Flink
flink双流join底层如何实现的
Flink是一个分布式流处理框架,它提供了丰富的操作符来处理流数据。双流(join)操作是其中一个常用的操作,用于将两个流的数据按照指定的条件进行关联。Flink的底层实现使用了一种称为“流的连接”(stream co-processing)的技术。 在Flink中,双流(join)操作通过以下步骤 ......
flink双流join时间窗口过大导致的问题
当Flink双流(join)操作的时间窗口过大时,可能会导致以下问题: 1. 内存消耗:时间窗口大小直接影响Flink系统的内存消耗。较大的时间窗口会导致需要维护更多的状态数据,从而占用更多的内存资源。 2. 延迟增加:大时间窗口可能会导致延迟增加。如果窗口的大小超过了数据流的延迟,那么在触发窗口计 ......
flink的双流join的2个流必须都是滑动窗口吗
不,Flink的双流(join)操作并不要求两个流都是滑动窗口。在双流(join)操作中,每个流可以使用不同类型的窗口,包括滑动窗口、滚动窗口或其他类型的窗口。 在Flink中,可以对每个输入流分别定义不同的窗口类型和参数,以满足实际的业务需求。只要两个流在关联键上能够匹配,并且窗口定义能够适配,就 ......
flink中的广播流实例
在Flink中,广播流(Broadcast Stream)是一种特殊的数据流类型,用于将一个数据流广播到所有并行任务中,以供每个任务共享和使用。广播流通常用于将静态数据(如维表数据)发送给所有任务,以便任务可以在本地缓存该数据,避免多次访问外部存储系统。 广播流的特点如下: - 广播流只有一个并行度 ......
flink的状态表需要保存多久
Flink的状态表保存的时间可以根据应用程序的需求进行配置。状态表的保留时间取决于两个因素: 1. **状态后端(State Backend)的配置**:Flink支持不同类型的状态后端,如内存、文件系统、RocksDB等。不同的状态后端可以配置不同的状态保留策略。例如,如果使用基于内存的状态后端, ......
flink从检查点恢复时候做什么
当发生故障时,Flink从最近的一致性检查点中恢复任务的状态。以下是从检查点恢复的主要步骤: 1. **加载检查点元数据和状态数据**:Flink首先加载最近一次成功的检查点的元数据和持久化的状态数据。检查点的元数据包含了关于检查点的信息,如检查点ID、生成时间和相关的任务信息等。持久化的状态数据包 ......
使用Redis作为维表输入的Flink示例代码
下面是一个使用Redis作为维表输入的Flink示例代码: ```java import org.apache.flink.api.common.functions.RichFlatMapFunction; import org.apache.flink.api.common.state.MapSt ......
flink的各个算子在收到barrier的时候会做什么
在Flink中,各个算子(算子链中的每个算子)在收到 barrier(检查点屏障)时会执行以下操作: 1. **算子状态快照**:算子会触发对其状态的快照操作,以捕获当前状态的一致性快照。这包括算子的运行时状态、缓冲区或累加器等数据。 2. **处理挂起输入数据**:算子会将收到的 barrier ......
flink中一个多输入的算子如何决定是否可以往下游算子发送barrier
在Flink中,多输入的算子在决定是否可以往下发 barrier 时需要满足以下条件: 1. **输入流的 barrier 对齐**:多输入的算子必须要求所有输入流都处于 barrier 对齐状态,即收到了相同的 barrier。这意味着所有输入流的上游任务都已经收到了相同的 barrier,并向下 ......
Flink CDC
# **第1章 CDC简介** ## 1.1 什么是CDC CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 ## 1 ......
Flink中的Window和Time详解
### Window(窗口) Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。 通常来讲,Window是一种可以把无界数据切割为有界数据块的手段 例如,对流中的所有元素进行计 ......
Flink核心API之Table API和SQL
### Table API & SQL 注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现Flink中所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。 Table API和SQL的由来: Flink针对标准的流处理和批处理提供了两种 ......
Flink核心API之DataSet
### DataSet API DataSet API主要可以分为3块来分析:DataSource、Transformation、Sink。 DataSource是程序的数据源输入。 Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap、filt ......
Flink核心API之DataStream
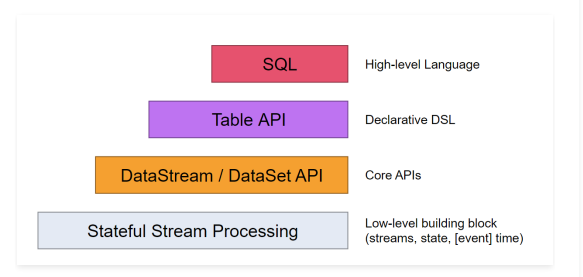 Flink中提供了4种不同层次的API,每种API在简洁和易表达之间有自己的权衡,适用于不同的场景。目前 ......
Flink安装部署
### Flink集群安装部署 Flink支持多种安装部署方式 - Standalone - ON YARN - Mesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境 ......
