMasterGateway就是用来告诉所有需要调用JobMaster的用户,我J ......
错误记录:创建mysql+springboot的demo报BeanCreationException: Error creating bean with name 'roleRepository' defined in xx.repository.RoleRepository defined in @EnableJpaRepositories declared on JpaConfigration
java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.lo ......
chatglm_langchain_demo
#Setup envirnment conda create -n langchain python=3.8.1 -y conda activate langchain # 拉取仓库 git clone https://github.com/imClumsyPanda/langchain-ChatG ......
flink双流join底层如何实现的
Flink是一个分布式流处理框架,它提供了丰富的操作符来处理流数据。双流(join)操作是其中一个常用的操作,用于将两个流的数据按照指定的条件进行关联。Flink的底层实现使用了一种称为“流的连接”(stream co-processing)的技术。 在Flink中,双流(join)操作通过以下步骤 ......
flink双流join时间窗口过大导致的问题
当Flink双流(join)操作的时间窗口过大时,可能会导致以下问题: 1. 内存消耗:时间窗口大小直接影响Flink系统的内存消耗。较大的时间窗口会导致需要维护更多的状态数据,从而占用更多的内存资源。 2. 延迟增加:大时间窗口可能会导致延迟增加。如果窗口的大小超过了数据流的延迟,那么在触发窗口计 ......
flink的双流join的2个流必须都是滑动窗口吗
不,Flink的双流(join)操作并不要求两个流都是滑动窗口。在双流(join)操作中,每个流可以使用不同类型的窗口,包括滑动窗口、滚动窗口或其他类型的窗口。 在Flink中,可以对每个输入流分别定义不同的窗口类型和参数,以满足实际的业务需求。只要两个流在关联键上能够匹配,并且窗口定义能够适配,就 ......
flink中的广播流实例
在Flink中,广播流(Broadcast Stream)是一种特殊的数据流类型,用于将一个数据流广播到所有并行任务中,以供每个任务共享和使用。广播流通常用于将静态数据(如维表数据)发送给所有任务,以便任务可以在本地缓存该数据,避免多次访问外部存储系统。 广播流的特点如下: - 广播流只有一个并行度 ......
flink的状态表需要保存多久
Flink的状态表保存的时间可以根据应用程序的需求进行配置。状态表的保留时间取决于两个因素: 1. **状态后端(State Backend)的配置**:Flink支持不同类型的状态后端,如内存、文件系统、RocksDB等。不同的状态后端可以配置不同的状态保留策略。例如,如果使用基于内存的状态后端, ......
flink从检查点恢复时候做什么
当发生故障时,Flink从最近的一致性检查点中恢复任务的状态。以下是从检查点恢复的主要步骤: 1. **加载检查点元数据和状态数据**:Flink首先加载最近一次成功的检查点的元数据和持久化的状态数据。检查点的元数据包含了关于检查点的信息,如检查点ID、生成时间和相关的任务信息等。持久化的状态数据包 ......
使用Redis作为维表输入的Flink示例代码
下面是一个使用Redis作为维表输入的Flink示例代码: ```java import org.apache.flink.api.common.functions.RichFlatMapFunction; import org.apache.flink.api.common.state.MapSt ......
flink的各个算子在收到barrier的时候会做什么
在Flink中,各个算子(算子链中的每个算子)在收到 barrier(检查点屏障)时会执行以下操作: 1. **算子状态快照**:算子会触发对其状态的快照操作,以捕获当前状态的一致性快照。这包括算子的运行时状态、缓冲区或累加器等数据。 2. **处理挂起输入数据**:算子会将收到的 barrier ......
flink中一个多输入的算子如何决定是否可以往下游算子发送barrier
在Flink中,多输入的算子在决定是否可以往下发 barrier 时需要满足以下条件: 1. **输入流的 barrier 对齐**:多输入的算子必须要求所有输入流都处于 barrier 对齐状态,即收到了相同的 barrier。这意味着所有输入流的上游任务都已经收到了相同的 barrier,并向下 ......
demo测试
1.测试测试 ```json { "code": 200, "msg": "", "data": { "id": 23, "userId": 17, "name": "demo1", "content": "发的范德萨范德萨分", "picUrl": "http://localhost:9090/f ......
docker 部署xxx-job
1 拉取镜像: docker pull xuxueli/xxl-job-admin:2.3.0 2 创建容器: docker run -d --privileged -e PARAMS="--spring.datasource.url=jdbc:mysql://1.15.242.247:3306/x ......
Flink CDC
# **第1章 CDC简介** ## 1.1 什么是CDC CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 ## 1 ......
bloomFilter_demo
参考博客:(14条消息) 布隆(Bloom Filter)过滤器入门_布隆过滤器入门_qq_39093474的博客-CSDN博客 5 分钟搞懂布隆过滤器,亿级数据过滤算法你值得拥有! - 知乎 (zhihu.com) BloomFilterTest.java package com.hmb; imp ......
netty入门demo
参考博客:(14条消息) 【Netty整理01-快速入门】Netty简单使用Demo(已验证)_the_fool_的博客-CSDN博客 ServerHandler.java package com.hmb; import io.netty.buffer.ByteBuf; import io.nett ......
异步爬虫demo2
~~~python import re import aiohttp import asyncio class Asyn: def __init__(self): self.__headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win6 ......
demo阐述js中let和var 的不同
当我们使用 var 和 let 来声明变量时,它们在作用域和变量提升方面的差异会产生一些不同的结果。下面是一个示例来说明这些差异。 ``` // 使用 var 声明变量 function varExample() { console.log(x); // 输出 undefined var x = 1 ......
Flink中的Window和Time详解
### Window(窗口) Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。 通常来讲,Window是一种可以把无界数据切割为有界数据块的手段 例如,对流中的所有元素进行计 ......
Flink核心API之Table API和SQL
### Table API & SQL 注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现Flink中所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。 Table API和SQL的由来: Flink针对标准的流处理和批处理提供了两种 ......
Flink核心API之DataSet
### DataSet API DataSet API主要可以分为3块来分析:DataSource、Transformation、Sink。 DataSource是程序的数据源输入。 Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap、filt ......
Flink核心API之DataStream
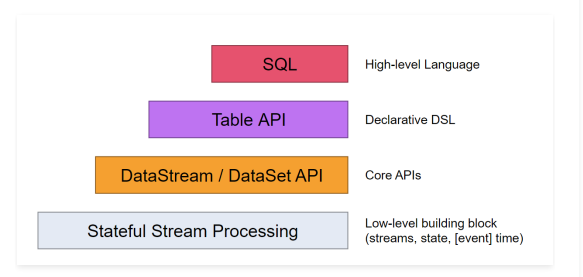 Flink中提供了4种不同层次的API,每种API在简洁和易表达之间有自己的权衡,适用于不同的场景。目前 ......
Flink安装部署
### Flink集群安装部署 Flink支持多种安装部署方式 - Standalone - ON YARN - Mesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境 ......
Flink详解
### 什么是Flink Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。 分布式:表示flink程序可以运行在很多台机器上, 高性能:表示Flink处理性能比较高 高可用:表示flink支持程序的自动重启机制。 准确的:表示flink可以保证处理数据的准确性。 Fl ......