hadoop spark
HDFS的shell命令(Hadoop fs [参数])
hadoop fs -ls file:/// 操作linux本地文件系统 hadoop fs -ls hdfs://node1:8020/ 操作HDFS分布式文件系统 hadoop fs -ls / 直接根目录,没有指定协议 将加载读取fs.defaultFS值 标准的hadoop上传文件命令: h ......
3.2.0 终极预告!云原生支持新增 Spark on k8S 支持
 视频贡献者 | 王维饶 视频制作者 | 聂同学 编辑整理 | Debra Chen > Apache ......
8.21-8.27学习总结博客七:Spark机器学习与实时处理
博客题目:学习总结七:Spark机器学习与实时处理入门内容概要:学习使用Spark进行机器学习和实时数据处理的基本知识,了解Spark的机器学习库和实时处理框架。学习资源:推荐的Spark机器学习和实时处理教程、案例和学习资源。实践内容:通过编写Spark应用程序,实践使用Spark进行机器学习和实 ......
使用hadoop进行单词统计
# 1、启动hadoop 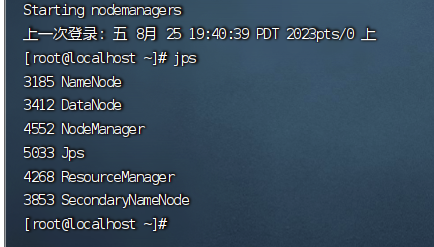 启动成功! # 2、将result.txt文件放到/root/software/hado ......
Spark任务提交到Yarn状态一直是Accepted
## 现象 今天提交 Spark 任务到 Yarn 集群,但是任务状态一直是 Accepted: ``` 23/08/25 14:59:55 INFO Client: Application report for application_1692971614101_0018 (state: ACCE ......
Hadoop 和 Spark 简介
# Hadoop 和 Spark 简介 Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop 过去一直是大数据的经典解决方案,它包含两个部分:Hadoop HDFS 和 Ha ......
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!问题的解决
# 问题描述 上次还是初始化很快,这次直接出错,我觉得可能是已经初始化一次的原因; 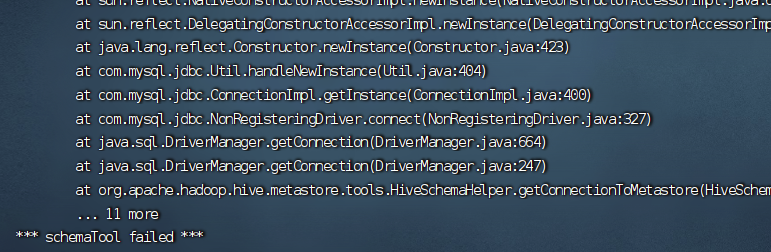 # 问题解决 进入到mysql ......
Hadoop概念地图
## Hadoop 发展史及生态圈 1,hadoop 的发展史,基于GFS,MAPREDUCE,BIGDATA >Hive 2,hadoop 生态圈。core,hdfs,mapreduce,hive,zookeeper.hbase,kafka,Flume,Sqoop,Mahout,Pig等 3,ha ......
Hadoop概述
# Hadoop 作用 解决分布式存储和分布式计算的可靠的,可扩展的,高容错的开源框架 其下面有四个模块的内容: Hadoop Common:支持其他Hadoop模块的常用工具。 Hadoop分布式文件系统(HDFS™):提供对应用程序数据的高吞吐量访问的分布式文件系统。 Hadoop YARN:作 ......
Hadoop集群环境安装
### 1,集群环境准备 ``` 准备jdk 环境,本文用的版本是,java version "1.8.0_102" 为机器准备ssh 客户端和服务端,ubuntu 环境下默认安装了客户端,那么,请安装服务端, apt-get install openssh-server 可以的话尽量不要用root ......
Hadoop知识点
### 1,概念 ``` Hadoop是一个开源的、可运行于大规模集群上的分布式并行编程框架,它实现了 Map/Reduce计算模型。 ``` ### 2,核心所在。 ``` 1,Hadoop分布式文件系统(HDFS,Hadoop Distributed File System) datanode ......
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable问题的解决
# 问题描述 使用**start-dfs.sh**命令开启hdfs服务时,爆出这样的警告信息  # 问题解决 可以先 ......
apache spark connect 试用
spark connect 3.4 开始就支持了connect 模式,3.4.1 比较稳定了 connect server 启动 实际上就是一个spark 引用,通过spark_submit 提交到spark 环境中 启动 ./sbin/start-connect-server.sh --packa ......
