Hongjun Choi, Eun Som Jeon, Ankita Shukla, Pavan Turaga; Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 2319-2328
WACV 2023,亚利桑那州立大学
这篇文章以“smoothness”为纽带分析了mixup与KD各个层面的兼容性。没有引入特别的结构和数学证明
mixup和KD都涉及到label smoothing的操作,KD是student模仿teacher的soft label,而mixDA是通过线性组合label人为引入“smoothness”。对于KD,较高的蒸馏温度一方面带来更为丰富的信息,另一方面却削弱了supervision的强度(蒸馏温度升高相当于抹匀了概率)。
Introduction
为了研究mixup和KD如何改变每个类间的feature representation,作者从CIFAR100数据集中选出五个class (baby, boy, girl, man, and woman),进行(或不进行)mixup操作后,扔进ResNet110(或ResNet56)训练,之后再在不同温度下进行蒸馏。然后作者把ResNet倒数第二层的feature用t-sne降维到二维进行可视化操作,如figure 1所示。
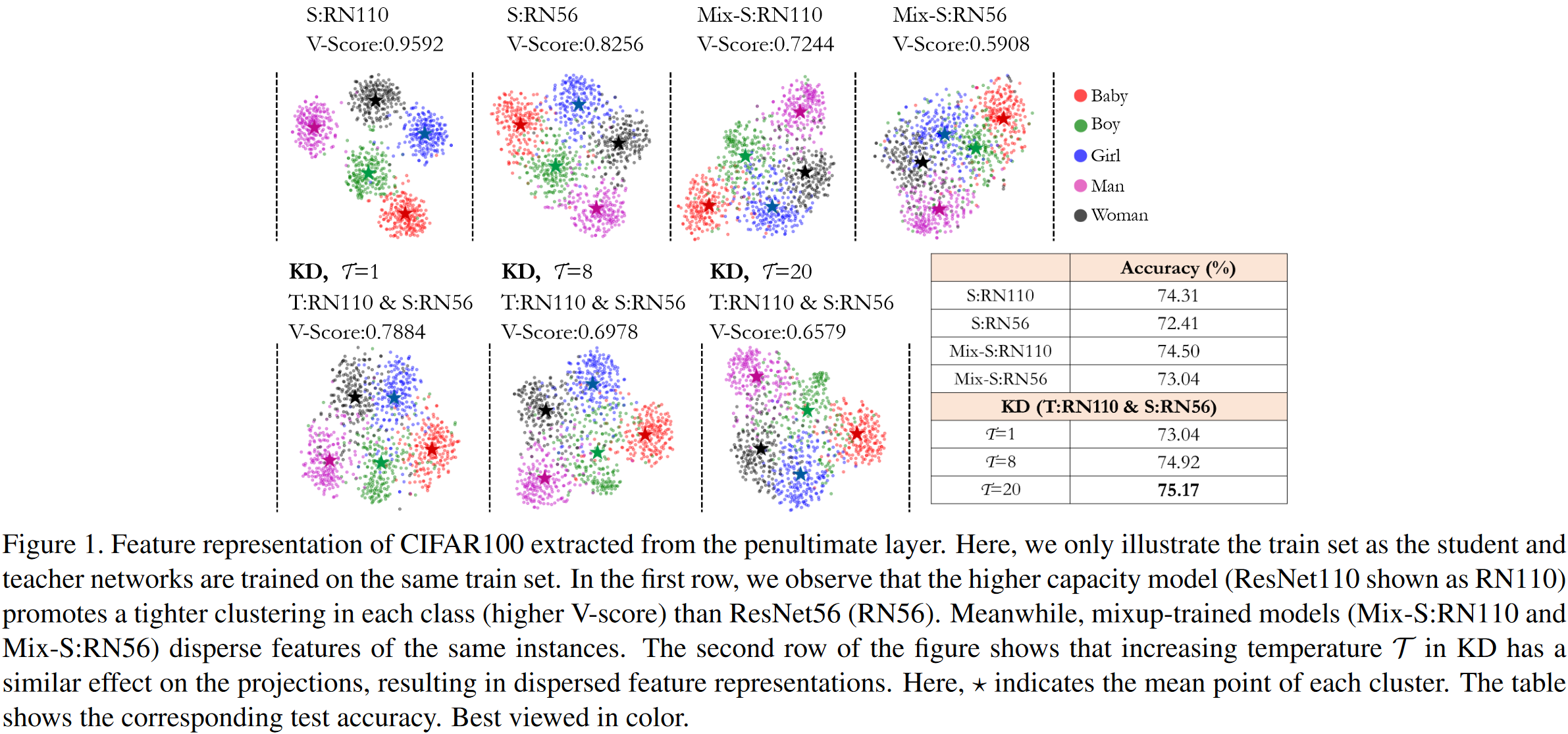
作者用V-Score表征聚类的效果,发现mixup会导致feature更加分散,聚类效果变差,但是同时也增强了模型的泛化性能和再测试集上的表现。同时也注意到,较高温度的蒸馏也会导致feature的分散,但也可以一定程度上提高泛化性能
因此作者在寻求一种思路,希望可以不影响学生泛化性能的同时,增强教师网络的监督信号,使得feature聚类效果不那么松散
因此,作者设想,如果teacher使用mixup平滑后的数据训练,其产生的logit会更加自然,不需要较高温度来蒸馏,因此保证了stronger supervisory signals,且同时可以享受到soft label带来的更多信息。
Mixup and KD interplay
作者在本节通过实验详细观察了mixup和KD相互作用的情况,探究了为什么直接对教师mixup会减弱KD的效果
首先用对照试验描述了如下图的四种情况,并且在不同的网络上进行了实验。

