hadoop spark
[42000][3] Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask.
[42000][3] Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job fai ......
hadoop 简介
[TOC] ## hadoop 的三大组件和关系 ### 1. HDFS:分布式文件系统 > #### hdfs 的特点和不适用使用场景 >> 1.1 HDFS文件系统可存储超大文件(不适用有大量小文件场景和小量场景,默认块大小是MB,资源浪费) >> 1.2 一次写入,多次读取(不适用多用户更新, ......
Spark概述
# Spark概述 ## 1.1认识Spark 背景:现有的计算框架有:批处理:MapReduce、Hive、Pig…,流式计算:Storm,交互式计算:Impala,Presto,但没有一种框架兼容以上所有的计算框架,spark应运而生 ### 1.1.1 Spark的发展 2009年由Berke ......
Spark编程
# Spark编程  ![image-2020042409271958 ......
Spark SQL
# Spark SQL ## 1.1Spark SQL简介 Spark SQL是一个用来处理结构化数据的Spark 组件。它可被视为一个分 布式的SQL查询引擎,并且提供了一个叫作DataFrame的可编程抽象数据模型。Spark SQL的前身是Shark,由于Shark需要依赖于Hive而制约了S ......
Spark提交程序到Yarn任务状态一直为Accepted
正在学习《Spark快速大数据分析》第七章-在集群上运行Spark,写了一个单词数量统计的Spark程序提及到Yarn,但是状态一直是Accepted,等待运行。 1、排查了Yarn资源调度器配置,配置的是公平配置,确认无问题 ```xml yarn.scheduler.fair.allocatio ......
Hadoop----hdfs dfs常用命令的使用
-mkdir 创建目录 hdfs dfs -mkdir [-p] < paths> -ls 查看目录下内容,包括文件名,权限,所有者,大小和修改时间 hdfs dfs -ls [-R] < args> -put 将本地文件或目录上传到HDFS中的路径 hdfs dfs -put < localsrc ......
spark社区bug
1.SPARK-26114repartitionAndSortWithinPartitions 后合并时 PartitionedPairBuffer 的内存泄漏 原因 这个Spark源码的issue描述了在使用coalesce操作合并分区时可能会导致PartitionedPairBuffer内存泄漏 ......
Spark安装(黑马程序员文档)
Spark Local环境部署 下载地址 Spark https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.4.1/ Anaconda https://mirrors.tuna.tsinghua.edu.cn/anaconda/archi ......
Hadoop初体验
# 1、HDFS初体验 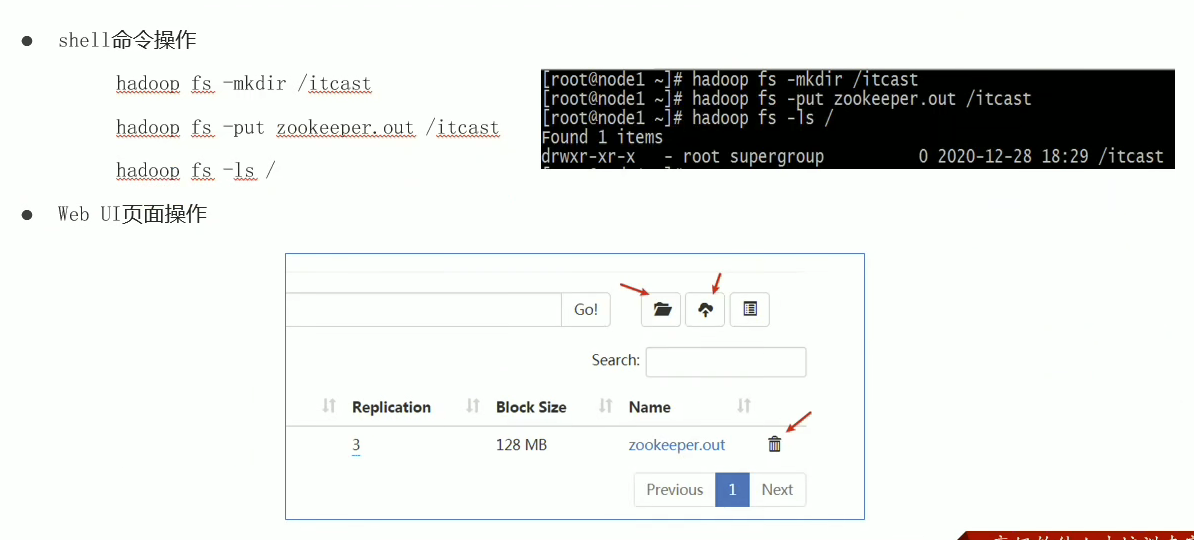 既能够通过后台的终端命令进行文件的管理,也可以通过Web UI界面进行相关的操作; 可以知 ......
Hadoop集群启停命令以及Web UI界面的相关介绍
# 1、Hadoop集群的启停命令(我是将文件都配置好了,直接使用最方便的启停命令就能进行使用) ``` start-all.sh stop-all.sh ``` # 2、HDFS集群的Web UI界面  ``` cd ../.. ```  ......