Spark RDD惰性计算的自主优化
原创/朱季谦 RDD(弹性分布式数据集)中的数据就如final定义一般,只可读而无法修改,若要对RDD进行转换或操作,那就需要创建一个新的RDD来保存结果。故而就需要用到转换和行动的算子。 Spark运行是惰性的,在RDD转换阶段,只会记录该转换逻辑而不会执行,只有在遇到行动算子时,才会触发真正的运 ......
解密Hadoop生态系统的工作原理 - 大规模数据处理与分析
在当今的数字时代,大规模数据处理和分析已经成为了企业和组织中不可或缺的一部分。为了有效地处理和分析海量的数据,Hadoop生态系统应运而生。本文将深入探讨Hadoop生态系统的工作原理,介绍其关键组件以及如何使用它来处理和分析大规模数据。 ## 什么是Hadoop? Hadoop是一个开源的分布式计 ......
Hadoop部署HDFS集群 启动后只有node1有进程,node2和node3没有反应
最近有人向我询问说:为什么他的HDEF集群一键启动时只有node1进程有反应,node2和node3没有反应 我看完他的问题之后,想到了自己在部署时也遇到了同样的问题,现在来分享一下自己的解决方案 出现这种情况的主要原因是:workers文件没有配置好 解决方法: 输入:vim /export/se ......
spark on k8s 开发部署简单实践
实际上就是一个简单的实践,方便参考,对于开发以及运行,集成ci/cd 以及dophinscheduler 任务调度为了方便开发的spark 应用共享以及使用基于s3 进行文件存储(当然dophinscheduler 也是支持自己的资源库的) 参考图 玩法说明 基于gitlab 进行代码管理,通过ci ......
hadoop开发案例
本次基于陌陌数据案例实现可视化数据分析 数据准备:两个tsv文件,总计包含14w条数据,数据字段包括发送人,接收人 账号,性别,GPS坐标等20多个字段,这些字段利用制表符进行分隔开,其中有为null的杂乱数据,需要将这些数据过滤,时间数据格式为年月日时分秒,需要substr()进行截取,GPS坐标 ......
大数据技术Spark之RDD基础编程
# 大数据技术Spark之RDD基础编程 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据 处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行 计算的集合。 ### 一、RDD的两种创建方式 1. ......
hbase报错 ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
hbase报错:hbase shell能打开 网页也能打开 但是一执行命令就开始报错。 原因:hadoop的安全模式打开。 解决方法:关闭安全模式 ,再重新启动HBase就可以了。 具体的命令: 1、查看namenode是否是安全状态 hadoop dfsadmin -safemode get Sa ......
Spark安装的配置相关步骤
# 1、Spark下载地址:https://archive.apache.org/dist/spark/ 选择自己适合的版本:  S ......
Hadoop3.3.0--Linux编译安装
### Hadoop3.3.0--Linux编译安装 本实验内容教程来源于“黑马程序员”如有侵权请联系作者删除 基础环境:Centos 7.7 编译环境软件安装目录 ``` mkdir -p /export/server ``` #### 一、Hadoop编译安装(选做) > ==可以直接使用课程提 ......
hadoop 问题集
1.Hadoop "Cannot create directory .Name node is in safe mode."解决方案 hadoop dfsadmin -safemode leave 2.本地eclipse连接外网Hadoop 通过查询发现,外网中的hadoop如果想要被外网访问,需要 ......
Spark异常总结
1、Spark读写同一张表报错问题Cannot overwrite a path that is also being read from 问题描述:Spark SQL在执行ORC和Parquet格式的文件解析时,默认使用Spark内置的解析器(Spark内置解析器效率更高),这些内置解析器不支持递 ......
spark中decode函数
decode函数 decode(bin, charset) - 使用第二个参数字符集解码第一个参数。 decode(expr, search, result [, search, result ] ... [, default]) - 解码比较 expr 对每个搜索值一一进行。如果 expr 等于搜 ......
spark3的bug
1.[SPARK-39936][SQL] Store schema in properties for Spark Views,spark视图保存到hive metastore时未清空tableschema导致解析失败 Hive DataType解析器主要发生在Hive的元数据存储(Hive Met ......
Hadoop - WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform...
# Hadoop - WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... 配置完hadoop启动的时候出现如下警告信息: ```shell WARN util.NativeCode ......