论文信息
论文标题:Improved Baselines with Momentum Contrastive Learning
论文作者:Xinlei Chen, Saining Xie, Kaiming He
论文来源:2021 ICCV
论文地址:download
论文代码:download
引用次数:656
1 介绍
重点是将目前无监督学习最常用的对比学习应用在 ViT 上。
结论:影响自监督 ViT 模型训练的关键是:训练的不稳定性。这种训练的不稳定性所造成的结果并不是训练过程无法收敛 ,而是性能的轻微下降 (下降1%-3%的精度)。
2 方法
整体框架:
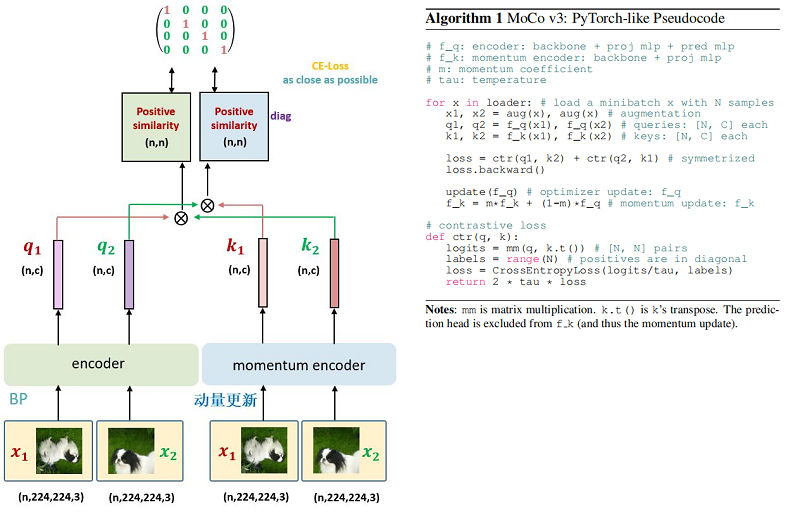
特点:
-
- 取消了 Memory Queue 的机制,即 MoCov3 的负样本都来自一个 Batch 的图片,所以只有当 Batch size 足够大时,模型才能看到足够的负样本。【4096】
- Encoder $f_{\mathrm{q}}$ 除了 Backbone 和预测头 Projection head 以外,还添加了个 Prediction head;
- 对于同一张图片的 2 个增强版本 $x_{1}$, $x_{2}$ ,分别通过 Encoder $f_{\mathrm{q}}$ 和 MomentumEncoder $f_{\mathrm{Mk}}$ 得到 $q_{1}$, $q_{2}$ 和 $k_{1}$, $k_{2}$ 。让 $(q_{1}, k_{2})$ 和 $(q_{2}, k_{1})$ 通过 Contrastive loss 进行优化 Encoder $f_{\mathrm{q}}$ 的参数,Momentum Encoder $f_{\mathrm{Mk}}$ 进行动量更新;
- Self-Supervised Transformers Supervised Empirical Trainingself-supervised transformers supervised empirical self-supervised transformers lightweight supervised self-supervised self-supervised exploration generative supervised self-supervised interpretable adversarial generative self-supervised bidirectional supervised learning language-guided self-supervised segmentation self-supervised recommendation session-based self-supervised recommendation convolutional self-supervised quantization augmentation randomized