可以直接观察到的是:
- 经过mixup正则的教师网络的性能比直接训练的标准教师要强,但是蒸馏出的学生却不如未经mixup的标准教师蒸馏出的学生好。
- 复杂的教师训练出的学生性能更好,即使较简单的教师,训练出的学生也比不蒸馏要好
作者将在本节探究为什么mixup的教师会损害KD效果,然后在下一节提出解决思路
为了更加详细地探究效果,作者在CIFAR100上选取了一些类,并且这些类可以被分成两组,语义差异较大的类(海狸、苹果、水族鱼、火箭和乌龟)和 语义相似的类(婴儿、男孩、女孩、男人和女人),然后作者像之前一样进行了特征可视化,计算聚类程度指标V-Score和准确度,结果如下图3,可以观察到:
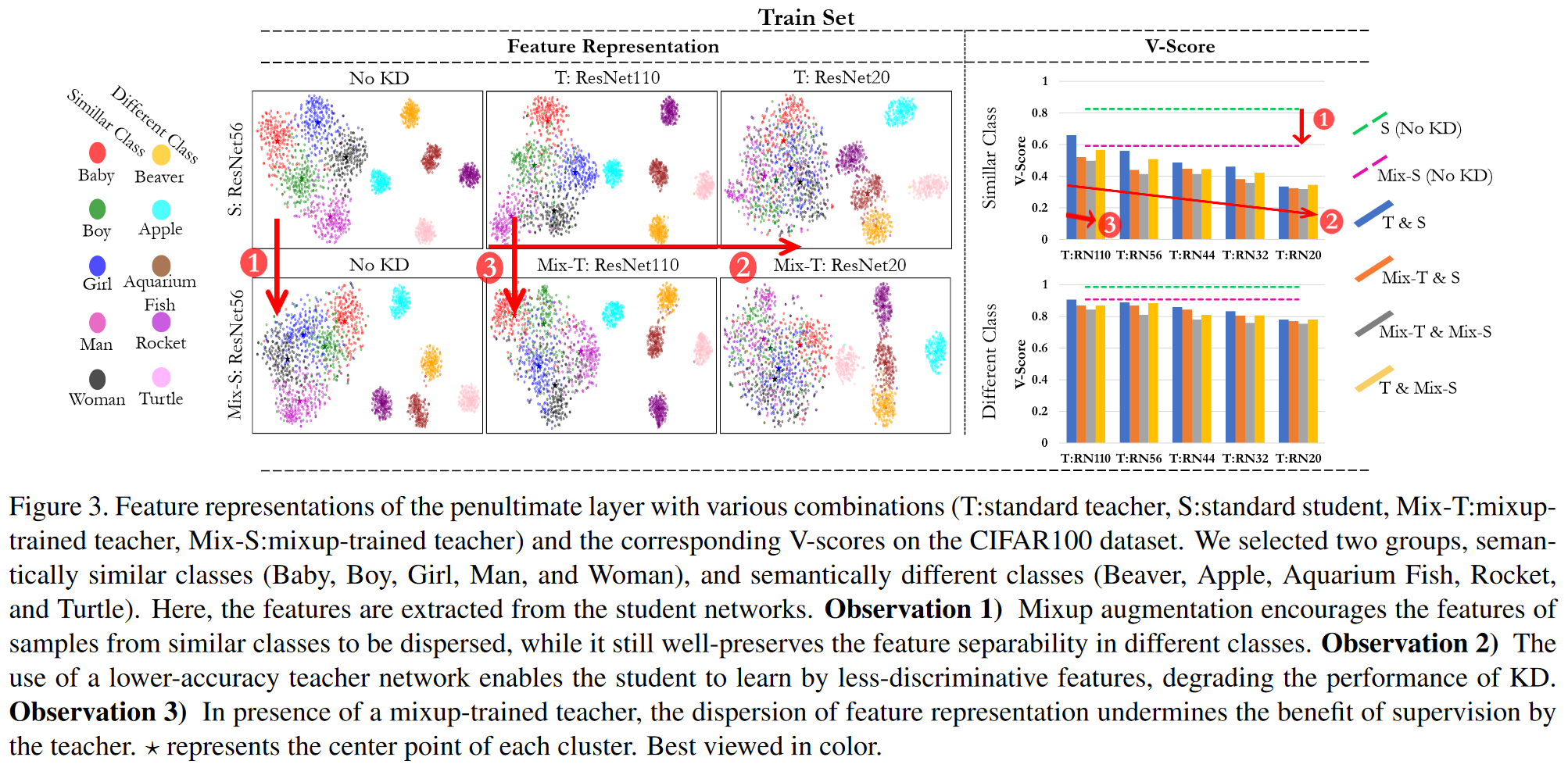
- mix与原始数据直接训练:如图中红圈1所示,经过mixup后特征聚类明显更加分散,不过还基本保持原结构
- 低准确度教师:如红圈2所示,准确度低的教师明显特征更分散,导致学生效果明显下降。这意味着更好的学生是在高能力教师在给予可识别的特征的帮助下提炼出的