Flink详解
### 什么是Flink Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。 分布式:表示flink程序可以运行在很多台机器上, 高性能:表示Flink处理性能比较高 高可用:表示flink支持程序的自动重启机制。 准确的:表示flink可以保证处理数据的准确性。 Fl ......
FLink写入Clickhouse优化
一、背景 ck因为有合并文件操作,适合批量写入。如单条插入则速度太慢 二、Flink写入ck优化 改为分批插入,代码如下 DataStream<Row> stream = ... stream.addSink(JdbcSink.sink( "INSERT INTO mytable (col1, co ......
FLink怎么做压力测试和监控?
我们一般碰到的压力来自以下几个方面: 一,产生数据流的速度如果过快,而下游的算子消费不过来的话,会产生背压问题。背压的监控可以使用Flink Web UI(localhost:8081)来可视化监控,一旦报警就能知道。一般情况下背压问题的产生可能是由于sink这个操作符没有优化好,做一下优化就可以了 ......
为什么使用Flink替代Spark?
一,Flink是真正的流处理,延迟在毫秒级,Spark Streaming是微批,延迟在秒级。 二,Flink可以处理事件时间,而Spark Streaming只能处理机器时间,无法保证时间语义的正确性。 三,Flink的检查点算法比Spark Streaming更加灵活,性能更高。Spark St ......
Flink流式数据缓冲后批量写入Clickhouse
一、背景 对于clickhouse有过使用经验的开发者应该知道,ck的写入,最优应该是批量的写入。但是对于流式场景来说,每批写入的数据量都是不可控制的,如kafka,每批拉取的消息数量是不定的,flink对于每条数据流的输出,写入ck的效率会十分缓慢,所以写了一个demo,去批量入库。生产环境使用还 ......
flink安装(无hadoop)
下载Flink:访问Flink的官方网站(https://flink.apache.org/),在下载页面找到适合你操作系统的预编译二进制包。选择与你的操作系统和版本相对应的下载链接,点击下载。 解压二进制包:下载完成后,将二进制包解压到你想要安装Flink的目录中。你可以使用命令行工具(如tar命 ......
什么是flink
https://flink.apache.org/zh/ Flink(Apache Flink)是一个开源的流处理和批处理框架,旨在处理大规模的数据流和批处理任务。它提供了高效、可扩展和容错的数据处理能力,适用于各种数据处理场景。 以下是Flink的一些关键概念: 流(Stream):Flink以数 ......
Flink保留savepoint,并从savepoint启动示例
FLink1.6版本,基于Yarn集群示例: 1、启动示例: ../bin/flink run -t yarn-per-job -Dyarn.application.queue="default" -c org.apache.flink.base.basedoit._23_State_Operato ......
【Flink系列十八】History Server 重新登场,如何跟Yarn进行集成
本文介绍了Flink 1.16的 HistoryServer 集成Yarn进行日志查看的方案,详细分析了Jobmanager和TaskManager的日志链接转换的方法。仅供参考。 ......
【Flink系列十七】Flink On Yarn 的Classpath传递分析
从NoClassDefFoundError:org/apache/hadoop/mapred/MRVersion到 Flink On Yarn 的Classpath的传递过程分析。ClassNotFoundException: org.apache.hadoop.mapred.MRVersion ......
flink计算引擎
第1章 Flink简介 1.1 初识Flink 1) Flink项目的理念是:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。 2) Apache Flink是一个框架和分布式处理引擎,用于对无界(nc lk 9999)和有界数据(一个文档)流进 ......
Flink白话解析Watermark
一、摘要 如果想使用Flink,Flink的Watermark是很难绕过去的概念。本文帮大家梳理Watermark概念 二、Watermark疑问 1、Flink应用的常见需求是什么 如公司运营一个官网,想统计下过去一分钟有多少用户访问官网。一分钟可以理解为Flink的窗口,在这一分钟统计有多少用户 ......
flink之java.lang.NumberFormatException: For input string错误
场景: 使用flink读取一张hudi表,将数据写入到另外一张hudi表。 错误栈: java.lang.NumberFormatException: For input string: "test_table" at java.lang.NumberFormatException.forInput ......
flink中的Keyed State
Keyed state是指在Flink中与一个特定key相关联的状态。在Flink中,数据被分区并按key分组。当数据流被分区和分组后,每个key都有一个对应的状态,这就是Keyed state。它可以用于计算窗口、聚合操作和连续查询等。Keyed state通常用于在流处理中跟踪关键得分、计数或其 ......
flink的事件时间、摄取时间、处理时间
在Flink中,事件时间、摄取时间和处理时间是用于处理流数据的三种时间概念。这三种时间概念分别反映了不同程序处理的时间特征。下面分别介绍它们的定义及区别: 事件时间(Event Time): 事件时间是指事件在数据源端实际发生的时间,通常信息保存在事件数据的元数据或者是数据内容中。事件时间允许Fli ......