Linux系统下安装Hadoop环境
# 安装Hadoop的话,是在安装好JDK和MYSQL之后的环境下进行的;还没有安装的话,可以跳转到安装jdk环境(https://www.cnblogs.com/liuzijin/p/17591188.html) # 和安装mysql环境(https://www.cnblogs.com/liuzi ......
Hadoop:哪个数据节点是最近的数据节点来检索数据以及节点如何实现容错性
# Q1 who can decide which Data Node is the closest datanode to retrieve the data? 当客户端要读一个文件的某个数据块时,它就需要向NameNode节点询问这个数据块存储在哪些DataNode节点上,这个过程如下图: API,然后展示如何使用 Java、Scala 以及 Python 编写一个 Spark 应用程序。 >Spark 2.0 版本之前, Spark 的核心编程接口是弹性分布式数据集(RDD)。Spa ......
Hadoop集群相关理解
# Hadoop集群简介  # Hadoop集群模式安装 # 安装包获得 ## Hadoop安装包、源码包下载地址: ......
spark dataset dataframe 动态添加列
>需求 利用SparkSQL计算每一行数据的数据质量,如果数据不为NULL或者不为空字符串(或者符合正则表达式),那么该字段该行数据积一分 >网上解决方案 https://blog.csdn.net/Code_LT/article/details/87719115 https://blog.csdn ......
关于spark写clickhouse出现 too many parts(300)错误的最佳解决方式
出现这个问题的根本原因是clickhouse插入速度超过clickhouse的文件合并速度(默认300) 解决方式如下 觉得好用记得点个关注或者赞哈 ......
Spark入门
# 一、Spark框架概述 ## 1.1 spark是什么 定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。 弹性分布式数据集RDD:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。 ......
dolphinscheduler 调度spark on k8s
dolphinscheduler 对于k8s的支持可以使用spark任务模式选择k8s 配置,当然也可以直接通过k8s 集成通过容器镜像模式运行,两种方式各有利弊,但是完全基于k8s模式会比较方便些 集成玩法说明 spark 任务模式 此模式我们需要配置SPARK_HOME 给每个dolphinsc ......
Windows本地IDEA运行mapreduce报错java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
## 问题原因 在windows运行hadoopJob程序的时候需要模拟下hadoop的运行环境。否则出现会出现标题的问题。 ## 解决方案 1. 下载Hadoop的bin目录 https://github.com/s911415/apache-hadoop-3.1.3-winutils 2. 将步 ......
Spark
# SparkCore ## RDD基础 ### 定义 在 Spark 的编程接口中,每一个数据集都被表示为一个对象,称为 RDD。RDD 是 Resillient Distributed Dataset(弹性分布式数据集)的简称,是一个只读的(不可变的)、分区的(分布式的)、容错的、延迟计算的 ......
五分钟了解Spark之RDD!!
# Spark之探究RDD > 如何了解一个组件,先看看官方介绍!  进入RDD.scala,引入眼帘的是这么一段描 ......
hadoop hive hbase
公司报表是基于数仓开发的,分层是ods>dwd>dwm>dm,sqoop再同步到传统数据库,帆软展示,或tableau展示,这块涉及的是离线计算。 记录下大数据开发设计的概念: 1、hadoop:分布式计算(MapReduce)+分布式文件系统(HDFS),后者可以独立运行,前者可以选择性使用,也可 ......
大数据面试题集锦-Hadoop面试题(五)-优化
> 你准备好面试了吗?这里有一些面试中可能会问到的问题以及相对应的答案。如果你需要更多的面试经验和面试题,关注一下"张飞的猪大数据分享"吧,公众号会不定时的分享相关的知识和资料。 ## 1、MapReduce优化方法 1)数据输入 (1)合并小文件:在执行mr任务前将小文件进行合并,大量的小文件会产 ......
Spark
# 001 Spark框架 1、spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。 2、Spark VS Hadoop > 时间 Hadoop 2003(Yahoo开发)-> 2011(1.0) -> 2013(2.X) Spark 2009(伯克利大学)-> 2013(Apach ......
hadoop学习笔记
hadoop之MapReduce的学习虽然目前的框架里已经很少用到但是底层的思想还是可以借鉴。 MapReduce分为map阶段和reduce阶段,map阶段即是将数据进行搜集,reduce即是将数据进行分发,例如wordcount命令,首先将单词进行按照一定规则处理,例如分割,然后按照首字母排序, ......