- mix训练下的教师的蒸馏:会发现很重要的点,就是mix训练后的教师进行蒸馏会导致同一类的特征过于分散,然后相似语义的类混在一起。因此学生难以更好学习知识。(我感觉可以理解为原先清晰的界限模糊了,所以一下子准确率就下来了)
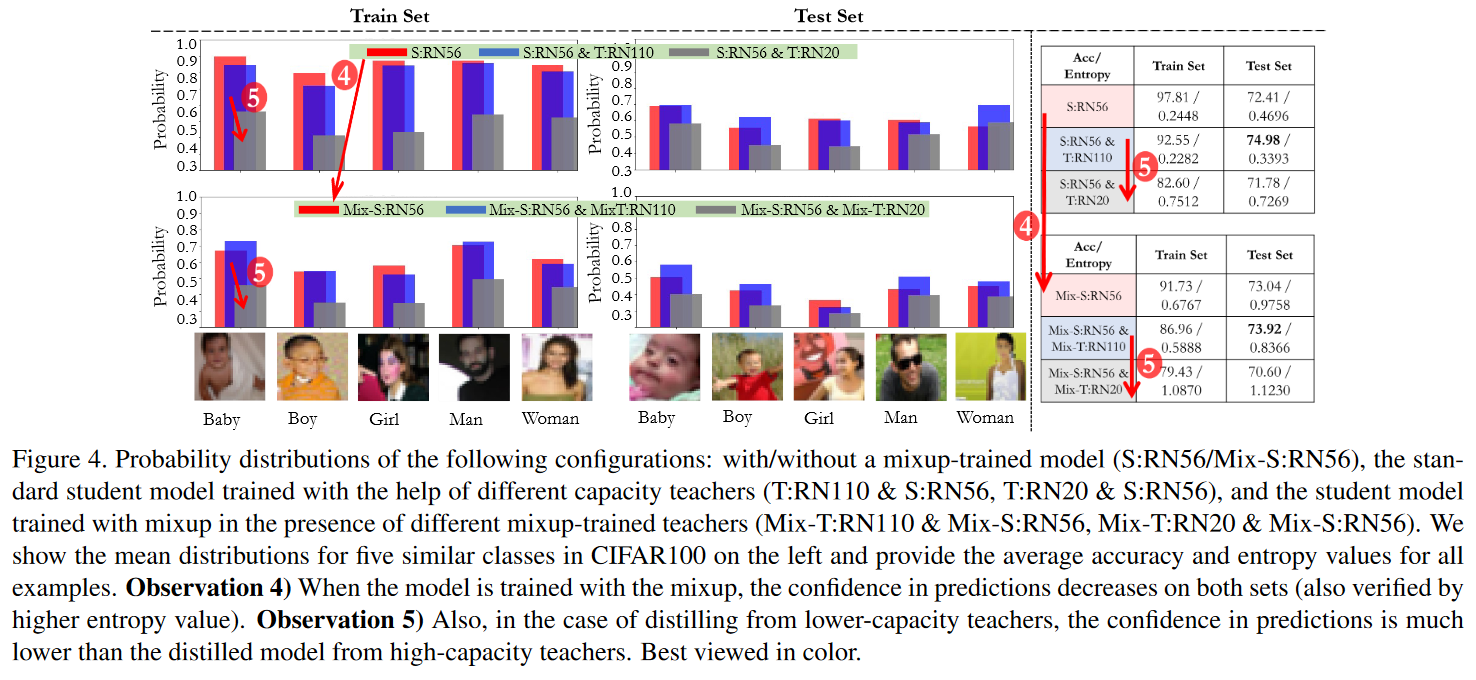
- mix后的教师同样温度下会产生更软更平滑的logit(这里作者用logit的熵来表征其分布的平滑性),较高温度会使其过于平滑,导致mix后的教师效果变差
- 低准确度教师产生的劣质信息传递给学生会导致学生的准确度显著降低,这意味着良好正确的knowledge是关键
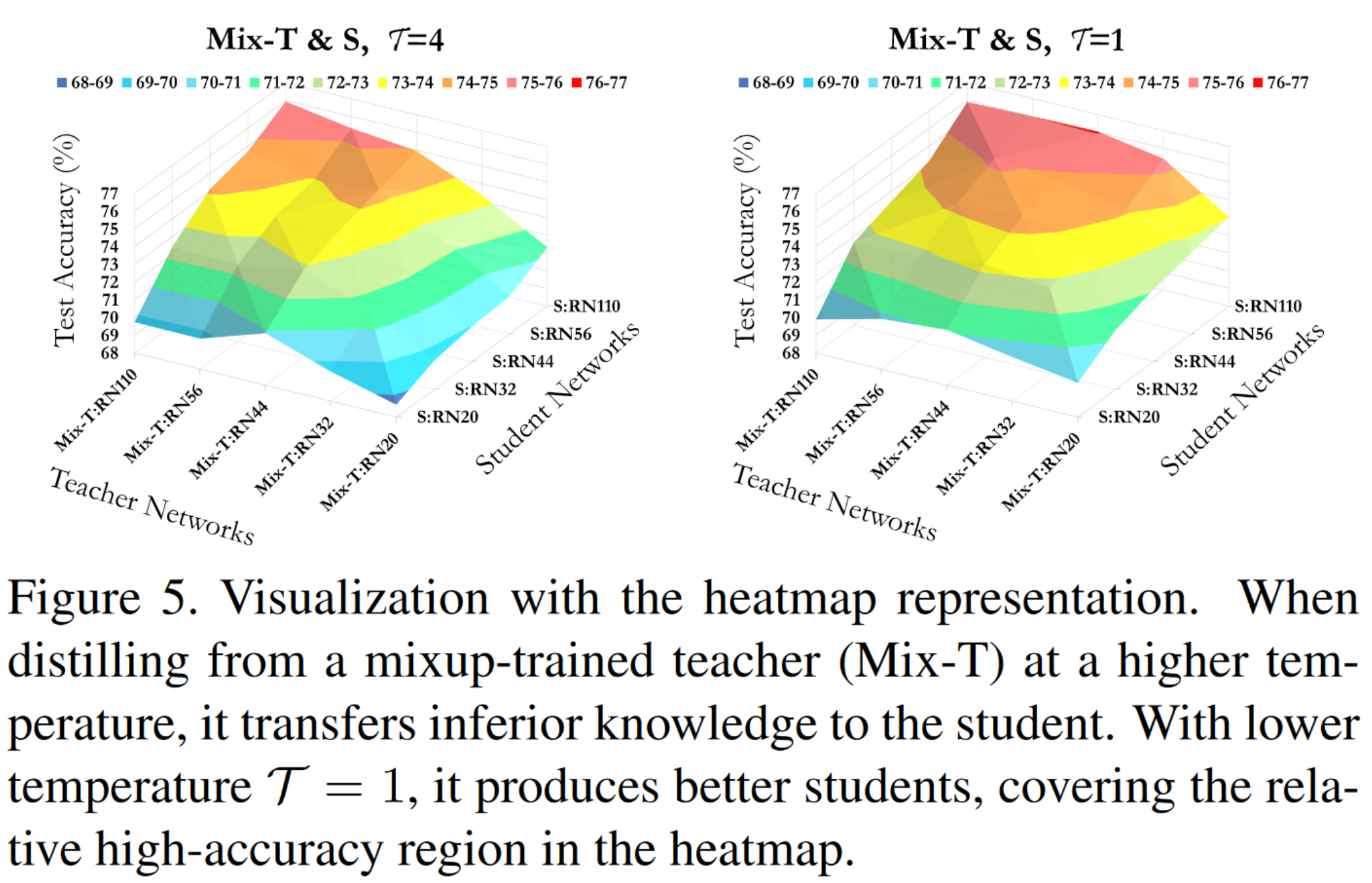
- 根据观察4,作者思考,如果温度降低,是否可以让蒸馏的知识质量变好呢?如上图图5,不难发现,低温可以让mix后的教师的logit不过于平滑,从而提高蒸馏的知识的质量。
Effective learning strategies for Mix-KD
由上面的分析,我们已经可以理解,这是一个有关平滑性的trade-off了。过于平滑,可能意味着混在一起不易分辨的特征影响知识的质量,而过低的温度则可能会导致提供的类内和类间信息不足。
Partial mixup
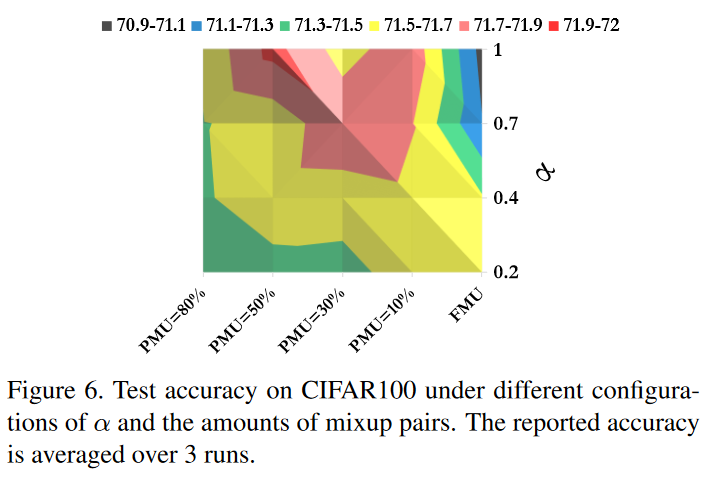
就是不全部采用mixup,每个batch只采用一部分的mixup数据,mixup数据占比被称为PMU
Rescaled logits
这里作者建议采用logit的标准差作为参数,这样可以对logit进行合理的缩放,约束老师和学生两者的统计特征达到相近的范围,并且这样一来蒸馏温度就不是超参数了
更具体一些,之所以这样做是因为由于混合 \(\lambda\) 随机取的原因,不同输入的logit分布的统计量可能差异极大。修改损失函数为:
其中 \(\tilde{f}=f / \sigma(f)\) ,S表示softmax,KL使KL散度, \(\sigma(\cdot)\) 是输入logit的标准差。学生最终蒸馏的目标是:
下面是作者修改不同超参数的的打表
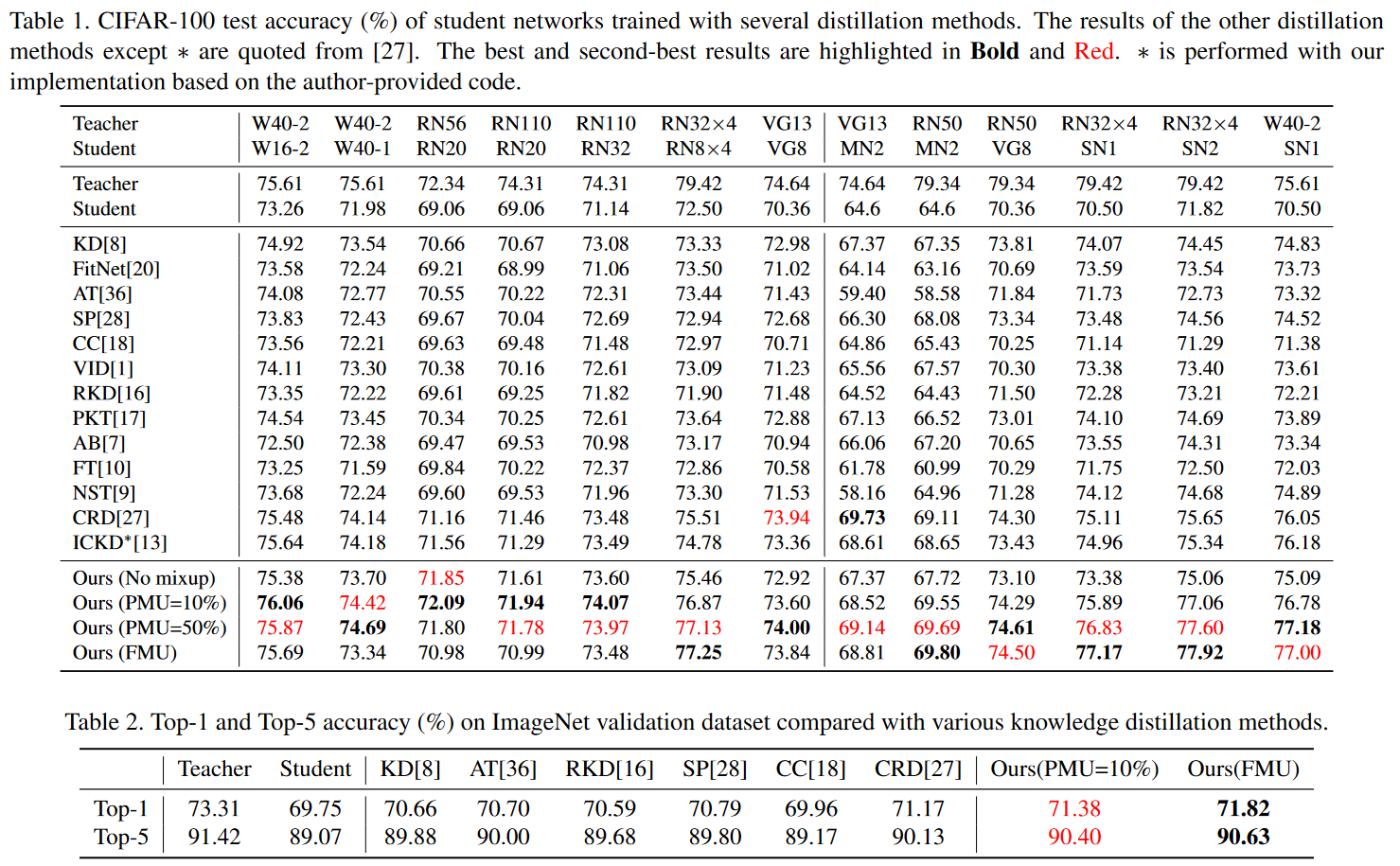
Experiments
Conclusions
各种基于混合的增强已经证明了它们对特定任务的有效性。然而,这些增强可能会产生不合理的训练样本,因为它混合了随机图像,这可能会扭曲类别之间合理的相对结构。因此,这可能会在蒸馏过程中对logit产生不利的平滑影响。因此,开发一种能够自动选择更合理的参数,保证最佳拟合平滑度的增强方法,将进一步推动精馏领域的进展。
- Understanding Distillation Knowledge Empirical 文献understanding distillation knowledge empirical distillation relational knowledge distillation innovative knowledge landscape distillation recommender knowledge framework distillation target-aware transformer knowledge distillation knowledge stronger teacher distillation unsupervised adaptation knowledge distillation decoupled knowledge recommendation distillation knowledge unbiased empirical